全角と半角を変換する(2)
私のセミナーを何度も受講されていた常連の方から、久しぶりに連絡をもらいました。「『セルに入力したカタカナをひらがなに変換する(2)』を読みました!実務でやりたかったことなので、さっそく試してみます。ところで『全角と半角を変換する』なんですけど、こちらもだいぶ古いですよね。これって、今だったら"半角カタカナ"だけ"全角カタカナ"に変換するとかって可能ですか?可能なら、ぜひ教えてください!」というような内容でした。確かにだいぶ昔ですが書きました。ちょっと確認のためにページを開きましたが、なんと画像がExcel 2003じゃないですかw たぶん、20年近く前の解説ですね。関数で"全変換"するやり方をご紹介して「カタカナだけとか数値だけなど特定の文字種を変換するときはマクロでやってください」ということでした。確かに、その時代でしたら、関数で「半角カタカナだけを全角カタカナにする」って、できませんでしたね。はい、もちろん今なら可能です。考え方は「セルに入力したカタカナをひらがなに変換する(2)」と、だいたい同じでしょう。楽勝ですね。パパッと書いちゃいます。そうだ、これが終わったら、久しぶりで一杯飲みに行こう…。
JIS関数とASC関数
まずは基本のおさらいです。半角の"カタカナ"・"アルファベット"・"数字"・"記号"を、全角へ変換するにはJIS関数[*1(下記参照)]を使います。逆に、全角を半角に変換するときはASC関数です。ASC関数の"ASC"はASCII(アスキー)の略なので、一般的に"アスク関数"とか"アスキー関数"と呼ばれています。
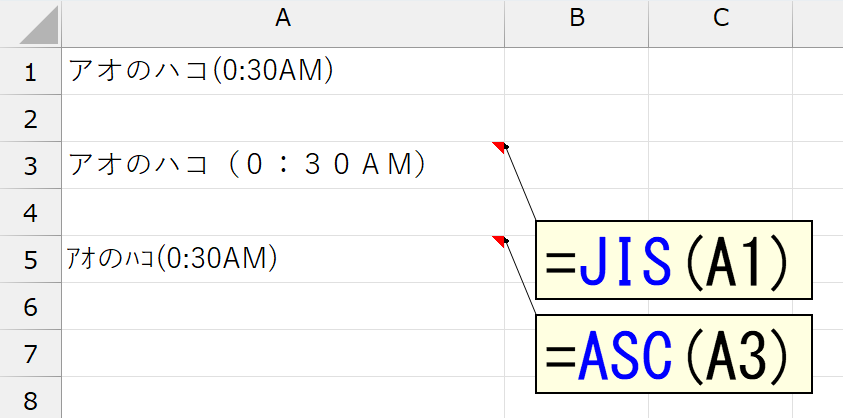
セルA1には、全角の"カタカナ"と、半角の"数字"と"アルファベット"と"記号"を入力しています。JIS関数とASC関数は、このように"カタカナ"・"アルファベット"・"数字"・"記号"をすべて変換します。"半角のカタカナ"だけとか"全角の数字"だけを変換することはできません。
半角のカタカナだけ全角にする
まずは「セルに入力したカタカナをひらがなに変換する(2)」と同じやり方でいきましょう。
- セル内の文字列を、左から1文字ずつ抽出します
- もし、その文字が「半角カタカナだったら」全角カタカナに変換します
- 「半角カタカナではなかったら」そのまま、それまでの文字列に結合します
では、さっそく文字コードを調べ…る必要はありません。だって"半角→全角"の変換って、JIS関数で一発ですから。
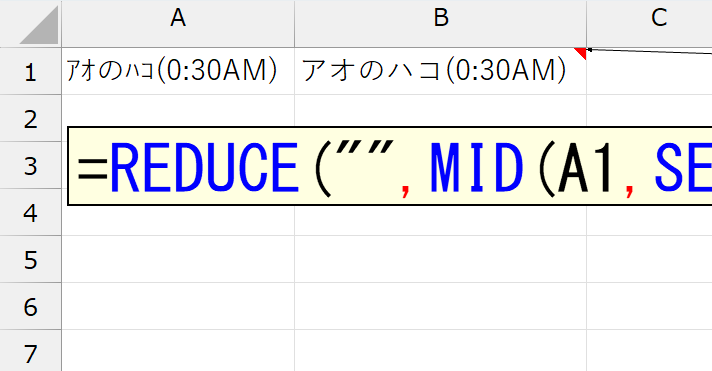

=REDUCE("",MID(A1,SEQUENCE(LEN(A1)),1),LAMBDA(a,b,IF(REGEXTEST(b,"[ア-ン]"),a&JIS(b),a&b)))
「セルに入力したカタカナをひらがなに変換する(2)」と違う部分だけ解説します。IF関数の条件は正規表現を使っています。判定しているパターンは"[ア-ン]"です。半角カタカナで指定します。この条件がTRUEになったら、その文字をJIS関数で全角に変換します。
さて、こんなもんかな。まぁ、一応ほかのデータでも確認してみますか。

ん?あれ?
2つの間違い
この発想には、2つの間違いがあります。ひとつめは、正規表現に指定したパターンです。私は安易に「すべての半角カタカナは"ア"から"ン"の間に含まれる」と思い込んでいましたけど、よく調べたら、そんなことはありませんでした。

半角カタカナは、161の"。"から始まっていました。最後も"ン"ではなかったです。

半角の濁点と半濁点は、"ン"よりも後ろに登録されています。なので、正しいパターンは"[。-゚]"です。まるで今の私を表す顔文字のように見えてきます。
さて、問題はふたつめの間違いです。こちらが致命的でした。そもそも、半角のカタカナと全角のカタカナでは、文字数が異なります。
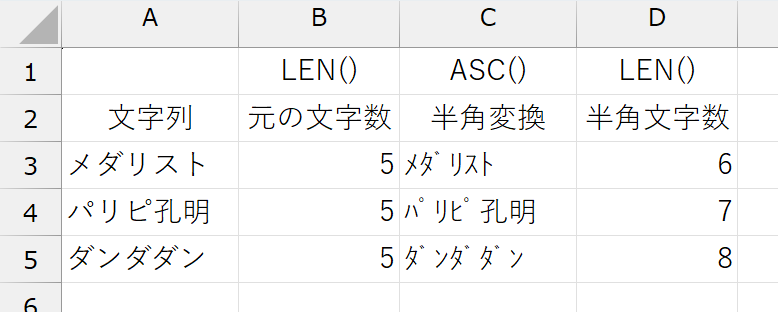
半角のカタカナでは、濁点や半濁点も1文字としてカウントされます。変換前と変換後の文字数が異なるのですから「1文字ずつ調べて、1文字ずつ変換する」作戦は使えません。ここは、方針を変えましょう。正規表現を使って"半角カタカナのかたまり"をまとめて抽出します。いや、それだけでは足りません。「アオのハコ」のように、複数の"かたまり"が存在するかもしれません。それら、複数(あるかもしれない)の"かたまり"を、LAMBDA関数に配列として渡さなければなりません。その配列を、どうやって作るのか。VBAだったら、動的配列を使って、1つずつ格納してやればどうとでもなりますが、関数ですからね~何か配列として返してくれる奴は、いないでしょうか。
見つけました。正規表現のREGEXEXTRACT関数です。REGEXEXTRACT関数についての詳しい解説は、下記のページをご覧ください。
解説ページの真ん中あたり、3番目の引数「モード」についての解説で、引数に「1.一致したすべて」を指定すると、マッチしたすべての結果が配列として返ると書いてあります(まぁ、私が書いたんですがw)。これを使えばいけそうです。数式は次のようになります。
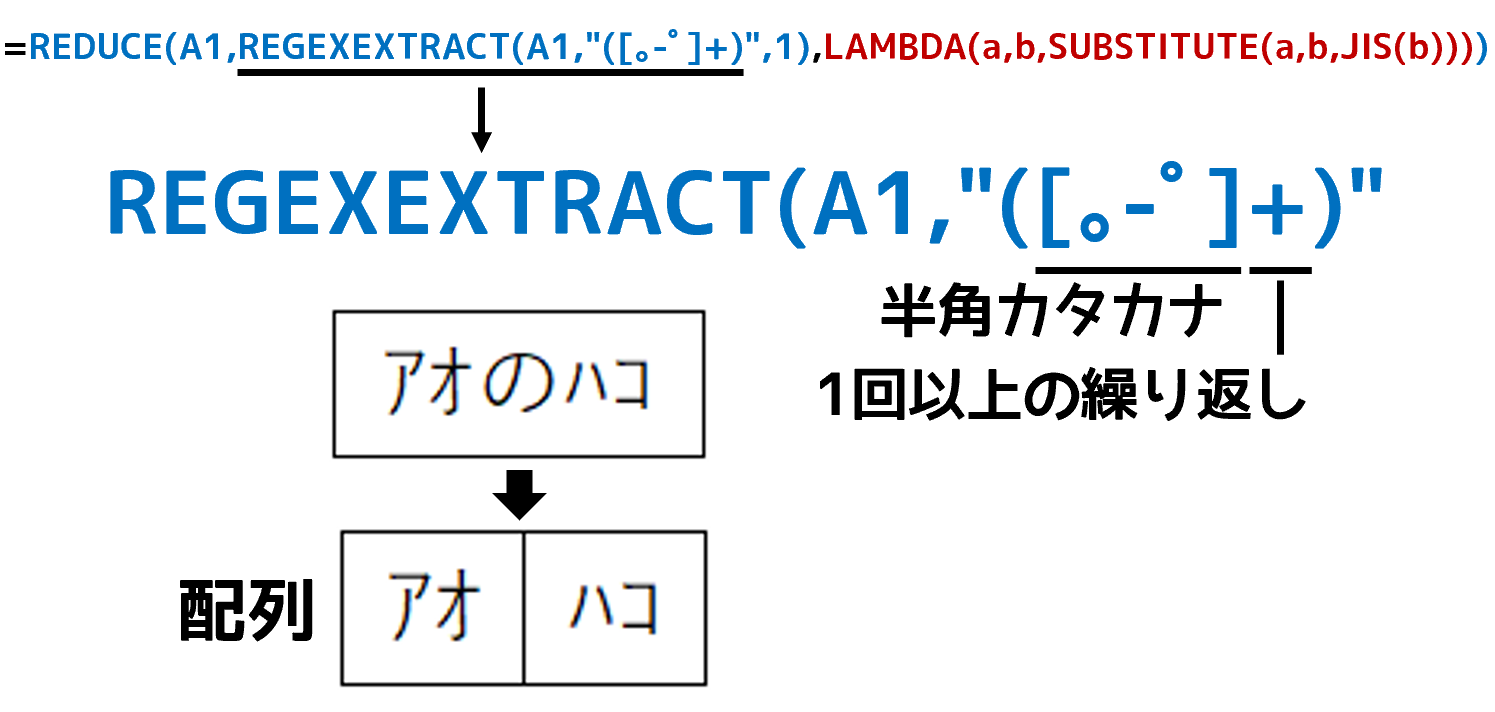
正規表現のパターンに指定した"[。-゚]"は、上述のように"すべての半角カタカナ"を表します。続けて指定している"+"は「直前のパターンが1回以上出現する」という意味です。つまり「半角カタカナが1文字以上連続している"かたまり"」です。それらが、すべて配列として返されます。REGEXEXTRACT関数の、パターンの次に指定した「1」がモードです。
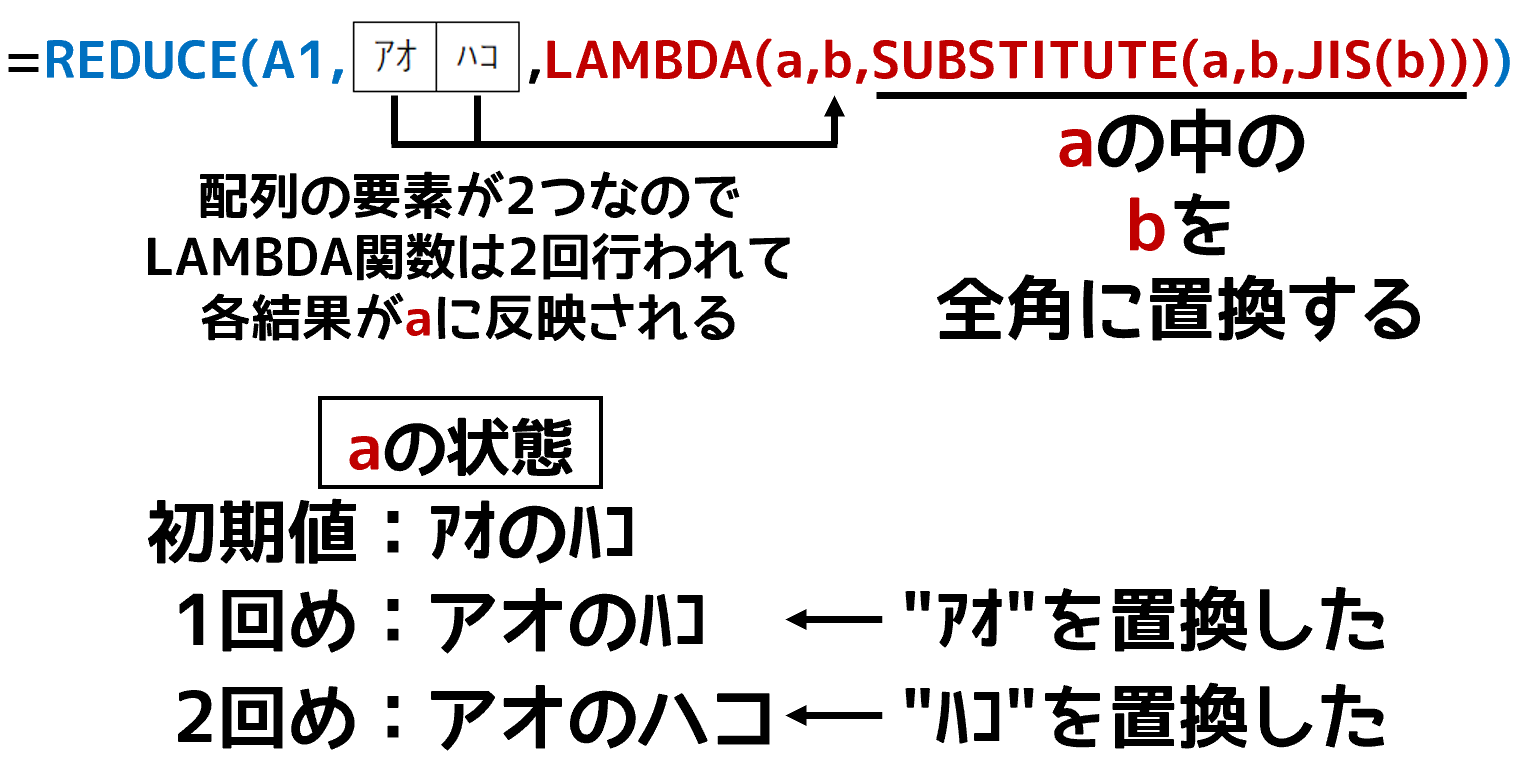
REGEXEXTRACT関数の結果は{"アオ";"ハコ"}という、2つの要素を持つ配列です。この各要素が、1つずつLAMBDA関数の引数bに渡されます。LAMBDA関数は、受け取った引数b(これは半角カタカナの"かたまり")をJIS関数で全角カタカナに変換します。そして、ここがLAMBDA関数の最も難しい(イメージしづらい)ところですが、LAMBDA関数の引数aには、初期値として「"アオのハコ"」という文字列が渡されます。ここからスタートです。LAMBDA関数が行うのはSUBSTITUTE関数です。SUBSTITUTE関数は「SUBSTITUTE(文字列,"A","B"」のように指定すると、文字列内の"A"を"B"に置換します。初期状態の引数aは「"アオのハコ"」です。1回めのSUBSTITUTE関数によって、"アオ"が"アオ"に置換されます。そして、2回めのSUBSTITUTE関数が、もうひとつの"ハコ"を"ハコ"に置換します。最終的に、引数aは「アオのハコ」になります。すべての処理(LAMBDA関数の2回の処理)が終わると、REDUCE関数は処理の最終結果を返します。この「最終結果を返す」というのも超難しいと思いますけど、ここは"そういうもの"と思い込むしかないです。そういう奴(関数)なんです。

数式をコピーされる方は、こちらをどうぞ。
=REDUCE(A1,REGEXEXTRACT(A1,"([。-゚]+)",1),LAMBDA(a,b,SUBSTITUTE(a,b,JIS(b))))
いやはや、簡単に終わると甘く見ていたら、とんでもなかったですね。そういえば本稿の冒頭で「俺、これが終わったら美味い酒を飲みに行くんだ…」なんて、フラグを立てたのが失敗でした。もしかすると"フラッガーシステム"が稼働していたのかもしれません(知らんけど)。
補足
(*1)本筋とは関係ない、いわば"よもやま話"です。今回使ったJIS関数ですが、関数名の"JIS"って、たぶん"日本工業規格"のJISですよね。ああ、最近になって"日本産業規格"と名称が変わったようですが。文字コードの"JISコード"も、正しくは"JIS漢字コード"といいますし、文字の並べ替え基準なども、JISで決められています。興味のある方は「JIS X 4061」でググってください。そういえば、90年代の、確かExcel 97で「Excelで"記号を含む文字列"を並べ替えたときの結果が以前と異なる」という問題で盛り上がりました。当時はインターネットなどありませんでしたから、マイクロソフトの知人に直接聞いてみました。そしたら「JISの並べ替え基準が変わったんですよ…」とのこと。つまり、JISのルールに合わせてExcelを変更したんです。まぁ、この時代は、日本ってけっこう影響力ありましたからね。無視できなかったのでしょう。いずれにしても、JIS関数の"J"は"Japan"の"J"だと思われます。
さらに、このJIS関数ってのは変わり種で、英語版Excelには存在しません。その代わりに、英語版ExcelにはDBCS関数というのがあります。この"DBCS"は、おそらく"Double-Byte Character Set"の意味でしょう。"ダブルバイト"つまり、日本語で言うところの"全角"ですね。これに変換する関数がDBCS関数です。なお、このDBCS関数は、日本語版Excelでは使用できません。
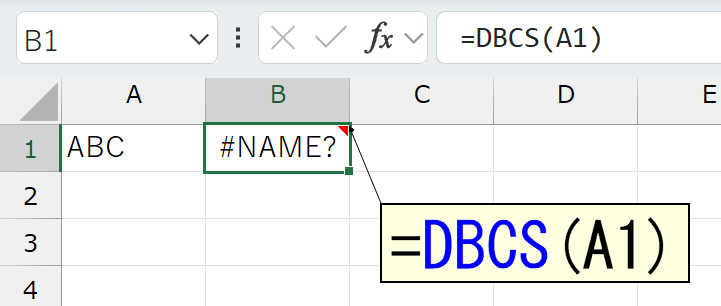
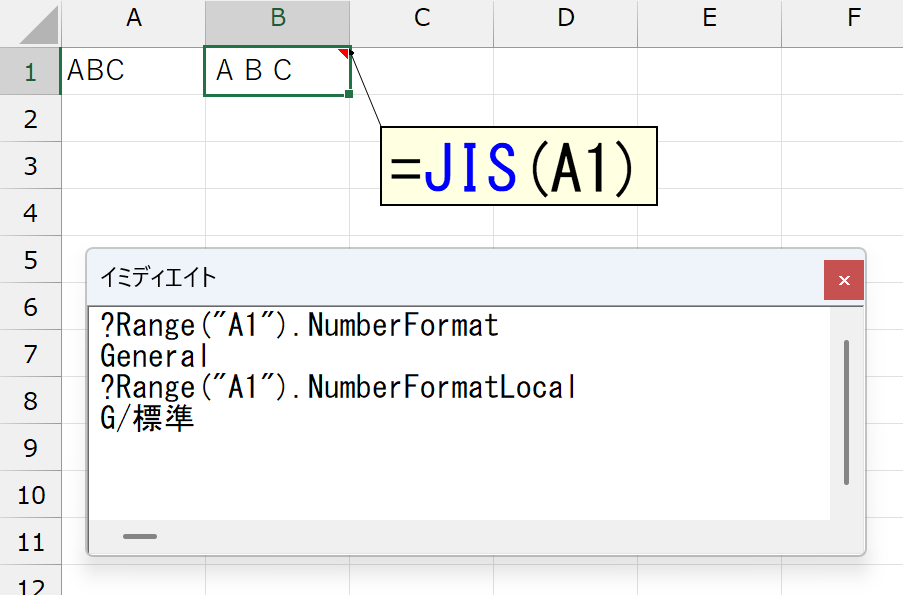
使用はできないんですけど、昔からちょっと気になっていることがあります。日本語版Excelで、JIS関数を入力したセルのFormulaプロパティを調べると、なぜかDBCS関数が返るんです。
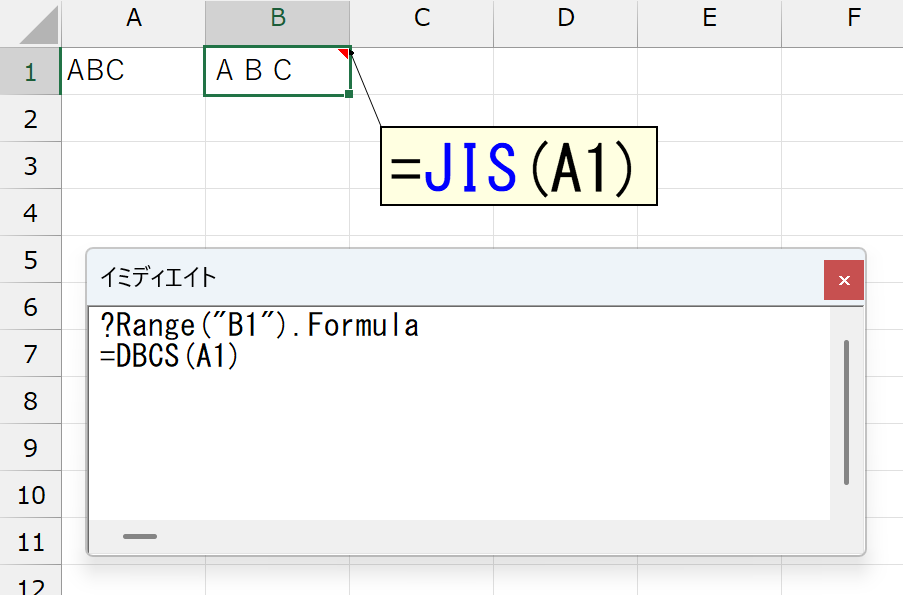
実際に入力されているJIS関数を調べるには、FormulaLocalプロパティを使います。
この、○○Localプロパティというのは、使用しているExcelの"国固有の情報"を返すプロパティです。有名なところでは、NumberFormatプロパティとNumberFormatLocalプロパティがあります。
このへんの事情って、あまり詳しく公開されていないんですけど、何となく私的には、内部でDBCS関数が動いているようなイメージがあります。先ほどから、"日本語版Excel"とか"英語版Excel"などと言っていますが、厳密には、世界中の言語ごとに複数のExcelが存在するわけではありません。昔はそうでした。だから、まず英語版Excelが作られて、日本語版Excelの発売は数ヶ月あと、なんてのが普通でした。今は違いますよね。そんな非効率的なことはやっていません。元となるExcelを作り、そこに"言語パック"を指定することで、各国版として対応させています。もちろん、"言語パック"は見た目を変えるだけではなく、たとえばDBCS関数を使えなくするなど、機能的な部分も制御しているのでしょう。いわば、元のExcelに、各国の事情をラッピングしたようなイメージでしょうか。なので、ラッピング越しにはJIS関数を使っているのですが、内部の"元のExcel"では、DBCS関数が働いているのではないかな~と。もちろん、私の個人的なイメージです。根拠はありません。
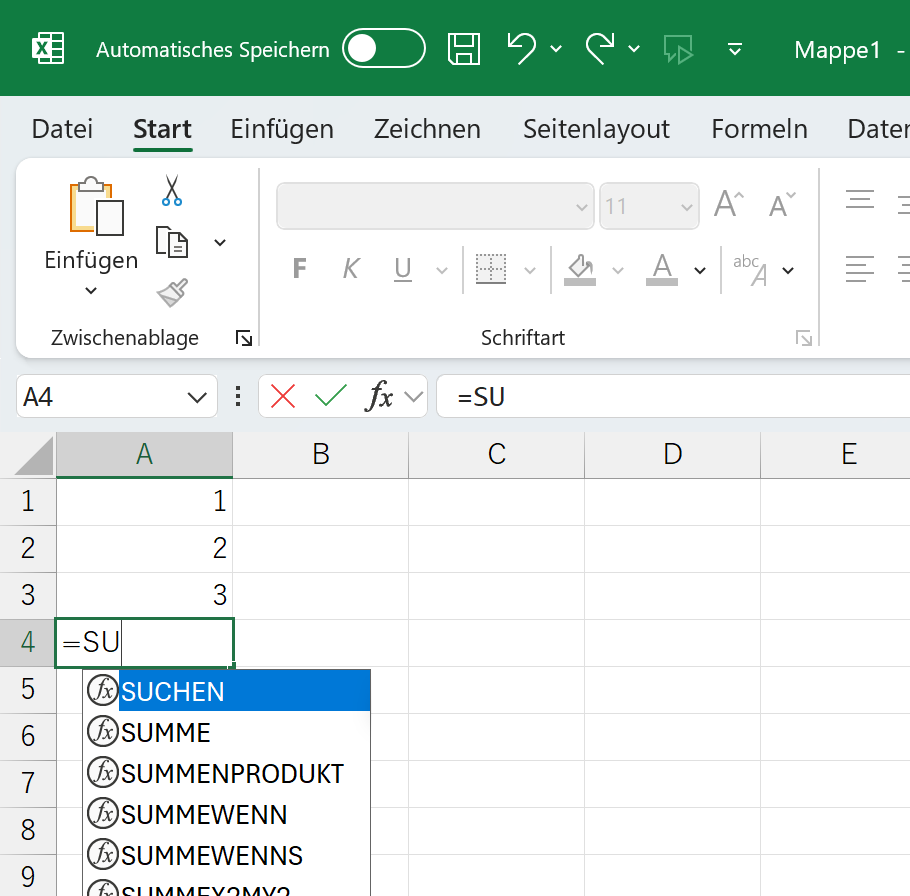
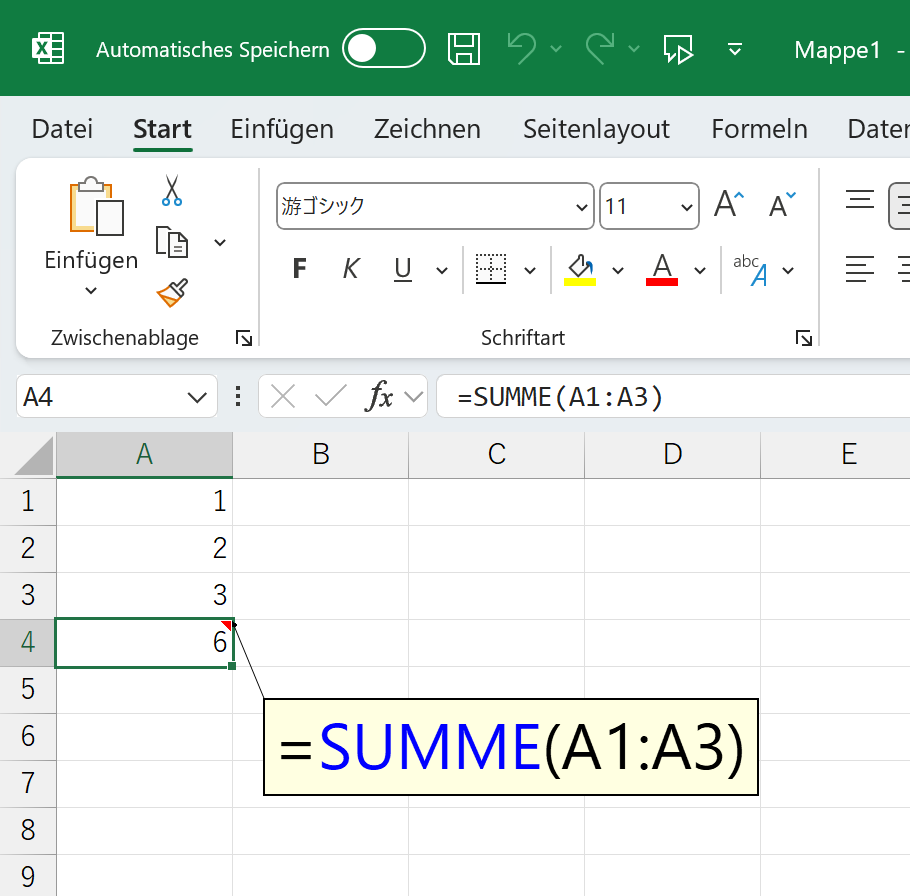
ここで疑問が生じました。「じゃ、日本のように"全角"を使う国、たとえば"中国語版Excel"って、どうなってんだろ?」中国語版Excelに、JIS関数は存在しているのでしょうか。ご存じない方が多いのですけど、Excelの関数って、世界共通ではありません。国ごとに違うんです。たとえば、ドイツ語版Excelには、SUM関数がありません。代わりに、数値を合計するSUMME関数が搭載されています。
中国語版Excelにだって、きっと"半角(1バイト)文字"を"全角(2バイト)文字"に変換する関数が装備されているはずです。その名前は、いったい何関数なのでしょう。試してみました。
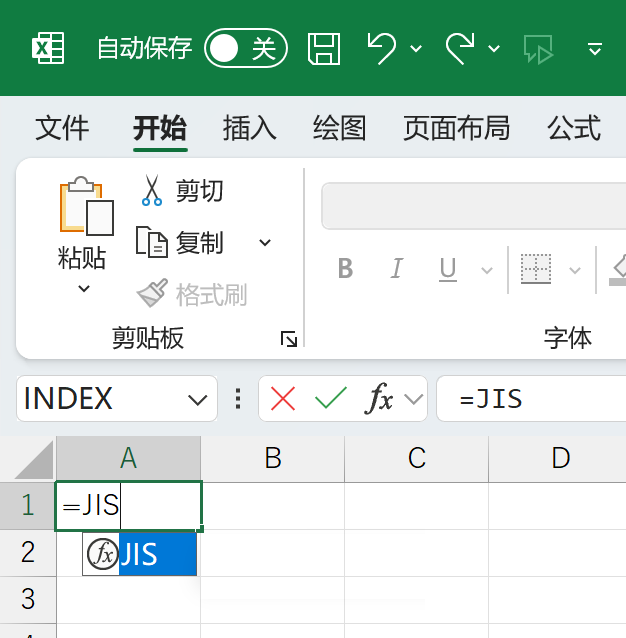
JIS関数ありましたw いやいや、おかしいでしょ。JIS関数の"J"って、どう考えても"Jpan"の"J"でしょ。中国の方々は、これを受け入れているのでしょうか。てか、日本のJISが決めたルールで中国語を並べ替えているのでしょうか。何か、変な感覚なので、英語版Excelも試してみました。ネットなどを見ると、たいていDBCS関数の解説に「DBCS関数は、英語版Excelでのみ使用可能です」と書かれています。
英語版Excelに、DBCS関数はありません。その代わりに
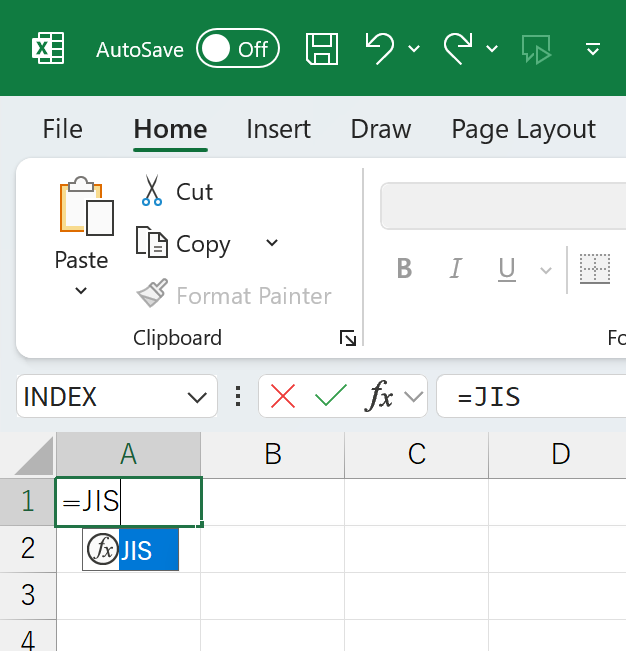
JIS関数がありましたw これは、ちょっと変です。もしかすると、"言語パック"を切り替えるだけでなく、Windowsから変えなければいけないのかもしれません。それはもう、面倒なのでやめておきます。
いずれにしても、JIS関数って、なんか扱いが変わってるよな~って、昔から感じていました。謎は深まるばかりですが、こんなこと解明しても、あまり得にはなりそうもないですね。謎のまま、これからもExcelと付き合っていくことにしましょう。