セルに入力したカタカナをひらがなに変換する(2)
「昔のExcelでは無理だったけど、今のExcelなら可能だよな~」シリーズです。なお、このシリーズは単発で終わる場合がありますので、あらかじめご了承ください。
さて、当サイトには「入力したカタカナをひらがなに変換する」という解説があります。簡単に書きますが、次のようにします。
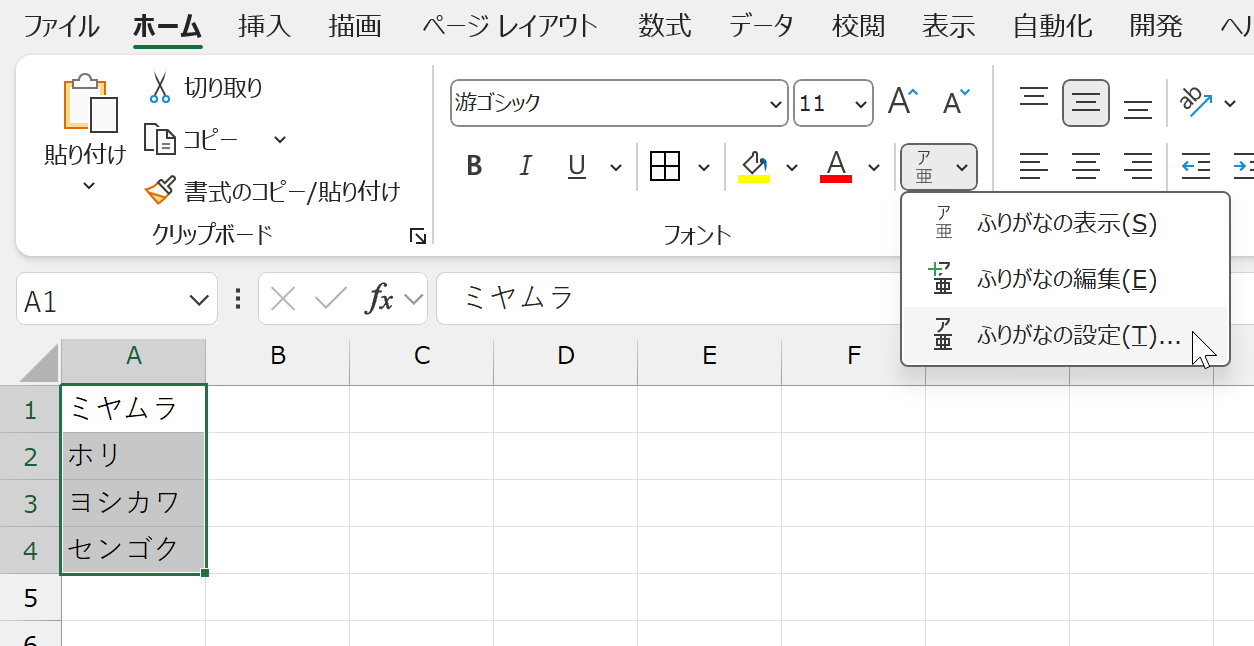
カタカナが入力されているセルを選択して、[ホーム]タブ-[フォント]グループ-[ふりがなの表示/非表示]ボタンの▼をクリックして、[ふりがなの設定]を実行します。
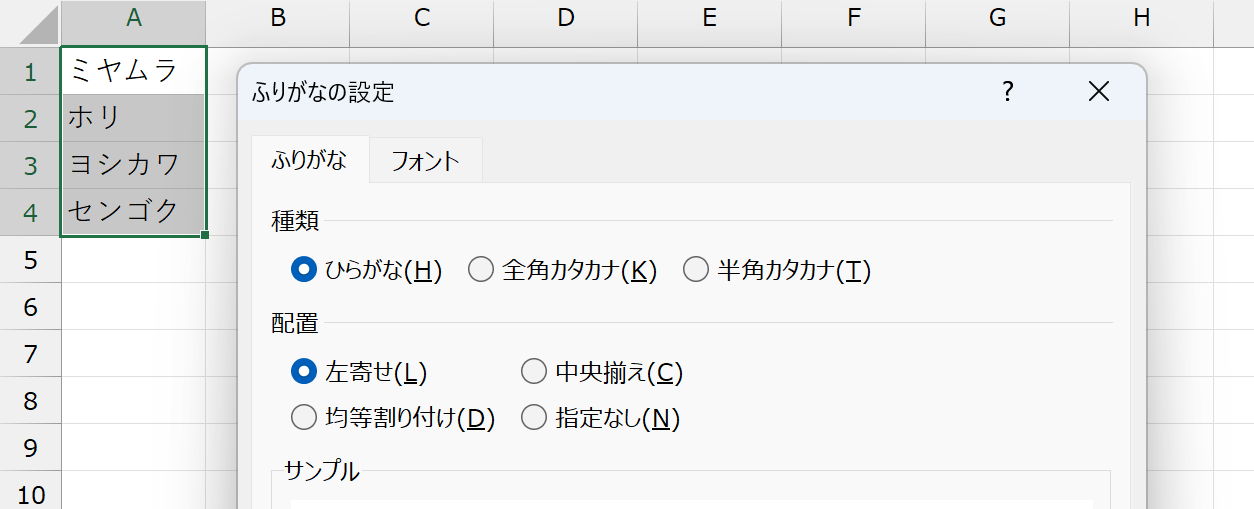
表示される[ふりがなの設定]ダイアログボックスで、[種類]に「ひらがな」を選択して[OK]ボタンをクリックします。

ひらがなに変換したいセルに「=PHONETIC(A1)」のような数式を入力します。PHONETIC関数は、指定したセル(に入力されている文字)の"ふりがな"を返す関数です。
ただし、この方法には制限があります。PHONETIC関数は、セル内のすべての文字に対して"ふりがな"を調べるので、次のように"漢字が含まれる"ようなケースでは、漢字もひらがなに変換されちゃいます。

いやぁ、懐かしいです。これは、まだ一般にはインターネットが知られていなかった約30年前、パソコン通信の掲示板で質問され、私が思いついた方法です。Excel(たぶん当時はExcel 95かな)で、なんか「カタカナとひらがなを指定できるような仕組み」ってなかったかな~と考えて「あ、ふりがなの設定に、確かあったよな~それ使えないかな~」みたいに閃いて、試したらうまくいった記憶があります。いやはや、大昔のできごとですけど、意外とよく覚えています。
実は先日、AIの回答をあれこれ調べていて、この件を質問してみました。ちなみに使ったのは、GoogleのGeminiです。まぁ、ChatGPTでもCopilotでも結果は同じでしょう。そしたら案の定「PHONETIC関数で~」という回答でした。なので続けて「カタカナだけ変換するには?」と聞いたところ「標準機能ではできません」的な回答でした。いや、正確には"できない"とは言わず"難しい"という表現でしたが、明らかに「いや~、それは無理っしょ」みたいな回答でしたね。う~ん、本当にできないかな~と。ちょっと考えてみたら「ん?あれ?今ならできんじゃね?」と思いつきました。試してみたら成功したので、一応ここに書きます。ただし、先にお断りしておくと、メッチャ難しいです。さらに、こんなことは、ほとんどしないでしょうから、実用性も低いです。とはいえ、可能っちゃ可能です。
まぁ、AIには無理でしょうけどね~( ̄∧ ̄)
関数だけで変換する
・前提知識1:カタカナとひらがなの文字コード
まず必要な知識とやり方を解説します。
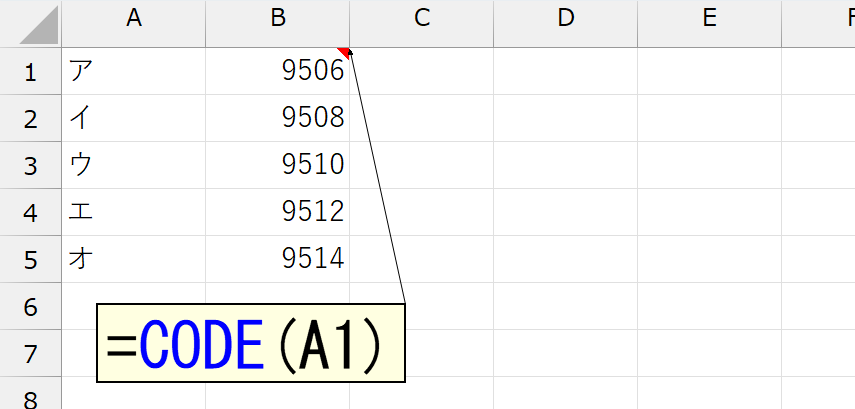
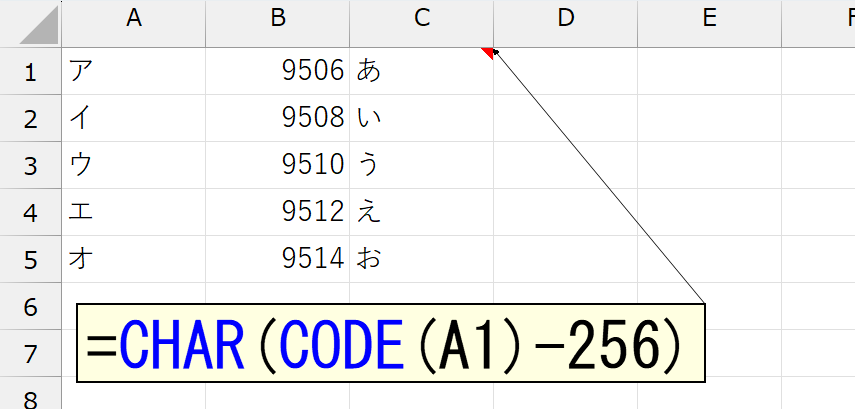
まずカタカナの文字コードを調べます。上図のとおりでした。「文字コードって何?」って、あまり深く考えないでくださいね。
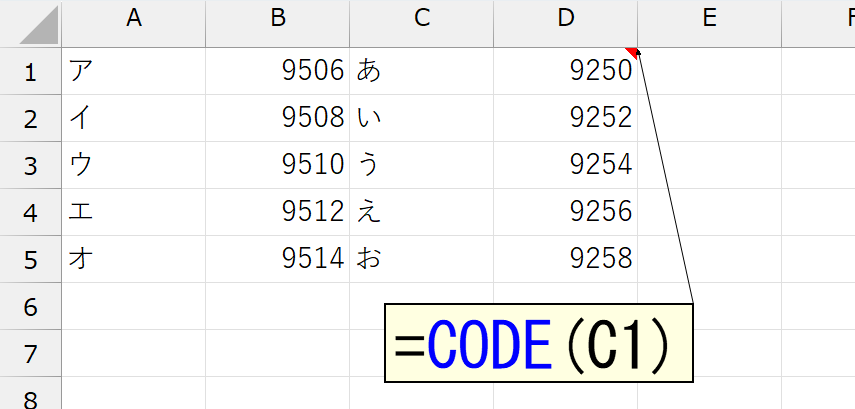
続いて、ひらがなの文字コードを調べます。両者を見比べると、カタカナの文字コードから、256を引いたのが、ひらがなの文字コードになっています。ってことは、次のように変換が可能です。
・前提知識2:カタカナかどうかの判定
これには、正規表現を使うのが簡単です。
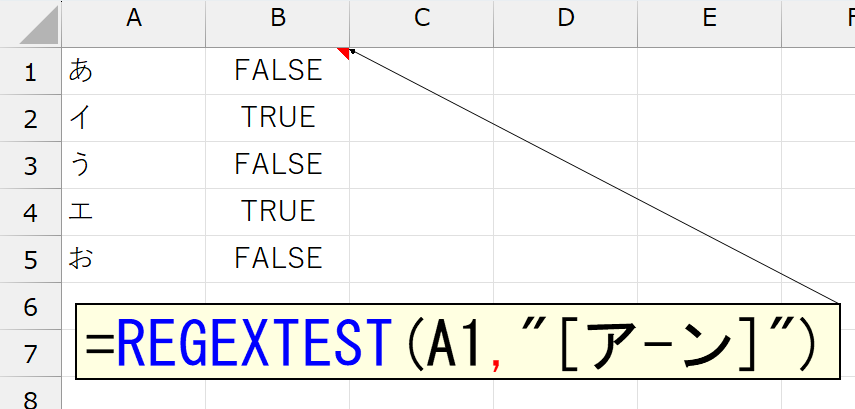
補足:すみません、ここ間違えていました。詳しくは[*1(下記参照)]をご覧ください。
・考え方と実際の数式
この2つが分かれば、勝ったも同然です。次のように考えます。
- セル内の文字列を、左から1文字ずつ抽出します
- もし、その文字が「カタカナだったら」文字コードから256を引きます
- 「カタカナではなかったら」そのまま、それまでの文字列に結合します
以上です。ちなみに1.はMID関数を使うのですが、ここでもちょっとテクニックが必要です。簡単なケースで考えてみましょう。
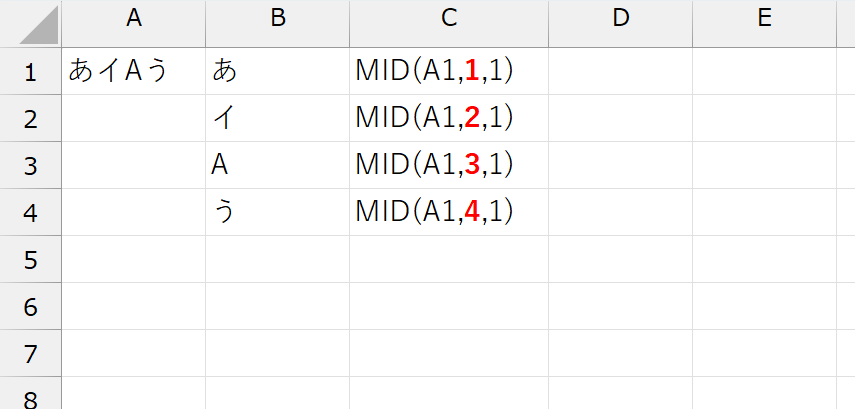
セルA1内の文字列で「1文字目から1文字分」を抜き出すと"あ"です。「2文字目から1文字分」は"イ"です。そして、最後の4は、セルA1に入力されている文字数です。つまり、MID関数の第2引数に「1・2・3…n」(n = 文字数)という連続した数値を指定したいです。とはいえ、元データ(ここではセルA1)は毎回異なります。そこを可変にするためにSEQUENCE関数を使います。
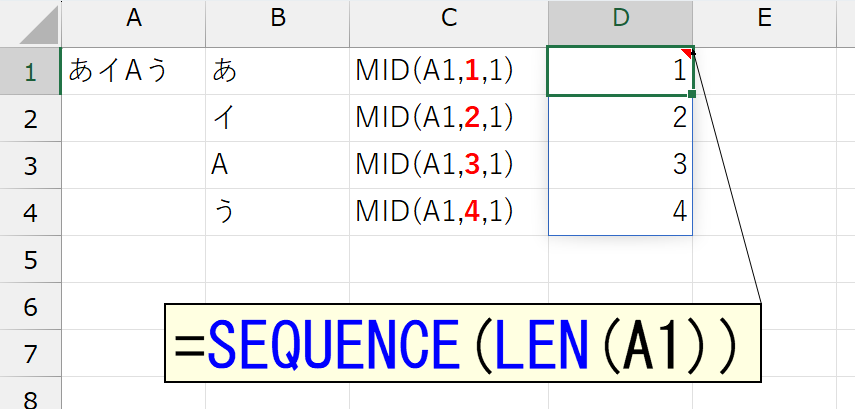
これで役者は揃いました。最終的な数式は次のとおりです。

=REDUCE("",MID(A1,SEQUENCE(LEN(A1)),1),LAMBDA(a,b,IF(REGEXTEST(b,"[ア-ン]"),a&CHAR(CODE(b)-256),a&b)))
簡単なケースで解説します。下図のように、「ひらがな-カタカナ-ひらがな」だったとします。

まず、数式全体は、下図のように「REDUCE(…,LAMBDA(a,b,…))」という構成です。REDUCE関数やLAMBDA関数について、ここでは詳細に解説しませんが、REDUCE関数が、LAMBDA関数に引数を渡して、LAMBDA関数が受け取った引数を使って何らかの処理を繰り返し、繰り返した結果が「変数a」に累積されて、その最終結果が返ります。

さて、REDUCE関数内の「SEQUENCE(LEN(A1))」ですが、LEN関数は"文字数"を調べる関数です。今回でしたら「3」ですね。「SEQUENCE(3)」は「{1;2;3}」という配列を返します。この配列を使ってMID関数で文字を抽出するので、MID関数の結果は「{あ;イ;う}」となります。この「{あ;イ;う}」が、1文字ずつ取り出されて、LAMBDA関数の引数bに入ります。

LAMBDA関数内に、ひとつのIF関数があります。IF関数の条件「REGEXTEST(b,"[ア-ン]")」は、上記「前提知識2」で書いた正規表現です。受け取った引数b(←ここに1文字ずつ入る)がカタカナだったらTRUE、ひらがなだったらFALSEになります。

IF関数の条件がTRUEだったら、その文字はカタカナです。なので、その文字をひらがなに変換します。それが「CHAR(CODE(b)-256)」です。詳しくは上述の「前提知識1」をご覧ください。

あとは、これを文字数分だけ繰り返します。

以上です。使う場面は、ほとんどないでしょうけど、REDUCE関数やLAMBDA関数の動作を理解する練習にはなる…かなw
補足
(*1)すみません、正規表現でカタカナを判定するパターンの[ア-ン]は間違いでした。これでは、小さい"ァ"が含まれません。

小さい"ァ"って、大きい"ア"の1つ前だったんですね。知らなかったです。ちなみに小さい"ァ"の文字コードは9505(0x2521)で、大きい"ア"の文字コードは9506(0x2522)です。小さい"ァ"より前にカタカナはありません。なので、正しくは[ァ-ン]でした。ちなみに、濁音や半濁音は[ァ-ン]の中に含まれます。下図は[ァ-ン]の結果です。
