REGEXEXTRACT 関数
Excelに新しいワークシート関数が3つ追加されました。本稿執筆時点(2024/5/24)では、まだInSider Programに実装されただけですので、製品版で使えるようになるには、もう少し時間がかかると思います。今回追加されたのは、REGEXTEST関数、REGEXEXTRACT関数、REGEXREPLACE関数の3つです。関数名からも分かるように、いずれも正規表現に関する関数です。
正規表現とは
正規表現とは、検索や置換などで、検索する文字列を「パターン化して表す」手法です。たとえば、ある文章の中から「田中」または「田原」または「田崎」という3種類の文字列を探すとき、検索を3回繰り返すのではなく、これら3つの文字列を「"田"で始まる2文字の文字列」などのような"パターン"を指定することで、そのパターンに該当する文字列を探します。ExcelやWindowsに備わっているワイルドカード(*や?)を使った、いわゆる"あいまい検索"みたいなイメージですね。正規表現は、このワイルドカードよりも、はるかに詳細なパターンを指定できる、いわば「ワイルドカードの上位版」みたいな仕組みです。
ちなみに、正規表現は英語で「regular expression」と呼ばれることから、一般的に「Regex」と表されます。「Regex」の読み方は、人によってさまざまです。「りじぇっくす」と読む人もいますが、私は昔から「れぐいーえっくす」と読んでいます。MS-DOSの時代には「れぐいーえっくす」の方が多かった気がします。まぁ、好きに読んでください。
追加された関数
今回追加された関数は、次の3つです。
- REGEXTEST関数
元の文字列(テキスト)の中で、指定したパターンに一致する文字列が存在するときにTRUEを返し、存在しないときはFALSEを返します。
(REGEXTEST関数の詳しい解説は、こちら)

- REGEXEXTRACT関数
元の文字列(テキスト)の中から、指定したパターンに一致する文字列を抽出します。

- REGEXREPLACE関数
元の文字列(テキスト)の中で、指定したパターンに一致する文字列を、別の文字列に置換します。
(REGEXREPLACE関数の詳しい解説は、こちら)

関数の引数
REGEXEXTRACT関数の引数は、次のとおりです。
REGEXEXTRACT(text, pattern, [return_mode], [case_sensitivity]) 日本語で表すと REGEXEXTRACT(テキスト、パターン、[モード]、[大文字と小文字の区別])
引数「テキスト」には、検索の元となる文字列や、その文字列が入力されているセルなどを指定します。引数「パターン」は、検索するパターンです。書き方は「REGEXTEST関数の解説」を参照してください。3番目の引数「モード」は、ちょっと説明が難しいので後述します。次の数値を指定します。
- 最初の一致(既定)
- 一致したすべて
- 最初に一致したグループ
4番目の引数「大文字と小文字の区別」は省略可能です。アルファベットを検索するときに指定します。省略すると、アルファベットの大文字と小文字を区別して検索します。
使用例
パターンの書き方に関しては「REGEXTEST関数の解説」を参照してください。
まずは、簡単なやつから。

パターンに一致する文字列を抽出して返します。パターンに一致する文字列が存在しないと、REGEXEXTRACT関数はエラーになりますので、何ならIFERROR関数を使ってください。
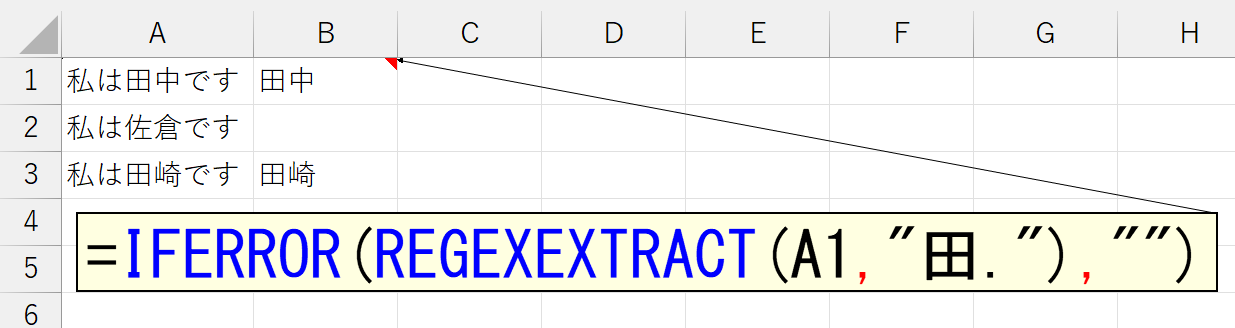
あるいは、こんなことも。
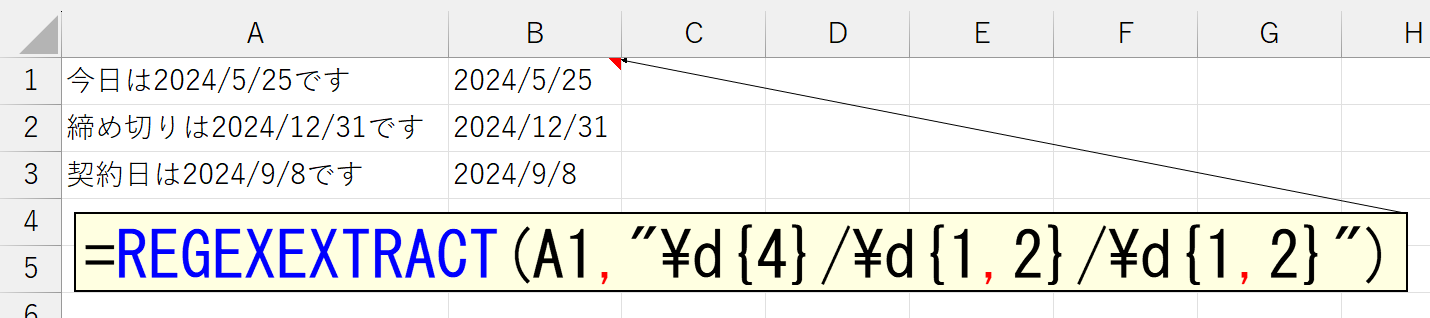
抽出できちゃえば、分割も簡単です。

では、パターンに一致する文字列が、複数存在していたらどうでしょう。
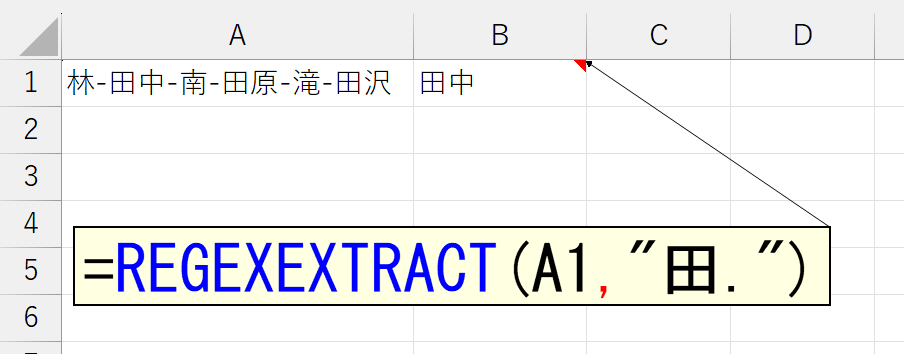
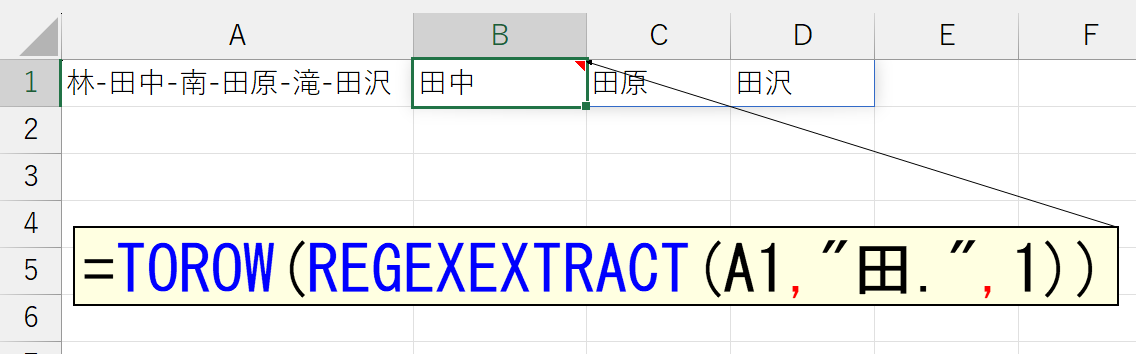
一致する文字列が複数存在すると、最初に該当した文字列が返ります。でも、ときには、パターンに一致したすべての文字列を抽出したいときもありますよね。そんなときに使うのが、3番目の引数「モード」です。ここまでは、この引数を省略していたので「0:最初の一致」が適用されていました。では「1.一致したすべて」を指定してみましょう。
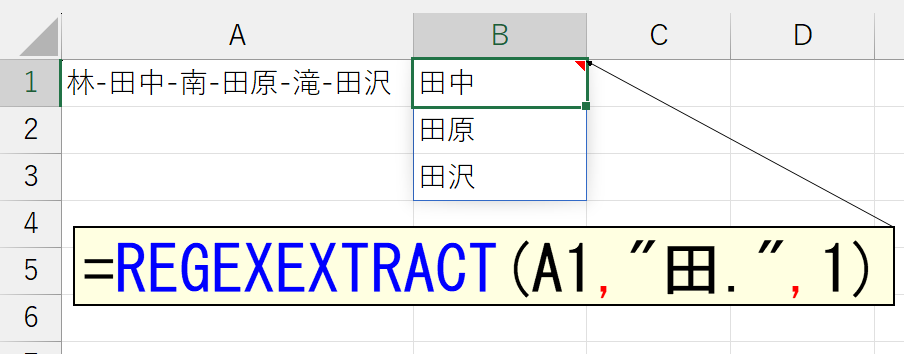
結果は配列で返りますのでスピります。横(行)方向に表示したいときは、TOROW関数を使いましょう。
さて、この3番目の引数「モード」には、もうひとつ「2.最初に一致したグループ」があります。これは何でしょう。ちょっと、ややこしいので順を追って解説します。
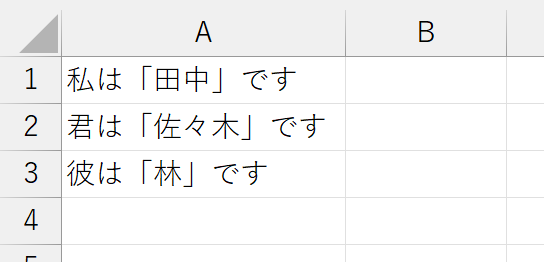
上図のように、「」で囲まれた内部を抽出してみます。ここでは、正規表現のパターンとして、「」の中に任意の文字が1文字以上存在する、としました。

「」で囲まれた文字列を探すのですから、「」の指定は必須です。でも、当たり前ですけど、これだと「」も抽出されます。今回欲しいのは「「」で囲まれた内部」です。「」は抽出したくありません。こんなときは、まず「抽出したい部分」を表す正規表現を()で囲ってグループ化します。

そして、3番目の引数「モード」に「2.最初に一致したグループ」を指定します。

この引数に指定する2の意味は、ヘルプによると「Return capturing groups from the first match as an array」と記載されています。日本語に訳すと「最初に一致したキャプチャ グループを配列として返します」です。"キャプチャ"という言葉は気にしないでください。"見つかった"とか"該当する"みたいに考えてください。いずれにしても「first match(最初に一致)」ということなので、もし正規表現内に複数のグループが存在する場合、そのうち"最初に一致した"グループだけが抽出されるのかと思いました。でも、試してみたら違いました。
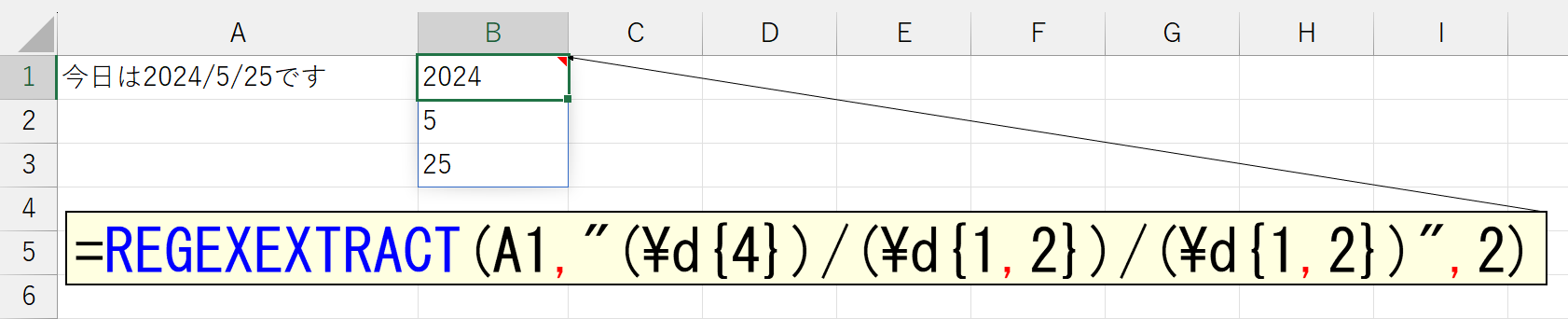
上図では、正規表現内に指定した3つのグループすべてが、配列形式で返ってきます。ちょっと難しいですけど、なかなか便利です。これを使うと、もしかして、アレができるかもって試してみました。住所の分割です。
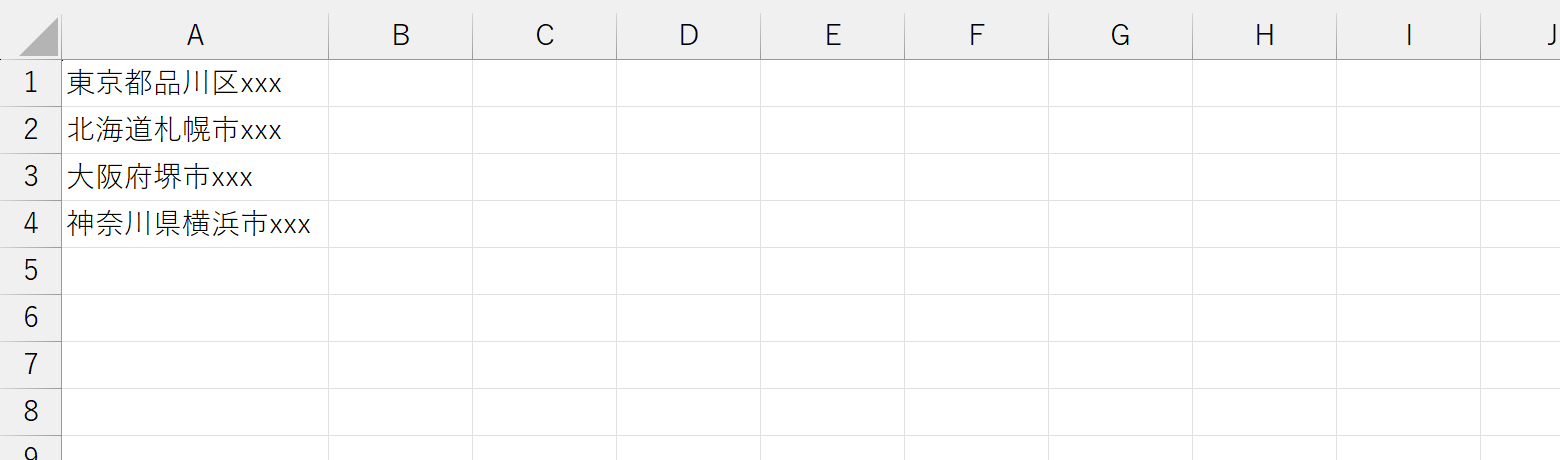
都道府県名の後ろにある「○○区」や「××市」のうち、「○○」「××」部分だけを抽出してみます。

あ、なんか、いけそうです。じゃ、もう少しイレギュラーなやつ。

おお、イイ感じじゃないですか?でも、住所の分割といえば、最難関な地域があります。ちなみに、大好きな地域です。住みたいです。

このやり方では無理でした。もっとあれこれ工夫すればできそうですけど、簡単にはできませんでしたね。今回は「簡単にできるかな?」って検証だったので、今日はこのくらいで勘弁してやりましょう。お、おぼえてよろよ!まぁでも、都道府県名の中に「都道府県」という文字が含まれているってのが面倒ですね。