REGEXTEST 関数
Excelに新しいワークシート関数が3つ追加されました。本稿執筆時点(2024/5/24)では、まだInSider Programに実装されただけですので、製品版で使えるようになるには、もう少し時間がかかると思います。今回追加されたのは、REGEXTEST関数、REGEXEXTRACT関数、REGEXREPLACE関数の3つです。関数名からも分かるように、いずれも正規表現に関する関数です。
正規表現とは
正規表現とは、検索や置換などで、検索する文字列を「パターン化して表す」手法です。たとえば、ある文章の中から「田中」または「田原」または「田崎」という3種類の文字列を探すとき、検索を3回繰り返すのではなく、これら3つの文字列を「"田"で始まる2文字の文字列」などのような"パターン"を指定することで、そのパターンに該当する文字列を探します。ExcelやWindowsに備わっているワイルドカード(*や?)を使った、いわゆる"あいまい検索"みたいなイメージですね。正規表現は、このワイルドカードよりも、はるかに詳細なパターンを指定できる、いわば「ワイルドカードの上位版」みたいな仕組みです。
ちなみに、正規表現は英語で「regular expression」と呼ばれることから、一般的に「Regex」と表されます。「Regex」の読み方は、人によってさまざまです。「りじぇっくす」と読む人もいますが、私は昔から「れぐいーえっくす」と読んでいます。MS-DOSの時代には「れぐいーえっくす」の方が多かった気がします。まぁ、好きに読んでください。
追加された関数
今回追加された関数は、次の3つです。
- REGEXTEST関数
元の文字列(テキスト)の中で、指定したパターンに一致する文字列が存在するときにTRUEを返し、存在しないときはFALSEを返します。

- REGEXEXTRACT関数
元の文字列(テキスト)の中から、指定したパターンに一致する文字列を抽出します。
(REGEXEXTRACT関数の詳しい解説は、こちら)

- REGEXREPLACE関数
元の文字列(テキスト)の中で、指定したパターンに一致する文字列を、別の文字列に置換します。
(REGEXREPLACE関数の詳しい解説は、こちら)

関数の引数
REGEXTEST関数の引数は、次のとおりです。
REGEXTEST(text, pattern, [case_sensitivity]) 日本語で表すと REGEXTEST(テキスト, パターン, [大文字と小文字の区別])
引数「テキスト」には、検索の元となる文字列や、その文字列が入力されているセルなどを指定します。引数「パターン」は、検索するパターンです。書き方は下記を参照してください。3番目の引数「大文字と小文字の区別」は省略可能です。アルファベットを検索するときに指定します。省略すると、アルファベットの大文字と小文字を区別して検索します。
パターンの書き方
正規表現というのは、どこかの企業が作った仕組みではありません。もともとは、言語学の一分野として研究された考え方です。それを、長い歴史の中で、多くのアプリケーションやプログラミング言語が独自に採用してきました。したがって、多くの"派生"が存在します。今回追加された3つの関数で採用されている正規表現は「PCRE2」(Perl Compatible Regular Expressions)に準拠しています。PCRE2の構文は、めっちゃ細かいので、ここですべてを解説するのは現実的ではありません("めんどくさい"ともいう)。なので本稿では、よく使うであろうパターンだけを紹介します。
| 記号 | 意味 |
|---|---|
| . | 任意の1文字 |
.(ピリオド)は、任意の1文字を表します。ワイルドカードの?に似ています。

.(ピリオド)は、改行コードを含みません。セル内改行の"改行コード"は含まれませんので留意してください。

| 記号 | 意味 |
|---|---|
| ^ | 行頭 |
| $ | 行末 |
^(キャレット)は行頭、$(ドル)は行末を表します。


^(キャレット)は、後述するキャラクタクラス内で使うと"否定(~ではない)"という意味になります。
| 記号 | 意味 |
|---|---|
| [ ] | キャラクタクラス |
| ( ) | グループ化 |
| | | 論理和(いわゆる"または") |
さぁ、このへんからが、正規表現の真骨頂です。まず、めっちゃ使う[ ](角括弧)から解説します。[ ]はキャラクタクラスと呼ばれ、ワイルドカード「*」の高機能版みたいなイメージです。例をお見せします。
[ ]の中に指定した文字は、それぞれOR(または)の意味になります。

上記は「田中」または「田原」または「田崎」である、というパターンです。[ ]の先頭に^(キャレット)を付けると、キャラクタクラス内全体に対して「~ではない」という意味になります。

上記は「田中ではない」または「田原ではない」または「田崎ではない」という意味です。^(キャレット)が「~ではない」を表すのは、[ ]内の先頭に書いたときだけです。"田[中^崎]" のように途中に指定した^(キャレット)は、単なる「^(キャレット)という文字」として扱われます。

[ ]内には「○から×まで」のような範囲を指定できます。範囲の始まりと終わりは、-(ハイフン)で区切ります。
| 記号 | 意味 |
|---|---|
| [0-9] | 0123456789のいずれか(任意の数字) |
| [A-Z] | ABCDE…VWXYZのいずれか(任意の大文字英字) |
| [a-z] | abcde…vwxyzのいずれか(任意の小文字英字) |
こちらも先頭に^(キャレット)をつけて「~ではない」の指定ができます。
| 記号 | 意味 |
|---|---|
| [^0-9] | 0123456789ではない(数字ではない) |
| [^A-Z] | ABCDE…VWXYZではない(大文字英字ではない) |
| [^a-z] | abcde…vwxyzではない(小文字英字ではない) |
具体例は後述します。
( )は、複数のパターンをグループ化するときに使います。グループ化するときは一般的に、|(論理和)と一緒に使うことが多いです。|(論理和)はOR(または)を表します。(○|×)のように書くと「○である または ×である」という意味になります。


上記のように、論理和と一緒に使うことが多いですけど、( )は単なる"一括り"として使うこともあります。これは、算数や数学などで用いられる( )の使い方に似ています。たとえは、1 + 2 + 3 + 4 = 10という数式は、1 + (2 + 3) + 4 = 10と書いても同じです。この(2 + 3)は、2 + 3をただ"一括り"にしただけですよね。こういう使い方です。なぜ、こんなことをするのかというと、正規表現で、この(2 + 3)部分を後で何かするための、いわば"目印"です。このへんの使い方は、REGEXEXTRACT関数やREGEXREPLACE関数で解説します。ちなみに、1 + 2 + 3 + 4と1 + (2 + 3) + 4では、計算の順序が違う、と感じた方もいるでしょう。実は正規表現でも、( )で囲まれたパターンの方を先に評価するという、計算の順序を決めるのと同じような働きもあります。まぁ、そこまでいくと複雑になりすぎますので、ここでは割愛します。
| 記号 | 意味 |
|---|---|
| * | 直前パターンの 0回以上の繰り返し |
| + | 直前パターンの 1回以上の繰り返し |
| ? | 直前パターンが 0回または1回現れる |
ここからが正規表現の沼です。"パターン作り"で最も頭を悩ませるところでしょう。まずは「*」と「+」から。

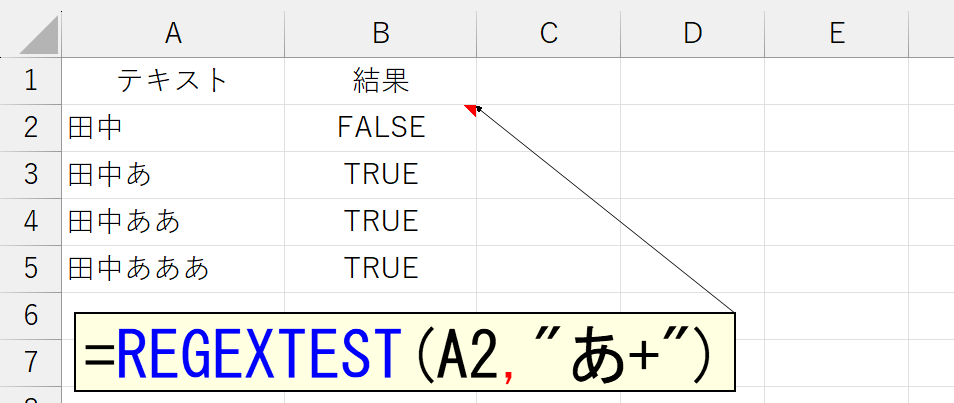
「0回以上」ということは、0回も含まれます。0回出現するということは、すなわち"出現しない"と同義です。

[0-9]は、0から9までの"任意の数字"です。その"任意の数字"が1回以上繰り返されるのですから「4月」と「12月」が該当します。
たとえば「1回以上の繰り返し」は、2回でも97回でも256回でも、何回繰り返されても該当しますが、この回数を指定したいときは次のようにします。
| 記号 | 意味 |
|---|---|
| {n} | n回の繰り返し |
| {n,} | n回以上の繰り返し |
| {n,m} | n回以上m回以下の繰り返し |
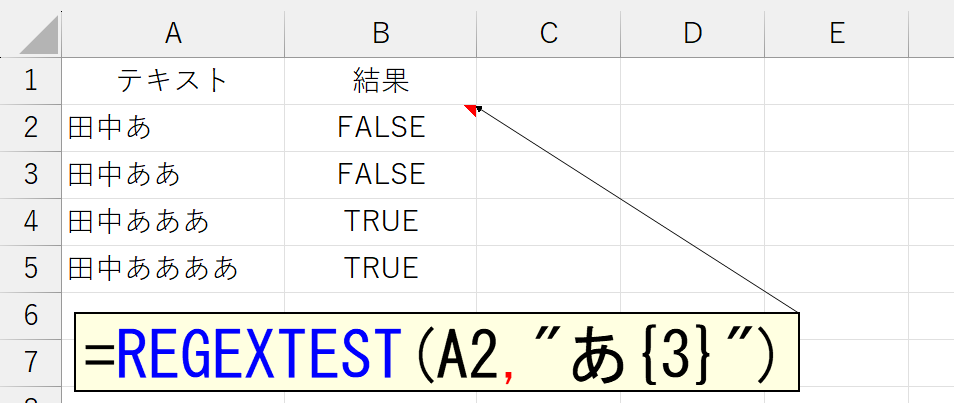
「ああああ」(4回繰り返されている)の中には「あああ」(3回繰り返されている)が含まれていますので該当します。

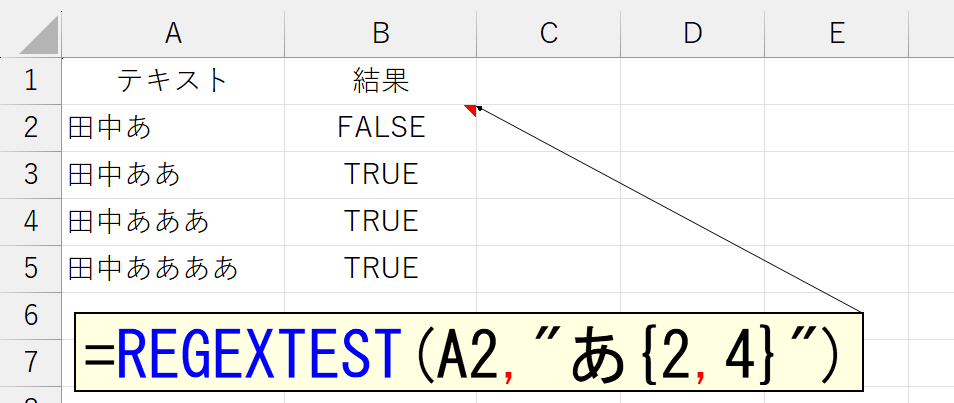
う~ん、あまり良い例ではありませんでしたね。数字の方が分かりやすいかな。
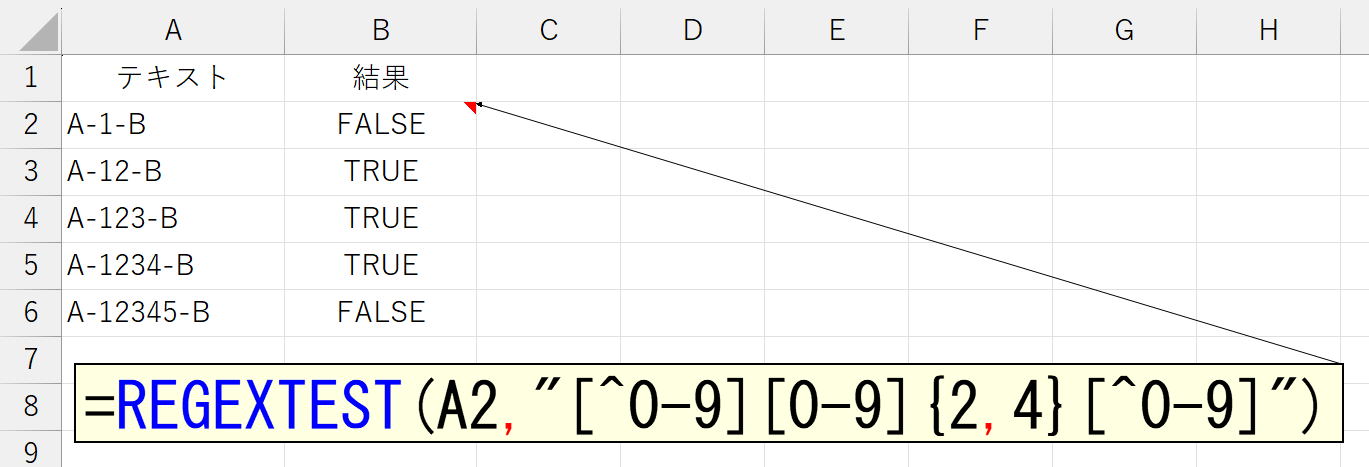
ダメだ…良い例が思い浮かばない。今日は調子が悪いっす。
最後に「?」(直前パターンが 0回または1回現れる)です。一見すると「なんじゃ、そりゃ?」って感じるかもしれません。要するに「(ある文字が)あっても、なくても、該当することにしてください」というときに使います。たとえば「プリンター」という文字列が「プリンタ」と表記揺れを"しているかもしれない"みたいなとき、どちらも見つけたい、みたいなケースです。

もっとも、このパターンだと「プリンターー」も該当してしまいますので

それらを除きたいときは、次のようにキャラクタクラスで除外してください。

| 記号 | 意味 |
|---|---|
| \ | 続く記号を単なる文字として扱う |
ここまで紹介したような、正規表現のパターンを指定するときに使用する記号([]とか()などなど)を、単なる文字として指定したいときは、\をつけます。
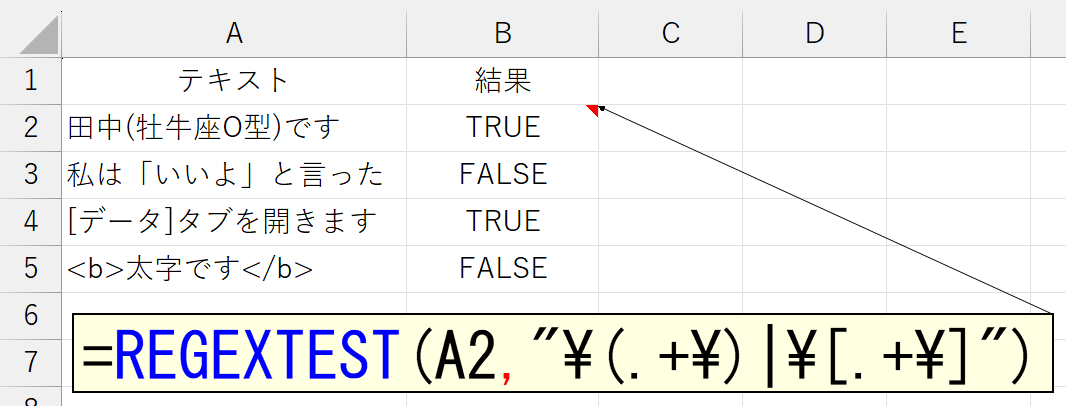
また\は、特定の英字と組み合わせることで、特別な意味を持ちます。
| 記号 | 意味 |
|---|---|
| \s | 空白(半角と全角を問わない) |
| \S | \s以外 |
| \d | 任意の数字([0-9]と同じ) |
| \D | \d以外 |
| \c | 英数字と「_(アンダーバー)」([a-zA-Z0-9_]と同じ) |
| \C | \c以外 |
| \n | 改行コード(0x0A) |
| \r | 改行コード(0x0D) |
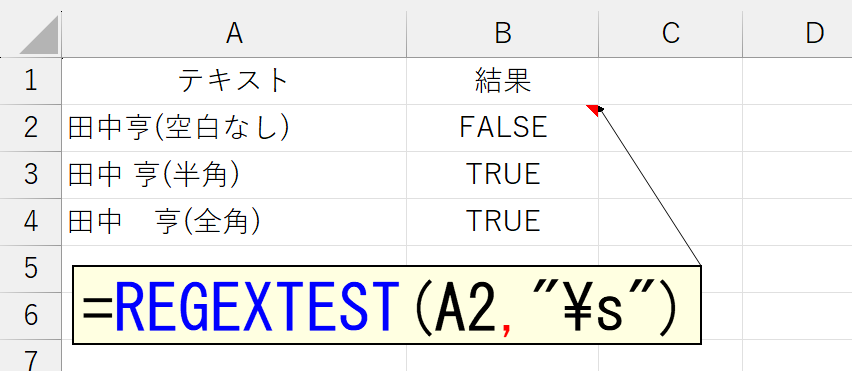
\sは空白(スペース)を表します。半角と全角は区別しません。
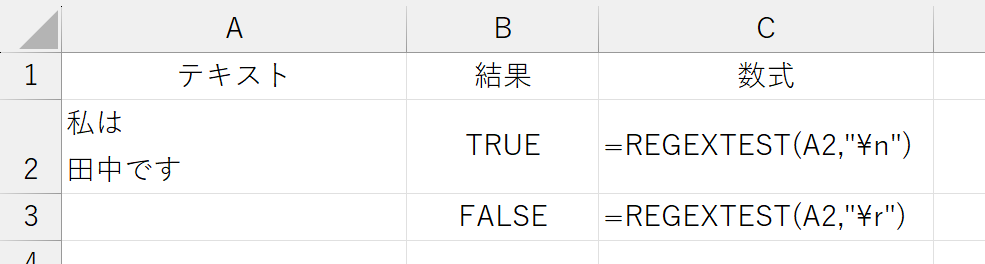
セル入力時に Alt + Enter キーを押して挿入する"セル内改行"は、\n(0x0A)です。
こんなところですかね~どうです?難しいでしょ。まぁ、正規表現なんて、全Excelユーザーが使うものじゃありません。必要だと思ったら使えばいいし、なんか難しくて無理って感じたら使わなくていいです。
ValueかTextか
さて、Excelユーザーであれば、正規表現に関して注意すべきは、これです。つまり、検索の対象になるのは「セルに入力されている値(Value)」なのか、それとも「セルに表示されている文字列(Text)]なのかです。
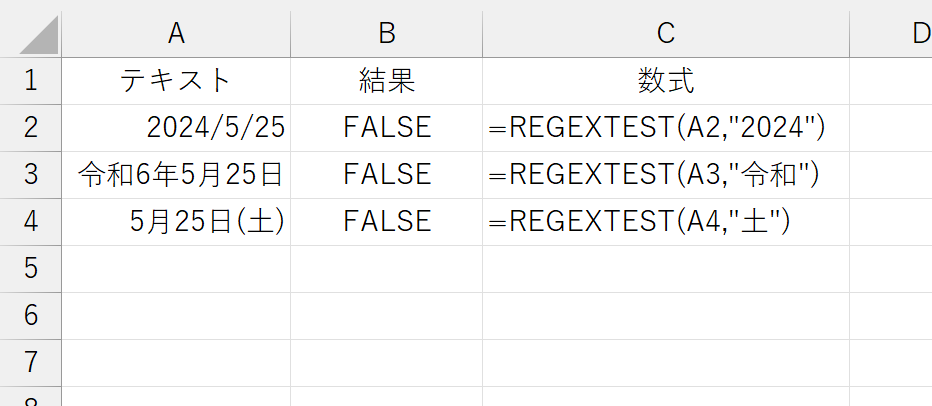
A列には日付を入力して、それぞれ表示形式を設定しました。全滅ですね。セルに日付を入力すると、実際にはセルにシリアル値が入力されます。ちなみに、2024/5/25のシリアル値は45437です。
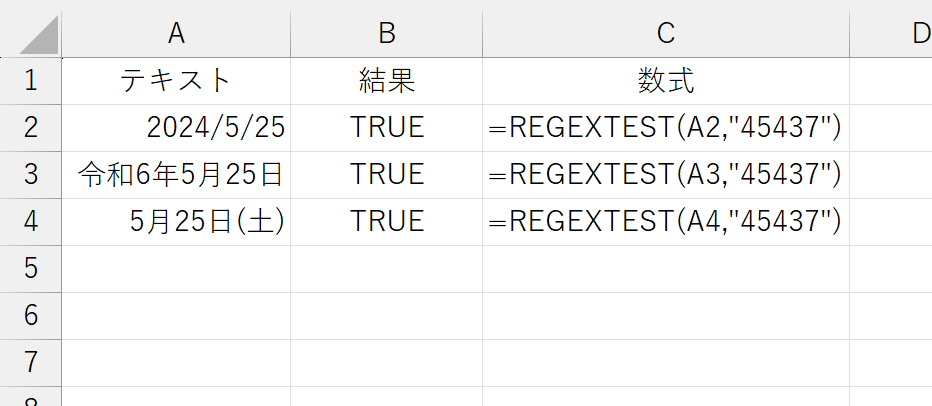
以上のことから、REGEXTESTなど正規表現系の関数は「セルに表示されている文字列(Text)]ではなく「セルに入力されている値(Value)」を検索対象としていることが分かります。上記のような検索を行うには、たとえば次のように、TEXT関数で文字列化してから調べます。
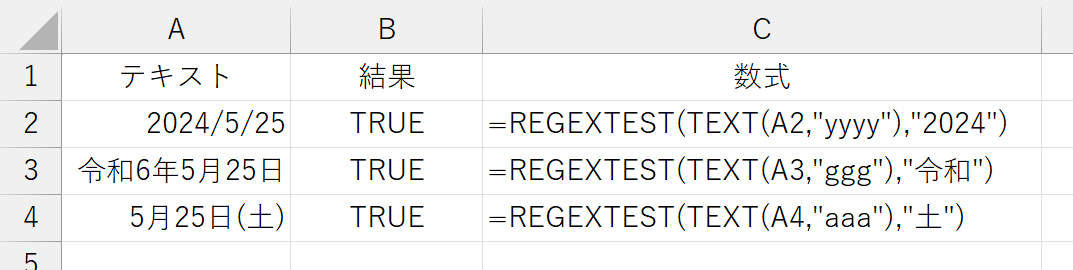
では、数式はどうでしょう。セルに数式が入力されている場合は、数式の計算結果を検索してくれるのでしょうか。

こちらはOKですね。ちなみに、セルに入力した数式の計算結果は、Valueプロパティに格納されるので、VBAを学習している方でしたら察しが付くと思います。