グループ化
「取得と変換」のPower Queryエディタには「グループ化」という機能があります。
これ何に使う機能のなのか、サッパリ分かりませんでした。いったい、どんなとき使う機能なのか?どんなときに便利なのか?以前、Power BI系の偉い人に聞いたことがあります。「ねぇねぇ、グループ化ってあるじゃん、あれって何する機能なの?」偉い人は言いました。「ん?グループ化するんだよ」聞いてもサッパリです。で、あれこれと試してみました。たとえば、次のようなデータでやってみましょう。
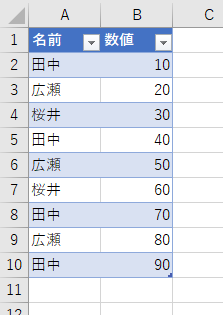
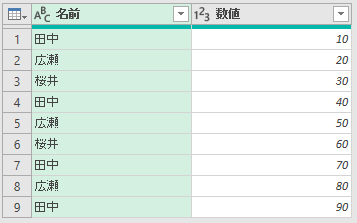
Power Queryエディタで読み込みます。
[グループ化]ボタンは、[ホーム]タブの真ん中へんと[変換]タブの左端にあります。どっちでも同じです。
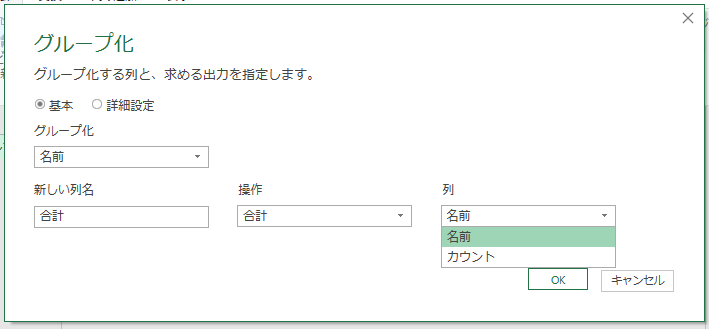
実行すると、次のような画面が開きます。
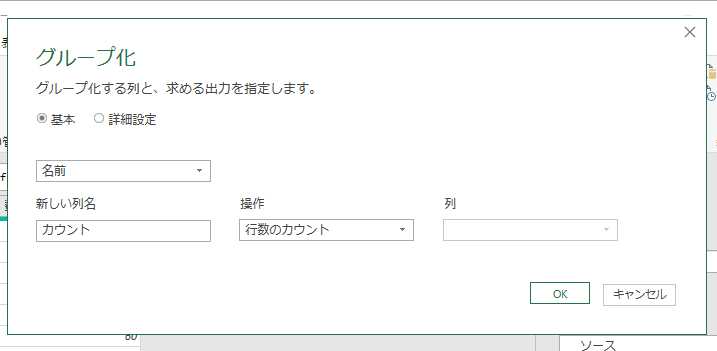
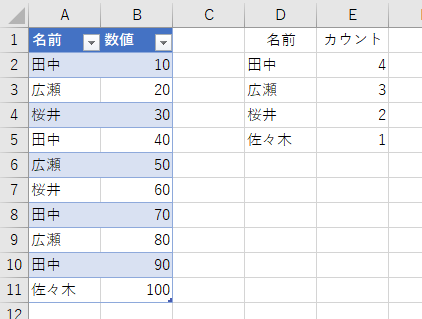
よく分からないので、このまま[OK]ボタンをクリックしてみましょう。実行すると次のようになります。
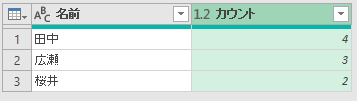
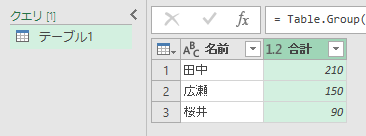
いや、意味は分かるんですよ。実行結果の意味は。これ、要するにCOUNTIFでしょ。試しに、先の画面で「カウント」ではなく「合計」にしてみます。
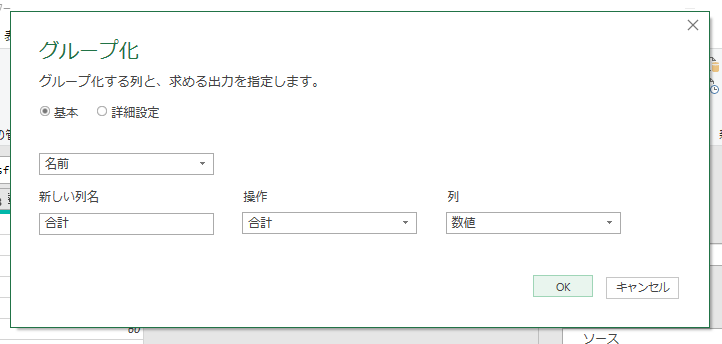
結果は下図のとおり。
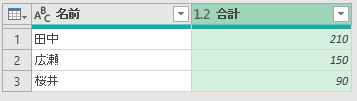
これ、SUMIFですよね。いや、意味は分かるんですよ。何をしているのかは。だけど、いったいこの機能を、どんなときに使えというのでしょう。だって、普通にシート上でCOUNTIF関数やSUMIF関数を使うのと同じじゃないですか。これを「取得と変換」でやるのって、どんなシーンなのか、それがイメージできないんです。もちろん、他にも"Excelでも同じことできるし"って機能はあります。それも知ってます。でも「グループ化ぁぁ!」って、まるで必殺技みたいに。しかもリボンの中に2つも同じボタン配置して、なんか「どうっすか?グループ化、これすごいよ、みんな使ってよ!どうっすか?」的な、"グイグイ感"の意味が分かりません。もっと、ひっそりと、リボンの隅の方で「いやぁ~私なんか、たいしたことありませんから…」的に謙虚な姿勢が欲しいです。
ああ、ちなみに、他にも「平均」「中央」「最小」「最大」「個別の行数のカウント」「すべての行」などを選択できます。できますけど、実務で使う機会はないでしょう。
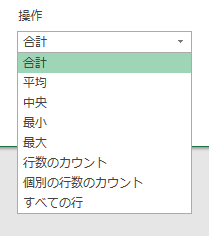
(追記3)
「個別の行数のカウント」って意味が分かりました。これも本稿の最後で解説します。これ、もしかするとスゴイかもしれません。
試しに「カウント」と「合計」の両方をやってみようかと思いましたが、これ、できませんでした。まず先に「カウント」でグループ化すると、その時点で[名前]列がグループ化されてしまいますので、次の「合計」ができません。あれこれやってみましたけど無理でした。Power BI系の偉い人だったら、もしかして「いや、こうして、こうして、こうすればできるよ」って言うかもしれませんけど、そうじゃないんです。できればいいんじゃありません。誰もが簡単にできなかったら、Excelユーザーは納得しませんし、使いません。
(追記1)
本稿を読み返していて「ああ、こうすればできるか」と気づきました。本稿の最後に書いておきます。
(追記2)
あああ、すみませんでした。グループ化を複数やるのって、標準機能であったんですね。気がつきませんでした。私が悪かったです。ごめんなさい。これも本稿の最後に書きますから許してください。
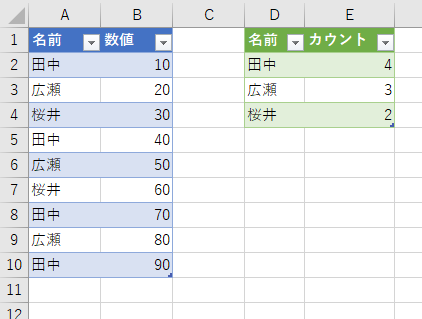
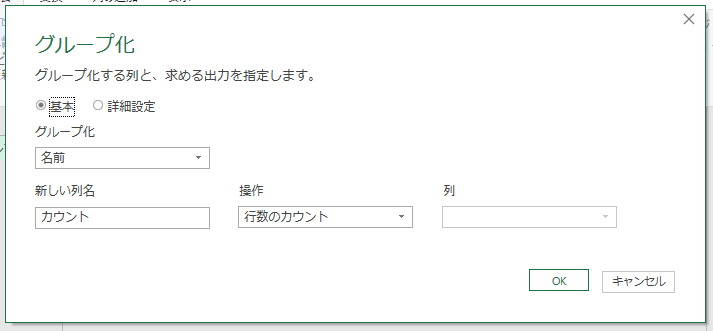
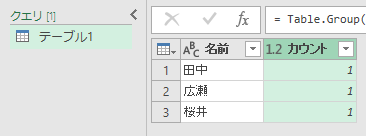
しかたないので「カウント」だけで、シート上に読み込んでみました。さて、元のテーブルに新しいデータを追加してみましょう。更新すると、新しいデータが追加されます。
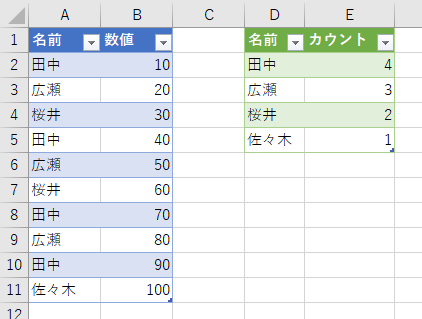
ああ、なるほどね。もしかすると、次のような反論があるかもしれませんね。
いやいや、田中さん何言ってんの?今やってみて分かったっしょ。新しい名前が追加されたとき、それが自動的にリストアップされてカウントされるっしょ。こんなこと、Excelのワークシート関数だけじゃできないっしょ!
巻島か!
ったく、キミはいったい何を言っているのかね。はい、できませんよ、今のExcelではね。でも、できるようになるんだよ(笑)~ゴメンねぇ(笑)~

知らなかった人は、次のページを100回ずつ読んで、反省文を提出してください。
Excel 2016レビュー「Excelの使い方が激変する「スピル」」
この関数はこう使え「UNIQUE関数」
ということで、ますますもって、この「グループ化」を便利に使う場面が思い浮かびません。まあ、無理して使わなくてもいいでしょう。Excelで簡単にできることは、Excelでやればいいのですから。何か、画期的な使い方が閃いたら、ここに追記します。
グループ化した結果を2つ並べる方法(クエリのマージ編)
上の方で、1つのクエリ中で複数のグループ化を同時にできない、と書きましたが、ふと閃きましたので追記しておきます。つまり下図のようなことを「取得と変換」でやる方法です。
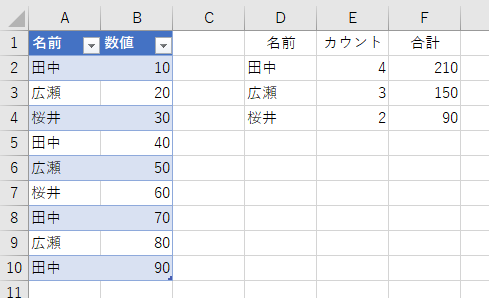
まあ、上にも書きましたが、だったらCOUNTIF関数とSUMIF関数を使った方が100倍簡単ですけど。ま、いいや。
まずは、元データをPower Queryエディタで読み込みます。
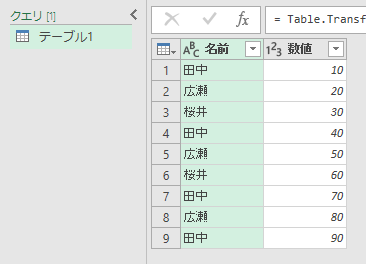
最初は、"できない考え方"をお見せします。上に書いた手順で、[名前]をグループ化します。1つめは「カウント」にしましょう。
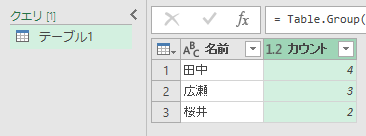
[名前]列を選択して、もう一度[グループ化]ボタンをクリックします。今度は「合計」です。
お分かりいただけただろうか…合計したい[数値]列がありません。そりゃそうです。「カウント」のグループ化をしたことで、[名前]列以外はなくなってしまったのですから。だったら、先に「合計」をやればいいのでは?はい、もちろん私だってそれを考えました。やってみましょうか。
この状態で[グループ化]ボタンをクリックします。
[OK]ボタンをクリックすると…
ね、だから私は最初「グループ化って1つしかできないん?」って思ったわけです。では、やり方を解説します。テーブルをPower Queryエディタで読み込んだところからです。
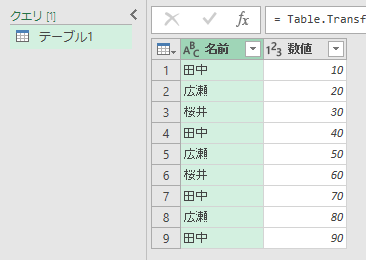
[クエリ]リストの「テーブル1」を右クリックして[複製]をクリックします。
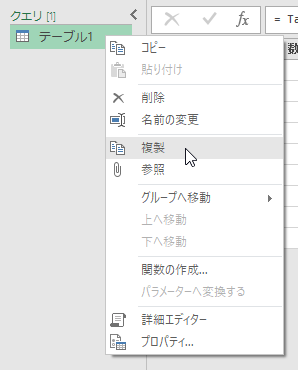
実行すると「テーブル1」の複製(コピー)である「テーブル1(2)」が作られます。クエリの名前を、分かりやすいものに変えてもいいですけど、今回は面倒くさいので、このままいきます。
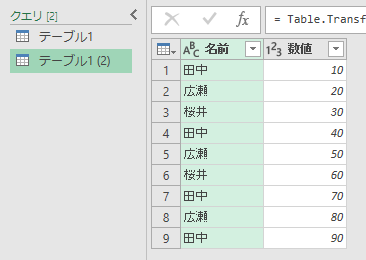
ちょうど今、複製した「テーブル1(2)」が選択されていますから、こっちから処理しちゃいましょう。[名前]列が選択されているのを確認して[グループ化]ボタンをクリックします。
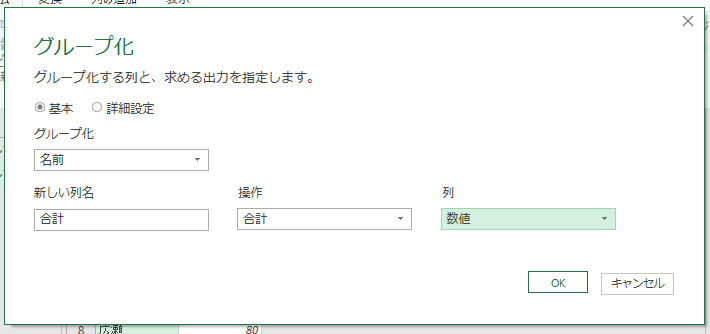
実行すると[グループ化]画面が表示されますので、こちらで「合計」を作ります。
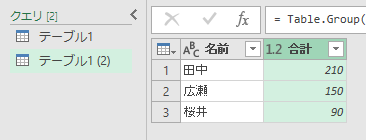
次に、最初の「テーブル1」を選択して、グループ化の「カウント」を作成します。
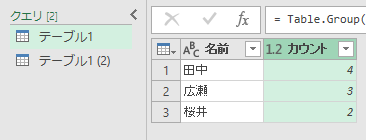
「テーブル1」が選択されている状態で、[クエリのマージ]ボタンをクリックします。
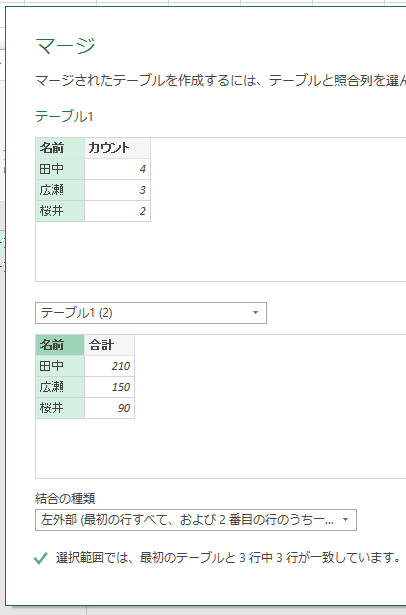
[マージ]画面が表示されますので、マージしたいクエリとして「テーブル1(2)」を選択します。つまり「合計」のグループ化をしたクエリです。照合列には「名前」を選択します。2つのクエリとも[名前]列は同じはずですから、結合の種類は標準の「左外部」でいいです。結合の種類に関しては「マージの種類」で詳しく解説していますので、そちらをご覧ください。あとは[OK]ボタンをクリックして
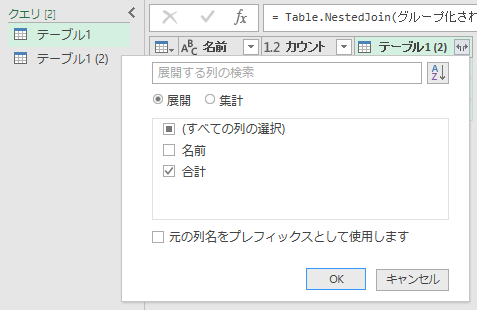
こうすれば
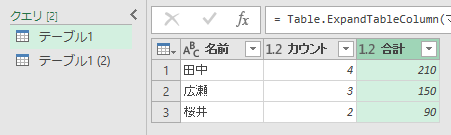
完成です。これをシート上に読み込んでください。
グループ化した結果を2つ並べる方法(標準機能編)
本当にごめんなさい。これ、標準機能で簡単にできたんですね。てゆーか、こういう使い方も、ちゃんと用意されてたんですね。ごめんなさい>グループ化
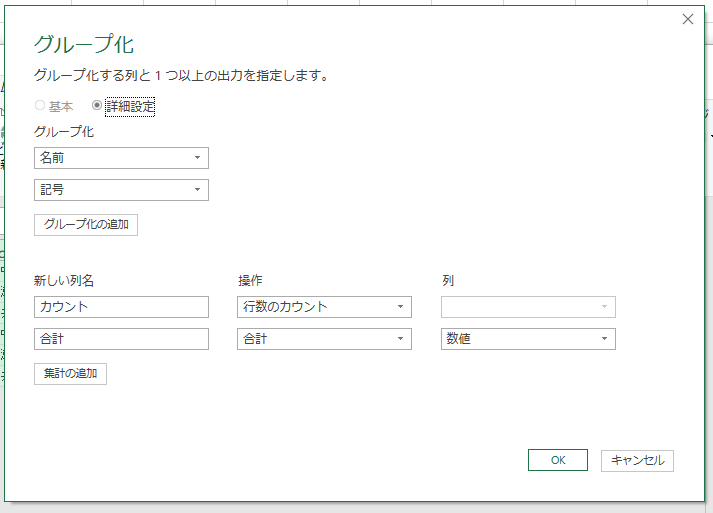
[グループ化]画面で「詳細設定」を選択すればいいんですね。
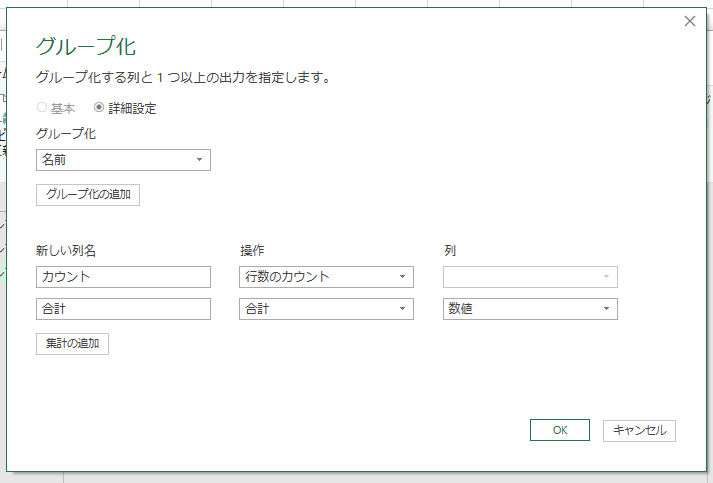
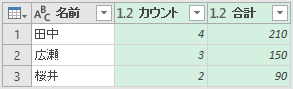
さらに[グループの追加]ってのもありますね。これ、きっとCOUNTIFSとSUMIFSですよね。
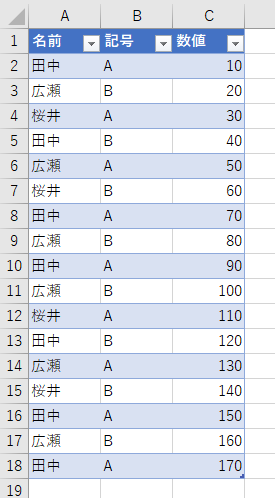
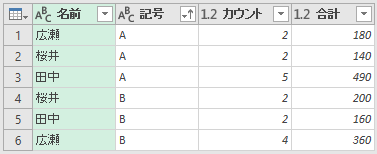
COUNTIFS関数やSIMIFS関数のように、複数の条件を指定できるのなら、次のようなケースにも対応できますね。
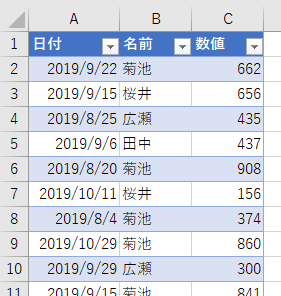
100件くらいあります。これを「月別」で「名前別」に集計してみます。まずは、Power Queryエディタに読み込みます。
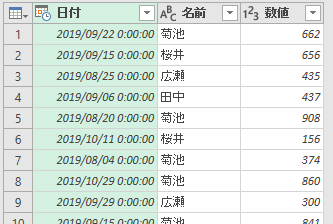
「名前」はいいんですけど、「日付」は最終的に"2019-09"とか"2019-10"みたいに表示したいです。あ、ちなみに8月から10月まで3ヶ月分の日付がランダムに並んでいます。ここはひとつ、集計用の列を作りましょうか。「日付」列を選択して[列の追加]タブ[例からの列]の[選択範囲から]をクリックします。
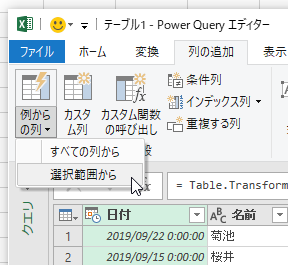
「列1」の先頭行に"2019-09"と入力してみました。さすがに、これだけでは"何をしたいのかのルール"が分からないのでしょうね。何も起きません。しかたないので、別の月(ここでは2019/08)の行に"2019-08"と入れてみました。
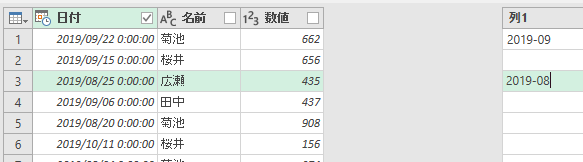
Ctrl + Enterを押すと
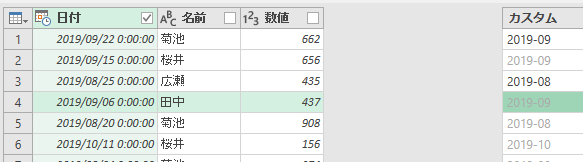
素晴らしい!さて、ここからはグループ化です。ちなみに、列の名前が「カスタム」では意味不明ですから「年月」に変更しました。
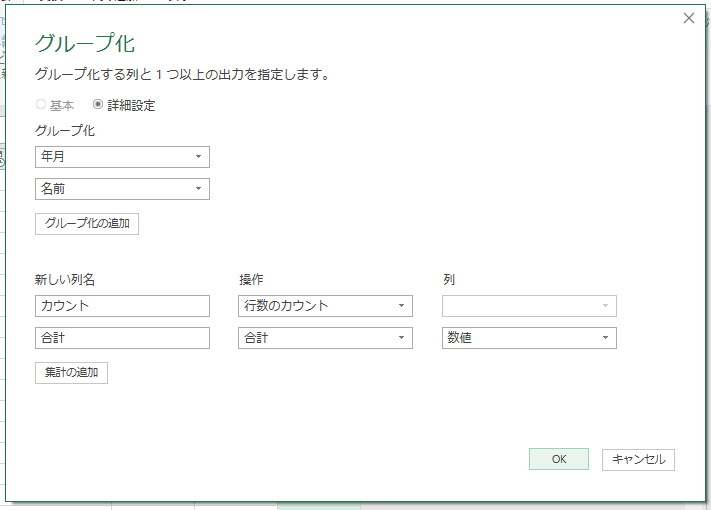
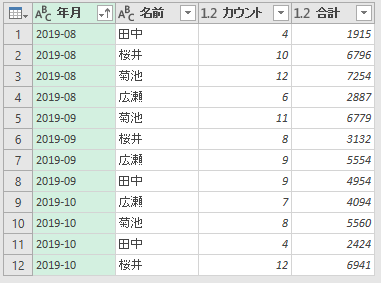
う~ん、グループ化かぁ・・・そんなに、悪いやつじゃなさそうです。
「個別の行数のカウント」とは
グループ化では、次の操作を選択できます。
「合計」とか「平均」は、誰にでもすぐ分かります。SUMIFやAVERAGEIFです。「最小」と「最大」もイメージできますし、その真ん中が「中央」なのでしょうね。ところで、いわゆるCOUNTIF的なことをするのでしたら「行数のカウント」を選択します。でも、その下に「個別の行数のカウント」と「すべての行」があります。これ、いったい何なんでしょう。「個別の行数のカウント」って、あれこれやったら意味が分かりましたので解説します。ここでは、次のようなデータを例にします。
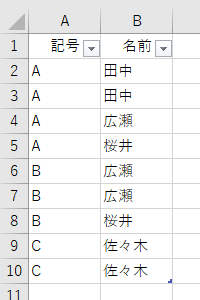
「記号」は全部で3種類あります。"A"と"B"と"C"です。データの中で"A"は4個、"B"は3個、"C"は2個あります。
"A"は4個ありますが、該当する「名前」は「田中・田中・広瀬・桜井」です。"田中"がダブってますから、"A"に該当する(重複しない)「名前」は3人です。
同じように、"B"は3個ありますが、該当する「名前」は「広瀬・広瀬・桜井」で2名です。
最後の"C"は2個登場しますが、該当する「名前」は「佐々木」の1名だけです。これらを踏まえた上で、グループ化の「行数のカウント」と「個別の行数のカウント」をやってみます。
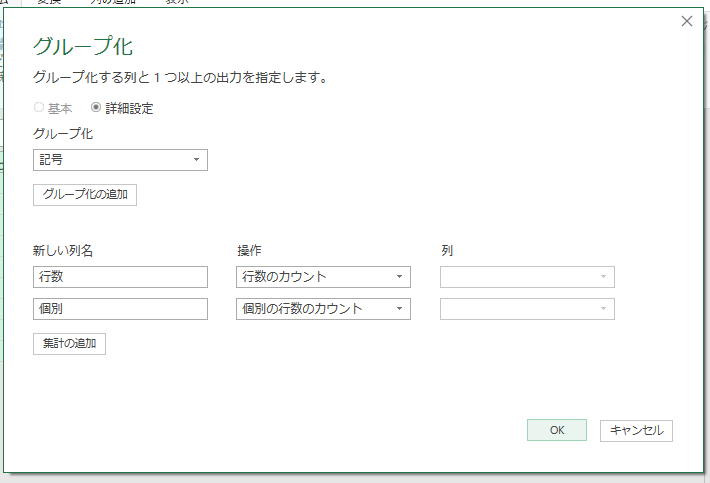

通常の「行数のカウント」は、グループ化で指定した列(ここでは[記号])の中に、それぞれの要素が何個あるかを返します。
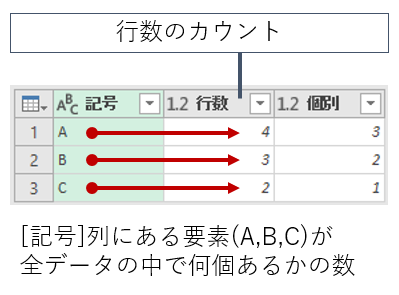
「個別の行数のカウント」というのは、グループ化した各要素(A,B,C)の中に含まれる、重複しない(ユニークな)行数を返します。"A"は「田中・田中・広瀬・桜井」で3人、"B"は「広瀬・広瀬・桜井」で2人、"C"は「佐々木」の1人です。
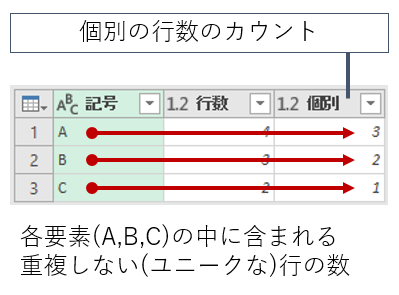
「個別の行数のカウント」は、あくまで"行数"を返すことに留意してください。今回は[記号]と[名前]の2列しかありませんから、グループ化した[記号]を除くと、各要素に含まれる列は[名前]だけです。だから[名前]列だけのユニーク件数を返しました。もし、データの中に、他にも別の列が存在していたら、グループ化した列以外の"すべての列"でユニークな行数を返します。
ちょっと、やってみましょう。
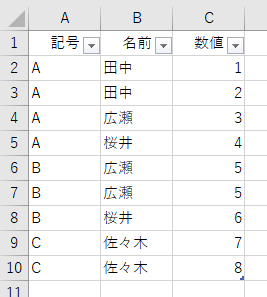
[記号]の要素"A"に含まれる、[記号]列ではない要素([名前]-[数値])は、
田中 - 1
田中 - 2
広瀬 - 3
桜井 - 4
ですから、全部で4行あります。では、要素"B"を見てみましょう。要素"B"は、
広瀬 - 5
広瀬 - 5
桜井 - 6
で、「広瀬 - 5」がダブってますから、ユニークな行数は2行です。要素"C"の、
佐々木 - 7
佐々木 - 8
は、どちらも等しくありませんから、これもユニークな行数は2行です。

う~ん、グループ化かぁ・・・意外といろんなことができますね。これだったら、リボンの目立つところに置いてあげてもいいかな。べ、別にイチ押し機能ってわけじゃないからね。けっこう使えるかなって、ちょっと思っただけだから。しょうがないから、ときどき使ってあげようかなって。