マージの種類
「VLOOKUP関数と同じことをする」で解説したように、「取得と変換」のマージ機能を使うと、VLOOKUP関数と同じようなことができます。しかし、マージ機能は決してVLOOKUP関数の代用として実装されているのではありません。「マージ=VLOOKUP」とは思わないでください。ただ、似たようなことも実現できるというだけです。そもそもデータベースの世界では、複数のテーブルを結合(マージ)することが多いです。それがマージ機能です。実を言えばVLOOKUP関数だって、立派なデータベース機能であり、やっていることは「別のテーブルからデータを取り出して結合している」ようなものです。ただExcelは、純粋なデータベースソフトではなく、表計算ソフトですから、やり方や考え方や見せ方などが表計算的なだけです。ここでは「取得と変換」のマージ機能で、どんなことができるのかを解説します。ただ、はじめにお断りしておきますが、私はデータベースの専門家ではありません。がんばって勉強はしていますが、データベースの専門家からすると「それは違ぇーよ」みたいなことを書くかもしれません。そんなときは、どうか温かい目で見守ってやってください。
複数のテーブルを用意します。ここでは、下記のようなテーブルを作りました。左が「テーブル1」で右が「テーブル2」です。
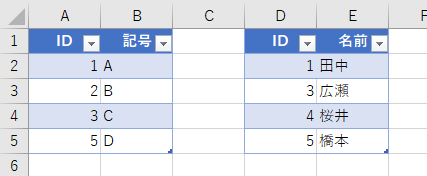
この2つのテーブルを結合します。しかし、よく見てください。テーブル1の「ID」には"4"がありません。テーブル2の「ID」では、"4"はありますが"2"がありません。この2つのテーブルを結合するのですが、もし両方の「ID」が同じだったら、下図のように話は簡単です。
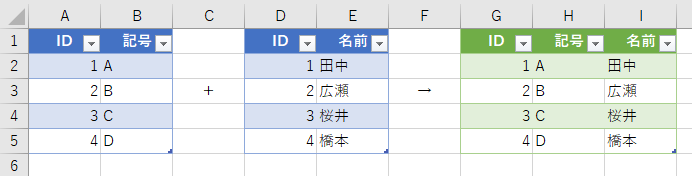
しかし、テーブル1とテーブル2で「ID」が異なっていた場合、どのように結合するのかという話です。まずは、2つのテーブルをPower Queryエディタに読み込みます。このへんは「ブック内の複数テーブルを操作する」をご覧ください。
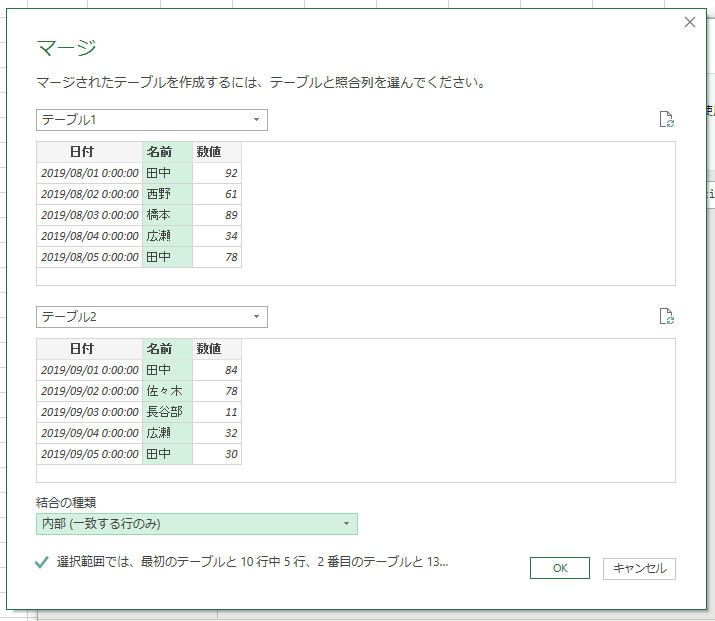
[クエリのマージ]をクリックします。実行すると[マージ]画面が表示されます。マージするテーブルとして「テーブル2」を選択し、照合列は「ID」を選択します。
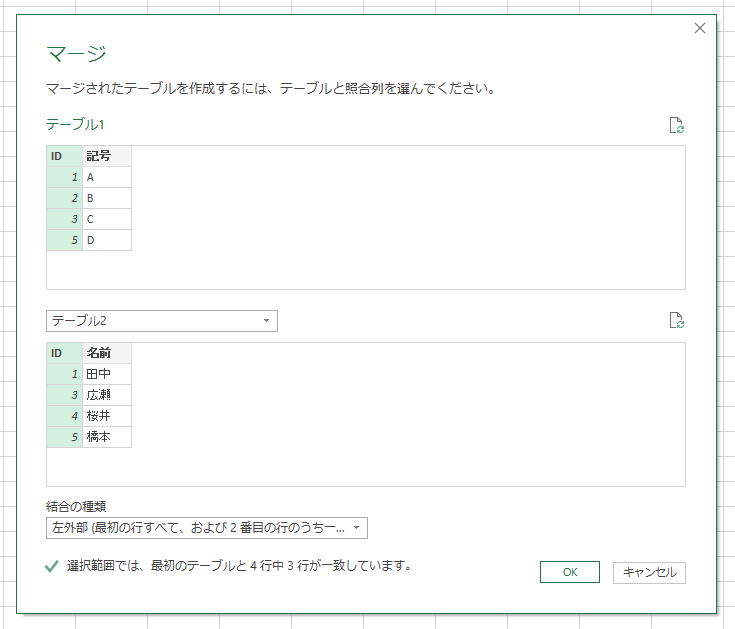
画面下部に「結合の種類」リストがあります。

ここでは、6種類の結合方法を選択できます。
- 左外部(最初の行すべて、および2番目の行のうち一致するもの)
- 右外部(2番目の行すべて、および最初の行のうち一致するもの)
- 完全外部(両方の行すべて)
- 内部(一致する行のみ)
- 左反(最初の行のみ)
- 右反(2番目の行のみ)
順番に解説します。
左外部(最初の行すべて、および2番目の行のうち一致するもの)
まず、Excel的に言うなら、これがVLOOKUP関数と同じ働きをする結合です。"左外部"という言葉から、データベース系の方でしたら想像できるでしょう。データベースでいうところの「LEFT OUTER JOIN」です。データベース的な考えが超苦手な全Excelユーザーは、ここで悩むかもしれませんけど、この"LEFT"というのは、物理的に(たとえばシート上の)"左側にあるテーブル"という意味ではありません。SQLのSELECT文を書くとき、左に書くテーブルだから"LEFT"です。ちなみに、SQLだと次のようになるのかな(違ってたらごめんなさい)。
SELECT * FROM テーブル1 LEFT OUTER JOIN テーブル2 ON テーブル1.ID = テーブル2.ID
FROMで指定したテーブル1が、左に書かれていますよね。だから"LEFT"です。まあ、簿記の"借方"と"貸方"みたいに、意味は考えない方がいいです。
にしても、この「左外部(最初の行すべて、および2番目の行のうち一致するもの)」は、括弧の中の説明が分かりにくいです。「最初の行」と言われたら、Excelユーザーだったら全員「1行目」と考えますよね。でも、違うんです。これは、次のような意味です。
「最初に指定したテーブルの行すべて、および2番目に指定したテーブルの行のうち一致するもの」
わざと誤解させるように書いてあるとしか思えません。助詞の使い方も悪いし、日本語のクオリティとしては最低ですね。いずれにしても、これがExcelのVLOOKUP関数みたいな結合です。やってみましょう。
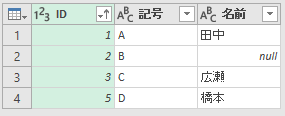
"null"というのは"該当なし"みたいなものです。比較しやすいように、結合した結果をシート上に読み込んでみます。
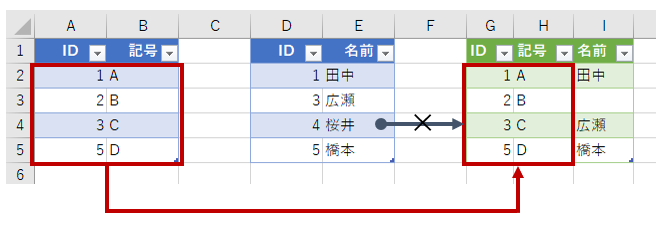
左外部(LEFT OUTER JOIN)は、左で(最初に)指定したテーブルのデータは全部表示します。G列には、A列と同じ「1・2・3・5」が並んでいます。「2」の名前が空欄なのは、テーブル2に「2」が存在しないからです。VLOOKUP関数でしたらエラーになっていることでしょう。注目すべきは、テーブル2の「4」です。「4」はテーブル1の「ID」(A列)に存在しません。左で(最初に)指定したテーブル1に存在しないので、結果にも表示されません。これが左外部(LEFT OUTER JOIN)です。左で(最初に)指定したテーブルを中心に考える、みたいな感じです。
右外部(2番目の行すべて、および最初の行のうち一致するもの)
左があれば右もあります。今度は、右外部でやってみます。
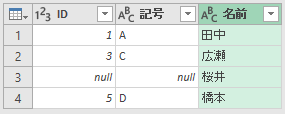
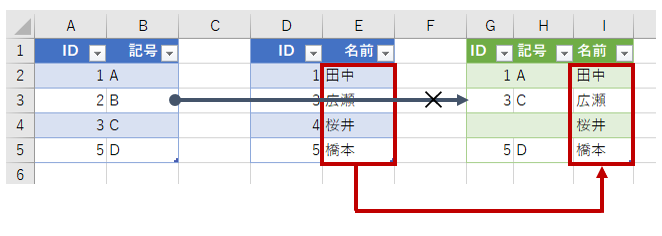
今度は、右で(2番目に)指定したテーブルを中心に考えます。まず、右で(2番目に)指定したテーブルのデータは全部表示します。「名前」列が全員表示されていますね。全員表示ですから、とうぜん"桜井"も表示されます。しかし、"桜井"に該当する(テーブル1の)「ID」と「記号」は存在しません。だから、空欄のままです。注目すべきは、テーブル1の「2」です。「2」はテーブル2に存在しません。だから表示されません。あくまで、テーブル2を中心とした考え方です。これが右外部です。ちなみにデータベース的には「RIGHT OUTER JOIN」といいます。
ちょっと個人的な感想です。私がデータベースをよく理解していないからだと思いますが、この右外部だと、下図のような結果になると思っていました。
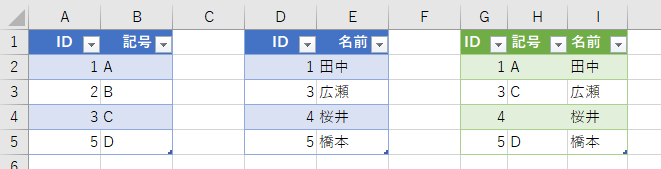
テーブル2には、"桜井"に該当する「ID」の「4」があるじゃないですか。だったら、結果の「ID」に表示されてもいいのではないかと。いえ、単純に予想と違ったというだけです。深い意味はありません。データベース的な難しい話でいじめないでくださいね。はい、ごめんなさい、忘れてください。
完全外部(両方の行すべて)
LEFT OUTER JOINとかRIGHT OUTER JOINのように"OUTER"と言われると、何か"外の"とか"以外の"みたいなイメージがあります。今までの左外部と右外部は、それぞれ、どちらかのテーブルを中心に考えて、その中心ではない別のテーブルが"OUTER"なのかなと。データベース的には間違っているかもしれませんけど、そんなイメージでした。だから、完全外部って、何が外部(OUTER)なんだろうって思いました。でも、そんなことどーでもいいんですね。とにかく"完全"なのですから、両方のテーブルとも完全に表示する結合です。「FULL OUTER JOIN」といいます。
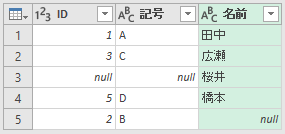
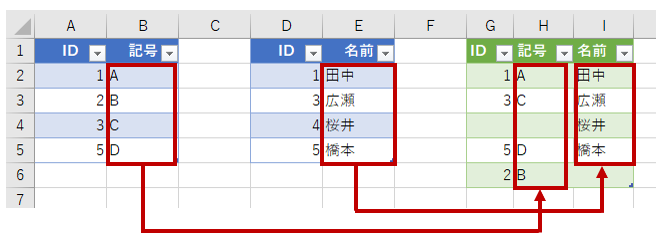
でもなあ、これもなあ、何で「4」が表示されないんだろ…。これじゃ"完全"になってねーじゃん…。結局「FROM テーブル1」ってことは「テーブル1から~」ってことで、照合列はあくまでテーブル1からしか持ってこないってことなのかな。ってことはやっぱ、FROMで指定したテーブル1の方が中心というか、メインというか、主役というか、そういうことなんだろうか。今度、データベース系の偉い人に聞いてみよう。
内部(一致する行のみ)
今までの「左外部」「右外部」「完全外部」は、その名の通り"外部結合"と呼ばれる仕組みです。どちらかに存在しないデータがあったとき、それをどーするって話です。今度の「内部」は"内部結合"です。データベース的には「INNER JOIN」と呼ばれます。やってみましょう。
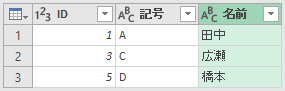
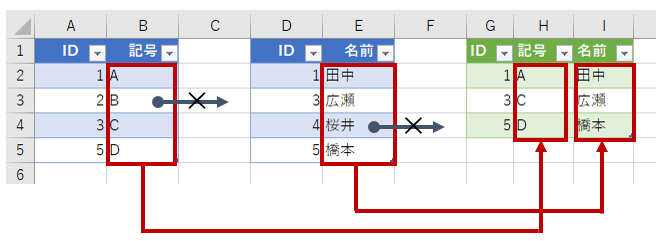
内部(INNER JOIN)では、両方のテーブルに存在するデータだけが表示されます。テーブル1の「2」はテーブル2に存在しません。だから結果には表示されません。同様に、テーブル2の「4」はテーブル1にありません。だから、これも結果には表示されません。これが内部結合です。
左反(最初の行のみ)
まず「最初の行のみ」というのは、「最初に指定したテーブルの行のみ」という意味です。つまり、左で(最初に)指定したテーブルを対象にするのですけど、それだったら「左外部」と同じです。こちらは"反"という文字が含まれていますので、「~ではない」「Not」的な意味合いです。つまり、テーブル1にある全データのうち、テーブル2に存在しないデータだけを表示しますよってことです。
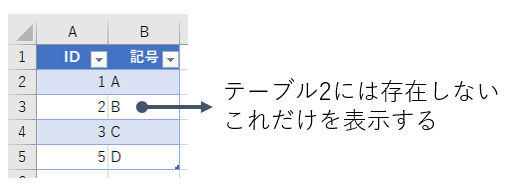

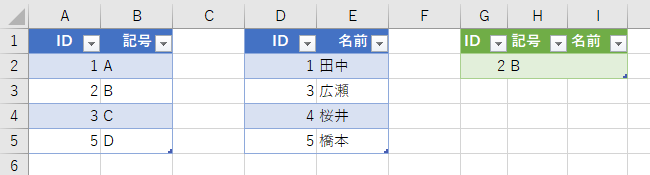
これは、「なんちゃら JOIN」みたいなデータベース用語ないのかな。調べたけど分かりませんでした。ちなみに、M言語ではTable.NestedJoin関数にJoinKind.LeftAntiという引数が指定されていました。"Anti"が「反対の」という意味ですから、「LEFFT ANTI JOIN」かな。違うか。
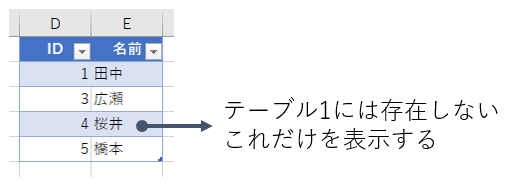
右反(2番目の行のみ)
ここまでくれば、もう分かりますね。これは、テーブル2にある全データのうち、テーブル1に存在しないデータだけを表示します。

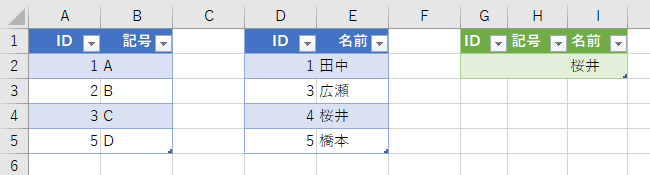
使用例
すぐ思いつくケースで、実際にやってみましょう。ここでは、次のデータを使います。左が「テーブル1」で右が「テーブル2」とします。
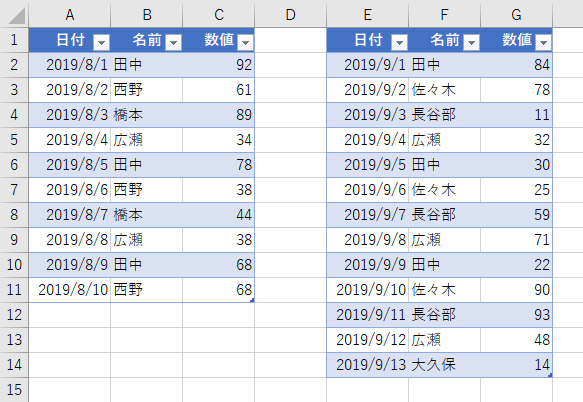
なお、「日付」と「数値」は今回使いません。1列しかないと寂しいので飾りみたいなもんです。この2つのテーブルで、次のようなデータ(名前)を調べてみます。
- テーブル1(8月)にはあるけど、テーブル2(9月)にはない名前
- テーブル1(8月)にはないけど、テーブル2(9月)にはある名前
- テーブル1(8月)とテーブル2(9月)の両方にある名前
先に答えを書いておきます。
- テーブル1(8月)にはあるけど、テーブル2(9月)にはない名前 → 西野, 橋本
- テーブル1(8月)にはないけど、テーブル2(9月)にはある名前 → 佐々木, 長谷部, 大久保
- テーブル1(8月)とテーブル2(9月)の両方にある名前 → 田中, 広瀬
テーブル1(8月)にはあるけど、テーブル2(9月)にはない名前
2つのテーブルをPower Queryエディタに読み込みます。手順は「ブック内の複数テーブルを操作する」をご覧ください。
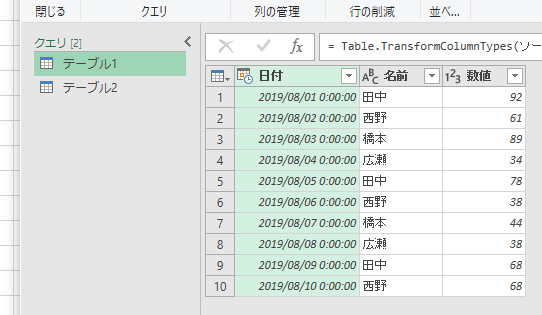
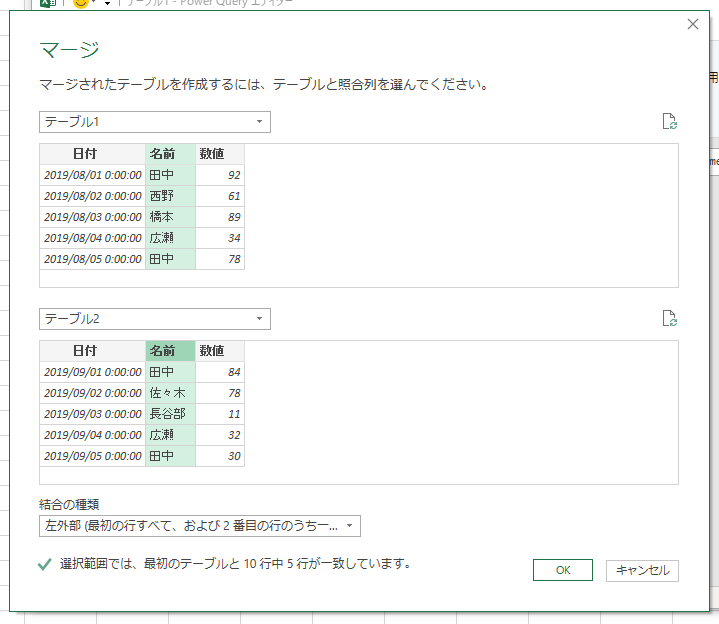
「日付」列のデータ型が「日付/時刻」になっていますが、この列は、どうせ後で削除しますから、このままにしておきます。さて、テーブル1が選択されている状態で[クエリのマージ]の[新規としてクエリをマージ]をクリックします。今回は、特に必然性はないですけど、新しいクエリとして作ります。
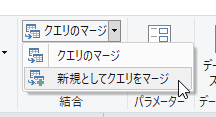
照合列に「名前」を指定して、左外部でマージします。
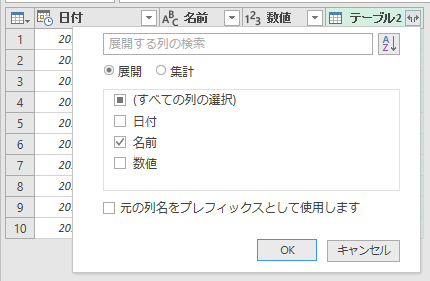
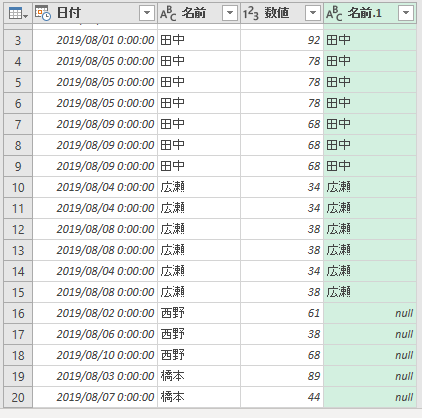
今マージした右端の列「名前.1」に注目してください。テーブル1(8月)に登場する名前のうち"西野"と"橋本"は、テーブル2(9月)に存在しません。だから"null"となっています。つまり、マージした結果が"null"の名前は「8月にあるけど9月にない」ということです。マージした右端列「名前.1」を"null"で絞り込みます。
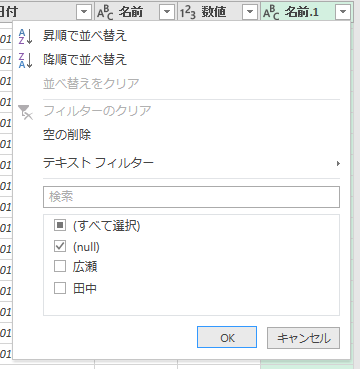
「名前」列以外は不要ですから削除します。
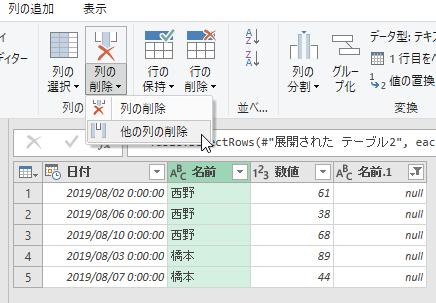
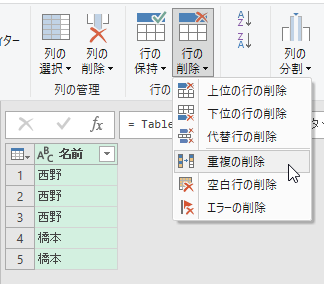
「名前」列に同じ名前が重複していますので、重複行を削除しましょう。[行の削除]の[重複の削除]をクリックします。
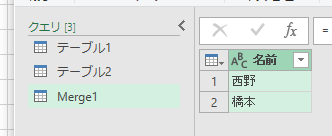
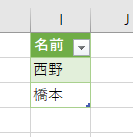
完成です。適当なセルに読み込みます。
テーブル1(8月)にはないけど、テーブル2(9月)にはある名前
これも考え方は同じです。テーブル2を選択して、それにテーブル1をマージしてやれば、まったく同じ操作で作れます。ただ、せっかくですから右外部でやってみましょう。テーブル1を選択した状態で[クエリのマージ]-[新規としてクエリをマージ]を実行します。照合列を「名前」にして、結合の種類で「右外部」を選択します。
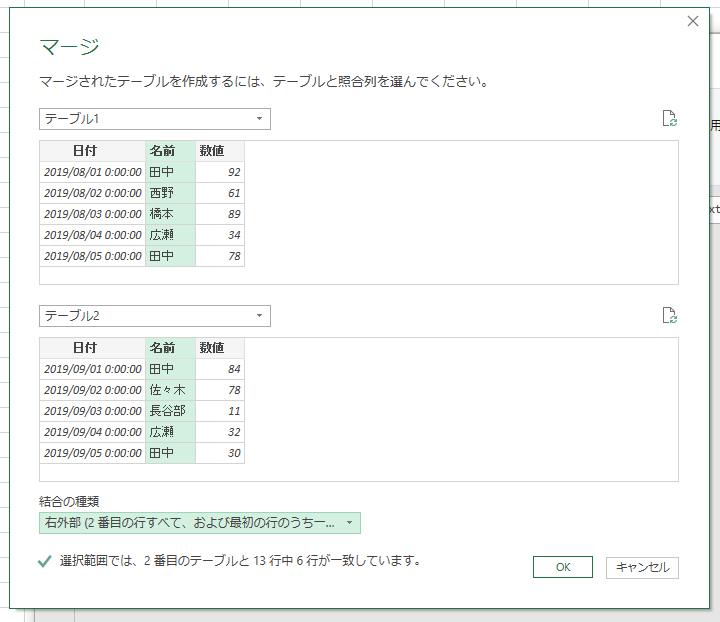
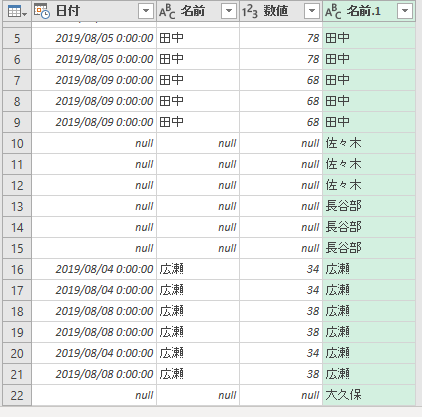
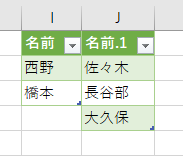
「8月にはないけど9月にある」のは"佐々木"と"長谷部"と"大久保"です。これら3人は「日付」「名前」「数値」の列が"null"になります。いずれかの列を"null"で絞り込みます。
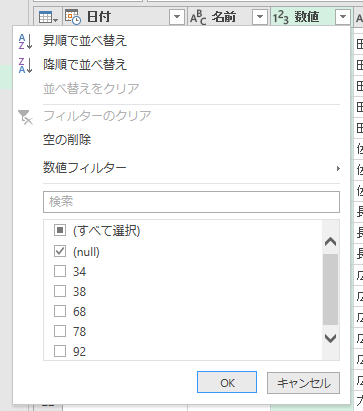
右端の「名前.1」列以外を削除して、重複行を削除します。
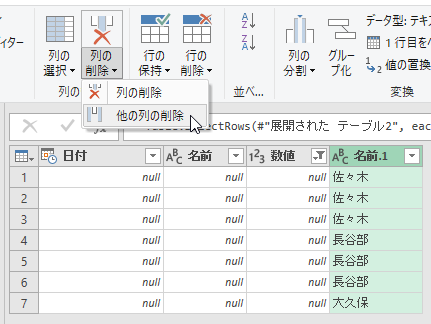
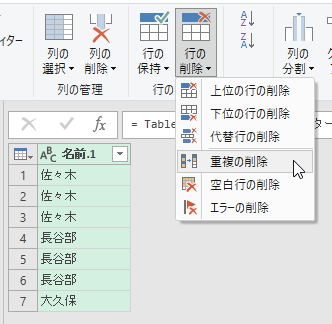
適当なセルに読み込んで完成です。
テーブル1(8月)とテーブル2(9月)の両方にある名前
ここでは、両方のテーブルに存在する名前を知りたいので、内部を使います。
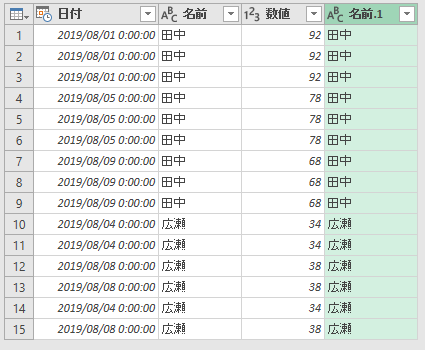
不要な列を削除して、重複行を削除します。
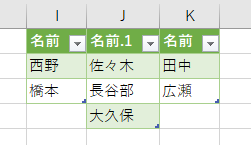
応用しだいで、いろいろなことができます。ただ、Excelユーザーにはけっこう難しいです。どういうテーブル同士を、どう結合すると、どんな結果を返すのか、それをイメージできないと作れません。そして、そのイメージは、今までのExcelでは養われないものです。実務で作り込むには、試行錯誤するなりの覚悟が必要でしょうね。