タイトル(ヘッダ)が存在しないCSVデータ
これ、先日のセミナーで質問されました。いやぁ、実務ってのは、いろんなことがありますね~こういうのは、実際にユーザーの話を聞かないと分かりませんね。
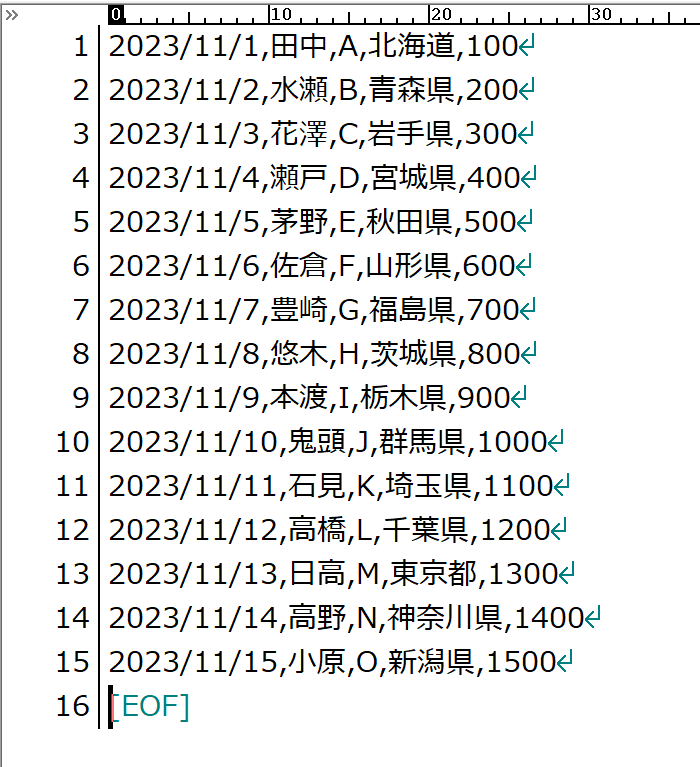
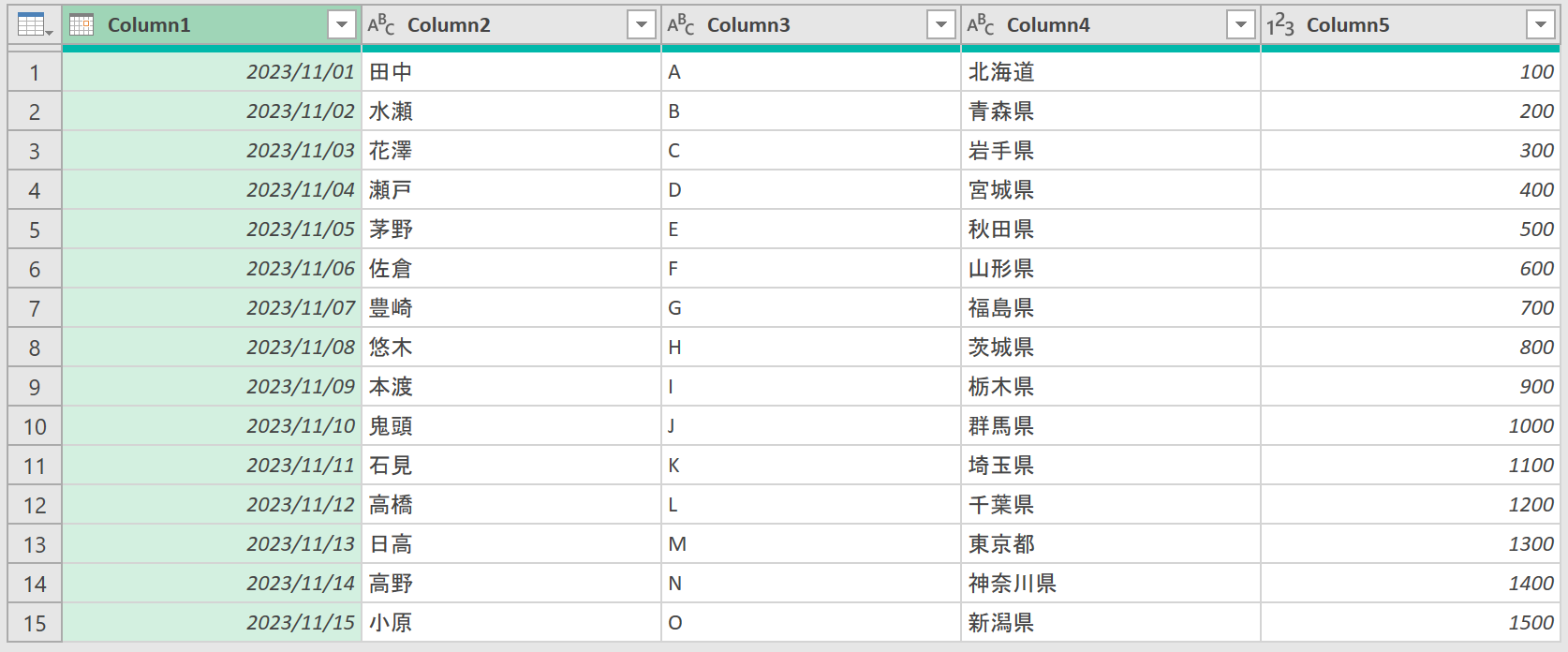
毎月基幹システムから、データがCSV形式で提供されるのですが、そのデータには、上図のようにヘッダ(タイトル)が存在しないのだそうです。この時点で「はぁ?」です。だったら、どの列が何のデータか分からないじゃん。なんでヘッダを付けて出力してくれないの?って。そしたら「ヘッダ(タイトル)はヘッダとして、別のCSVで提供されるんです」と。つまり、こういうことです。

毎月、これら2つのCSVを合体させてから処理をしているそうです。もしかして、情シスから嫌われているのでしょうか?イジメとか?さて、これをPower Queryで何とかしたいと。やってみましょう。ここでは、2つのCSVが次のように同一フォルダに存在するとします。この方が、データファイルが更新されたとき、自動的に処理されるので便利でしょう。

まず「フォルダーから」で、データファイルとヘッダファイルが存在しているフォルダを指定します。
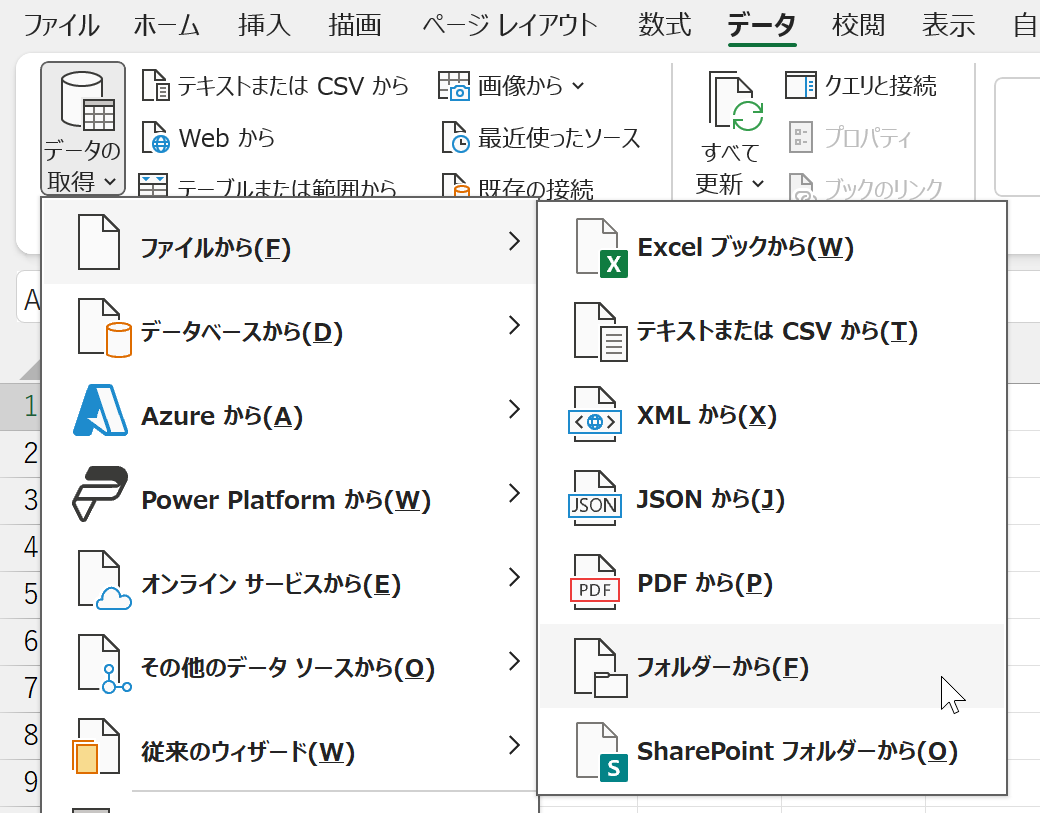
これで、うまいこと結合してくれたら嬉しいのですが、そんなに単純ではありません。ここで[データの変換]ボタンをクリックします。

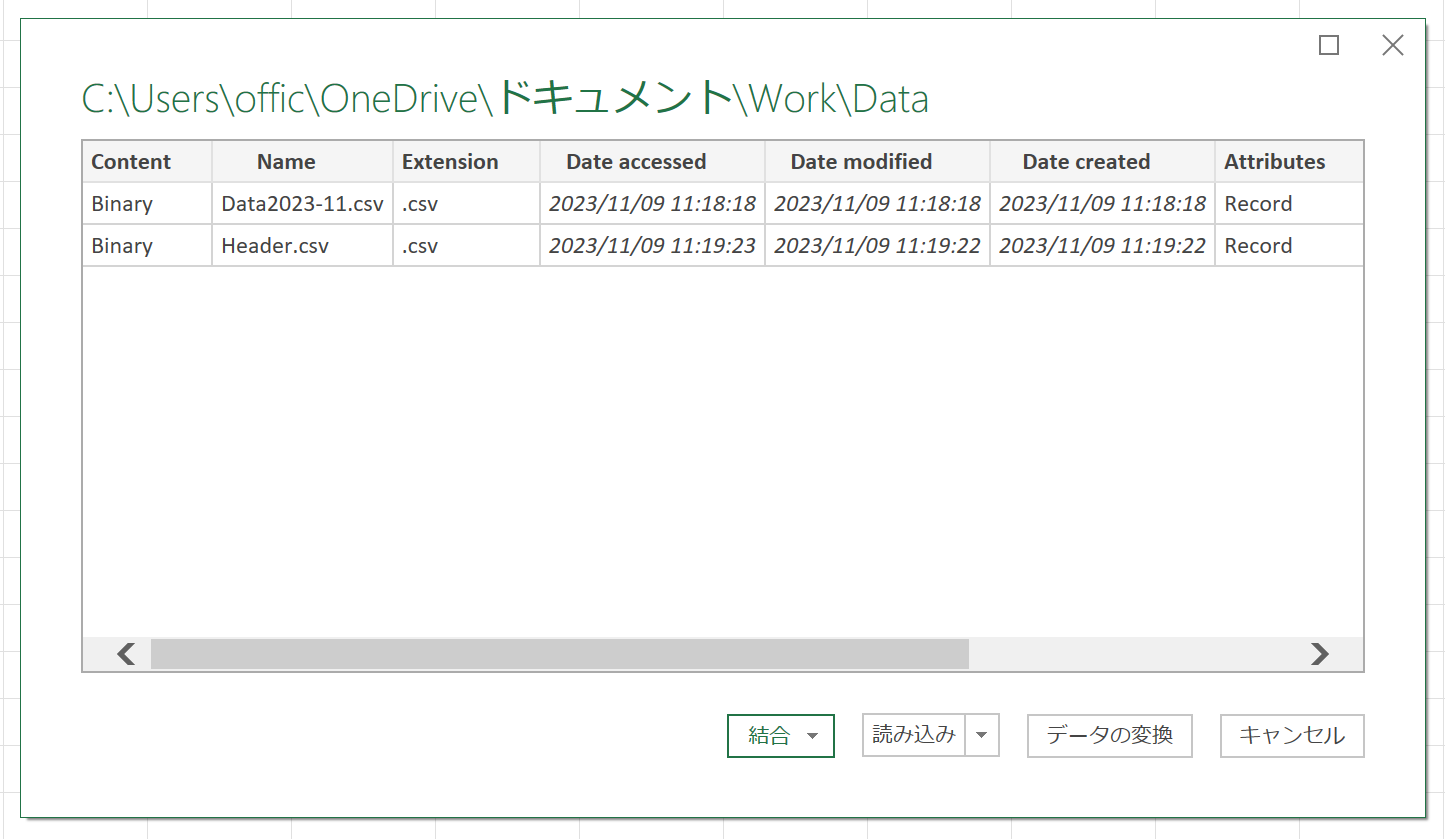
実行すると、上図のように2つのCSVファイルに関するリストが、Power Queryエディタに取得されます。ここから「Header.csv」を除外して、残りのデータファイルだけを取得するようにします。そのへんの仕組みは下記ページをご覧ください。
[Name]列のフィルタで[テキストフィルター]-[指定の値を含まない]をクリックします。
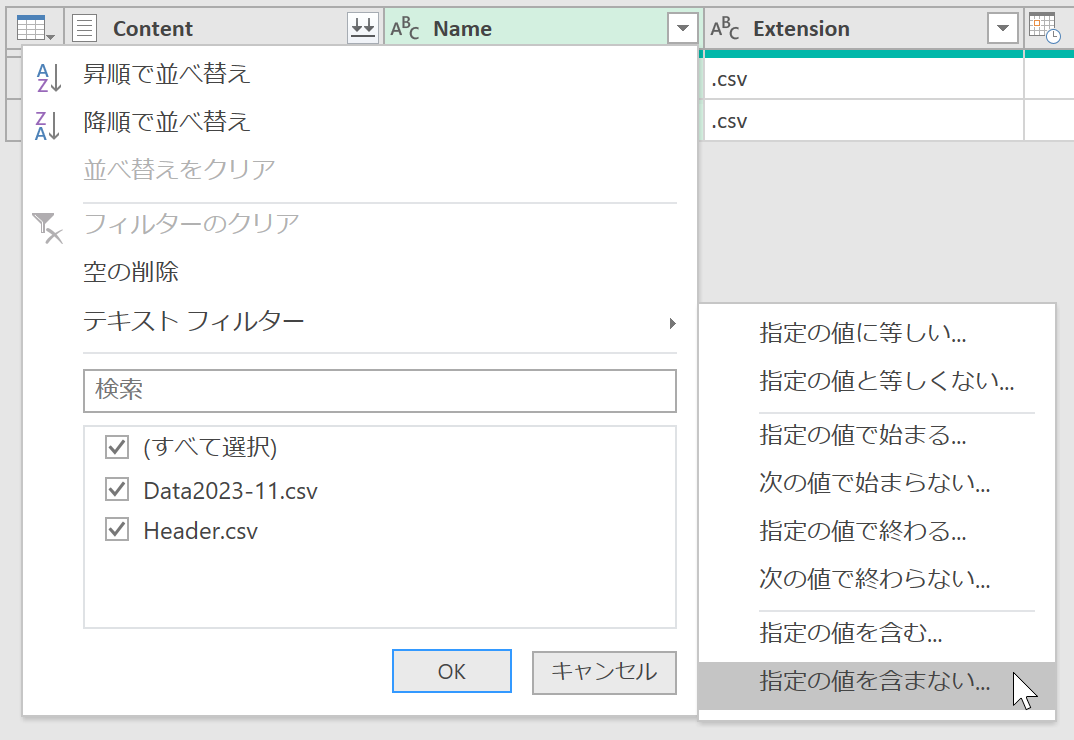
実行すると[行のフィルター]ダイアログボックスが表示されます。
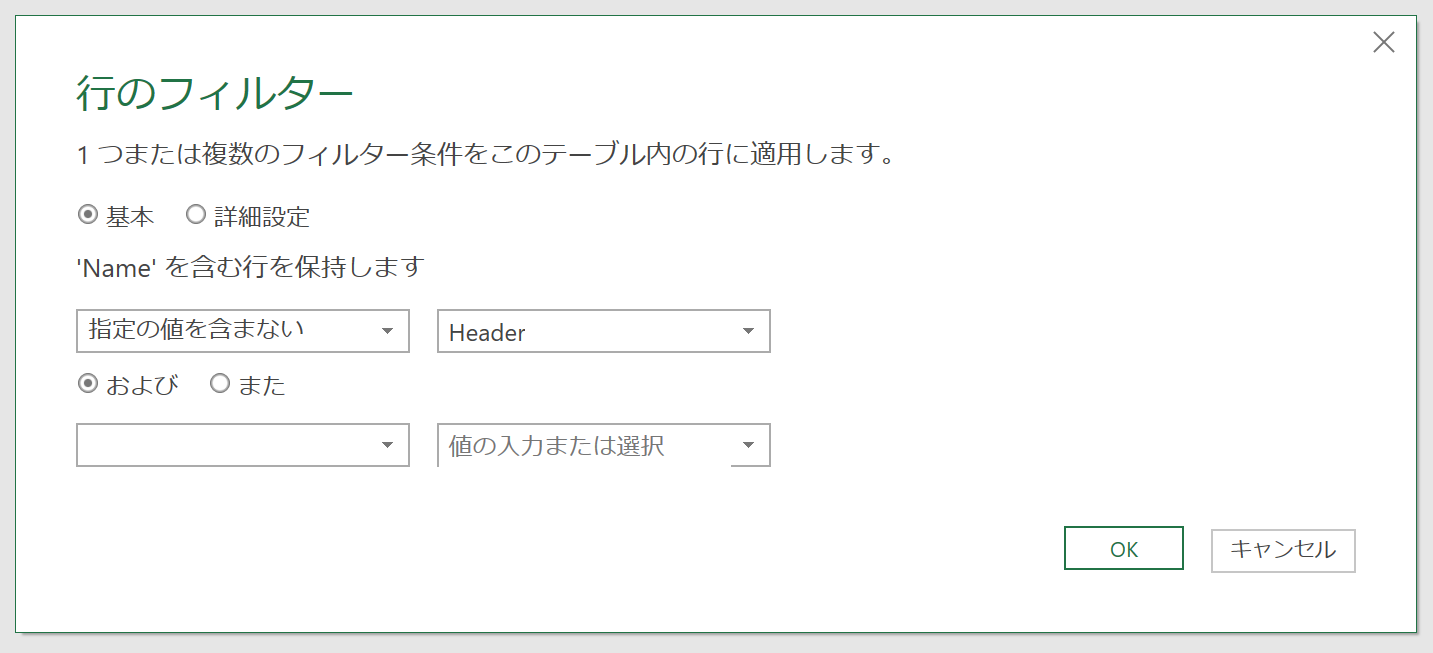
[指定の値を含まない]ボックスの右に「Header」と入力しました。ここは「Header.csv」としてもいいですし、何なら「Header.csv」"と等しくない"でも今回はうまくいきます。ただ、こうしたファイル名などは変更される可能性もありますので、マージンを取って「Header」"と言う文字列を含まない"としました。これなら、今後ヘッダー情報の内容が変わったときなど「Header2023.csv」などのファイル名にしても大丈夫でしょう。[OK]ボタンをクリックすると、Power Queryエディタ上のリストに、データファイルだけがリストアップされますので[Content]列の[ファイルの結合]ボタンをクリックしてください。
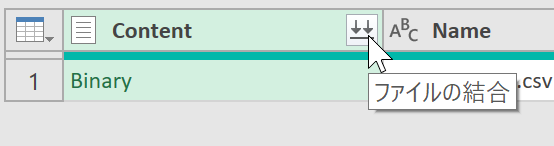
実行すると、データファイルが取得されます。
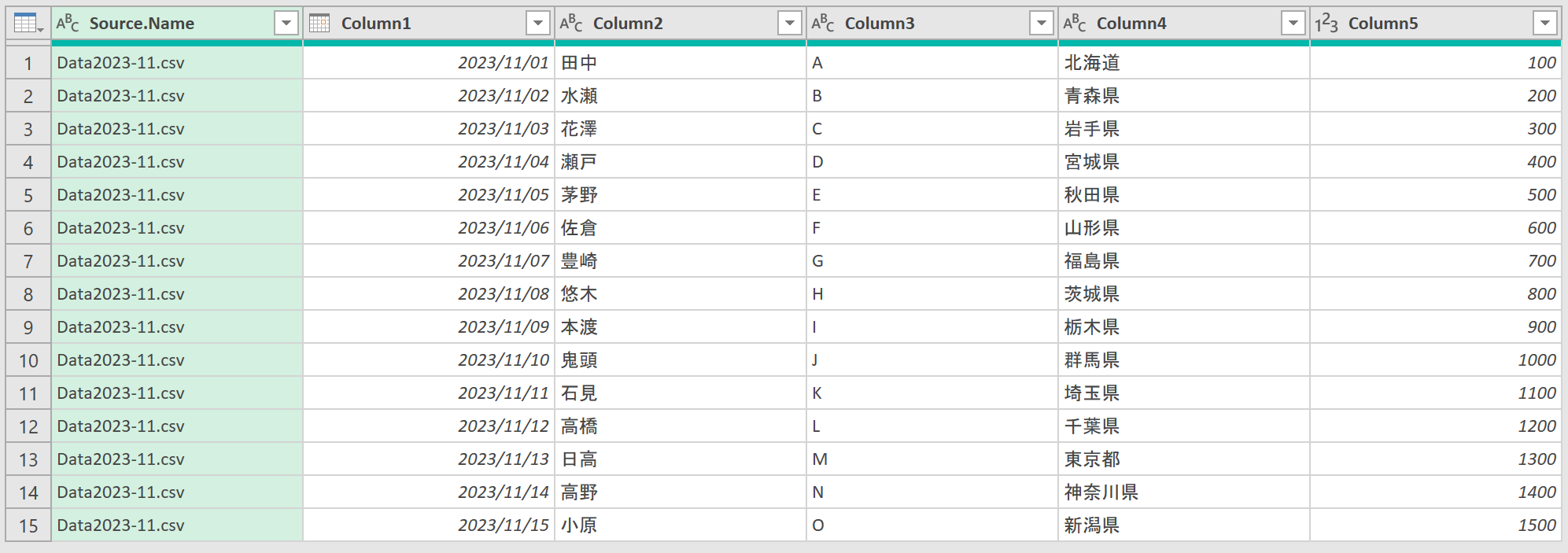
左端の[Source.Name]が自動的に追加されますが、今回は不要です。[Source.Name]列が選択されている状態で[列の削除]をクリックしてください。
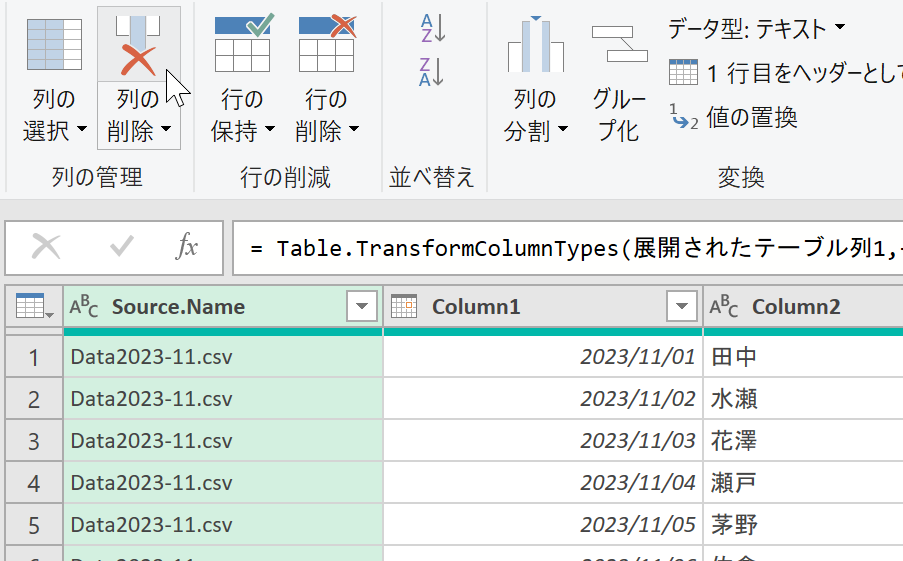
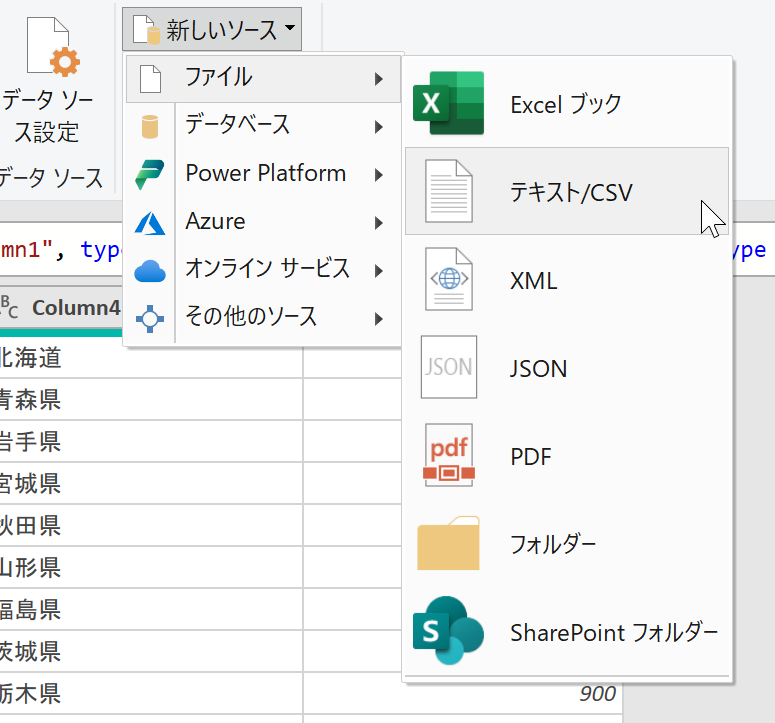
さて[新しいソース]で「Header.csv」を取得しましょう。
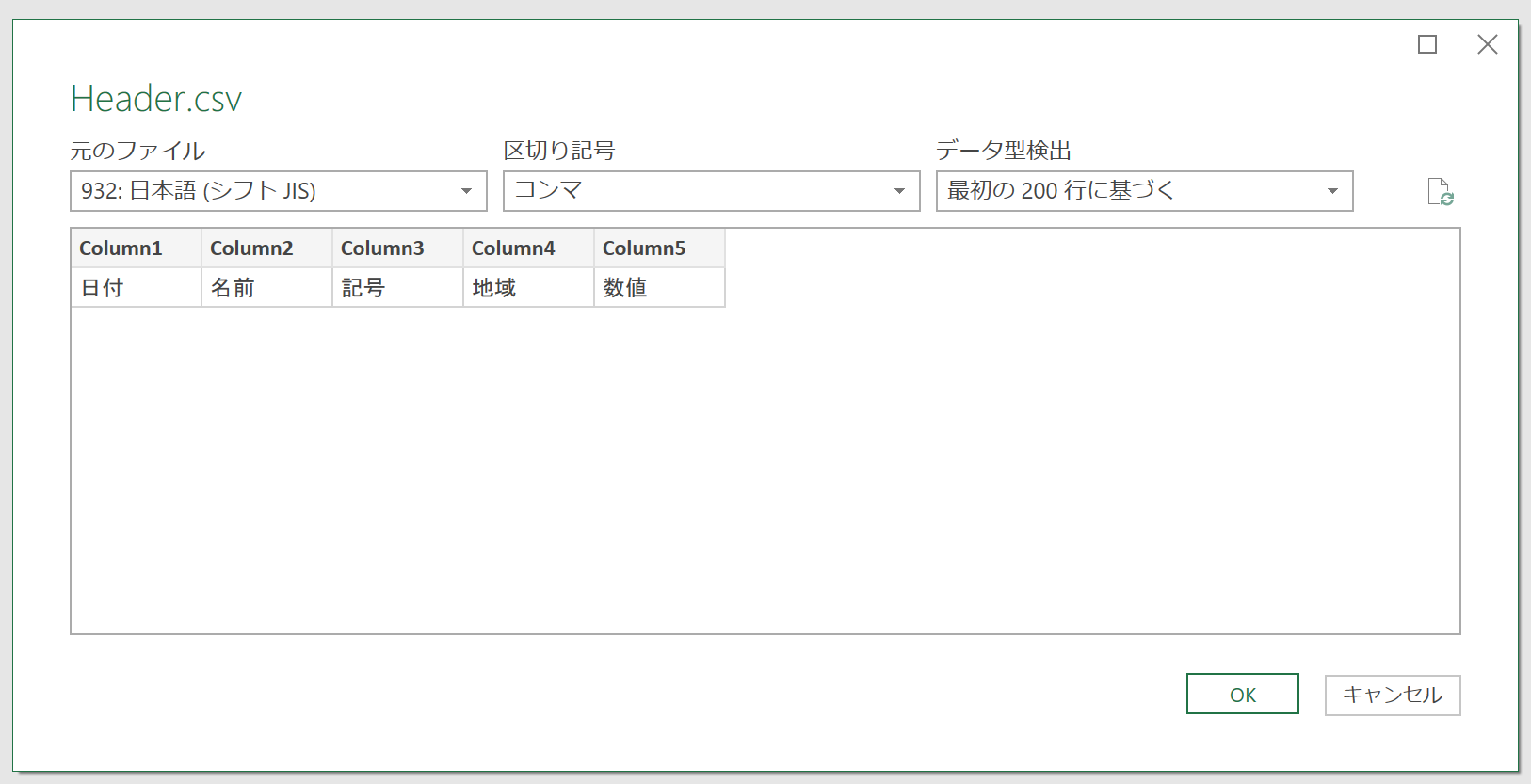
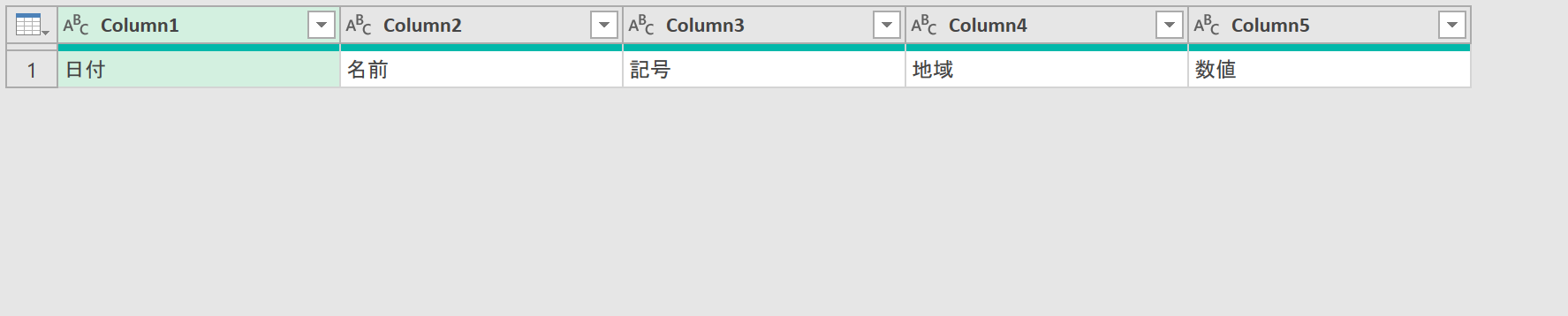
ちなみに「Header.csv」を取得したので、このクエリは[Header]という名前になります。最終的に完成したリストをExcel上に読み込むとき、新規シートの名前が[Header]になったり、読み込まれたテーブルの名前も[Header]となります。ちょっと何というか、あまり格好良くありません。シート名やテーブル名を後で変更してもいいですが、何ならここでクエリの名前を、何か分かりやすいものに変更するのも手ですね。まぁ、それは必須ではありませんし、とりあえず本稿の解説では[Header]で進めます。さて、クエリ[Header]が選択されている状態で[クエリの追加]をクリックします。
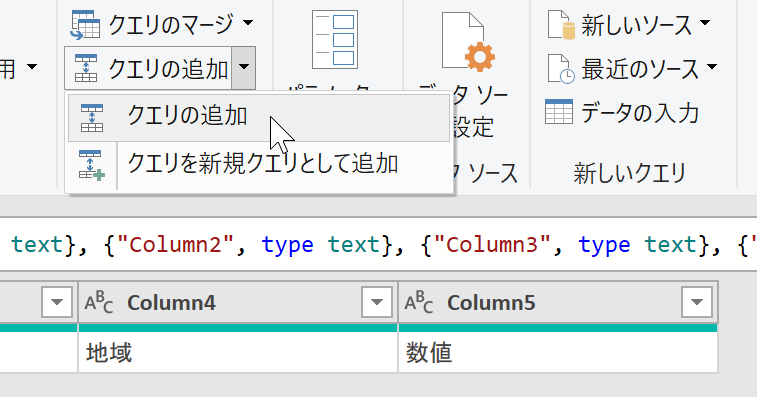
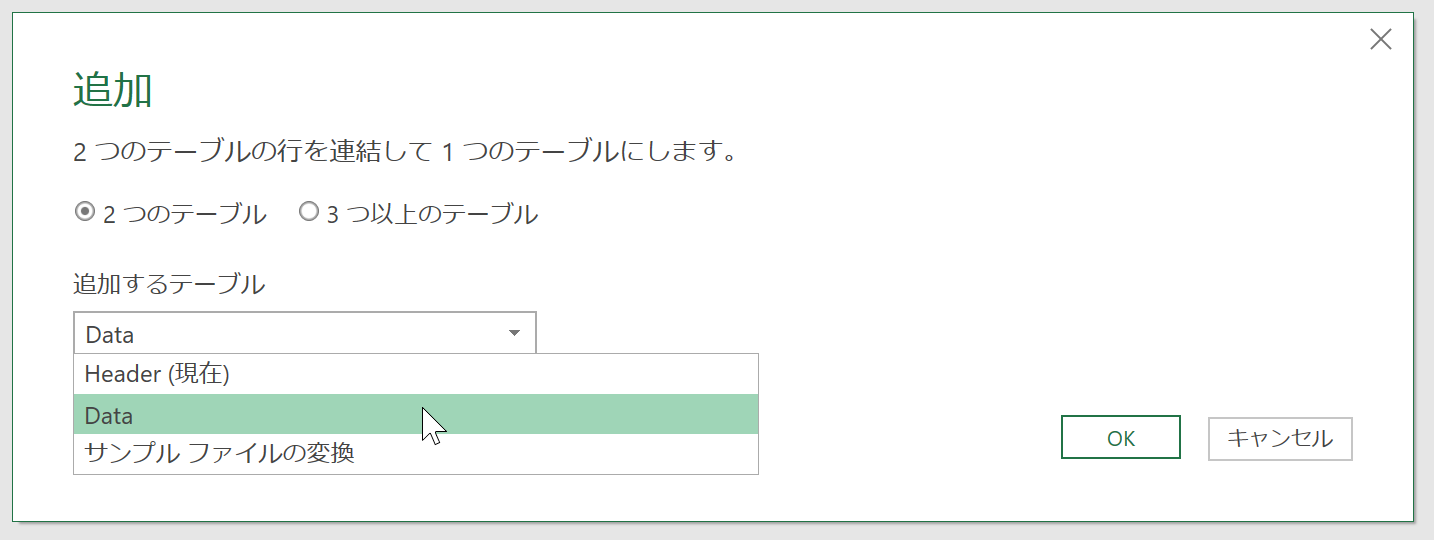
実行して表示される[追加]ダイアログボックスの[追加するテーブル]リストで、もうひとつのクエリ(ここではData)を選択して[OK]ボタンをクリックします。
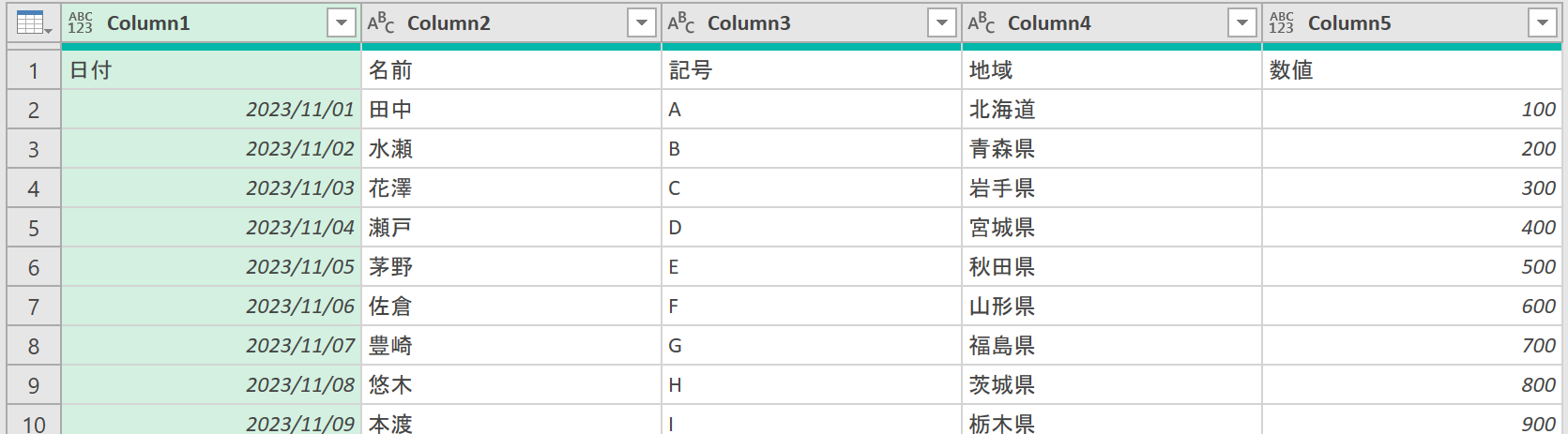
実行すると、ヘッダ情報とデータが縦に結合され、タイトルには「Column1・Column2・Column3…」が設定されます。
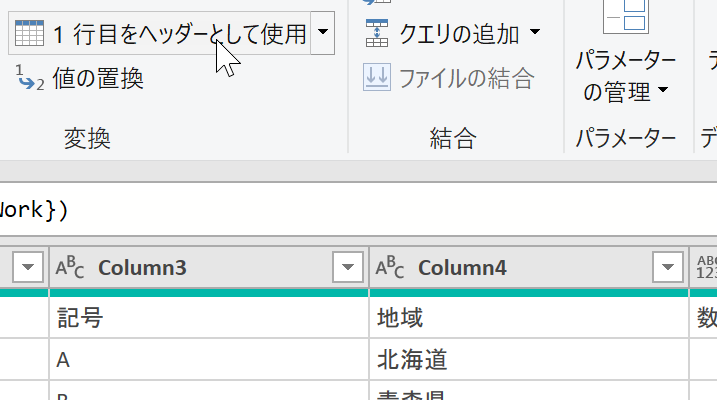
あとは[1行目をヘッダーとして使用]ボタンをクリックして完成です。
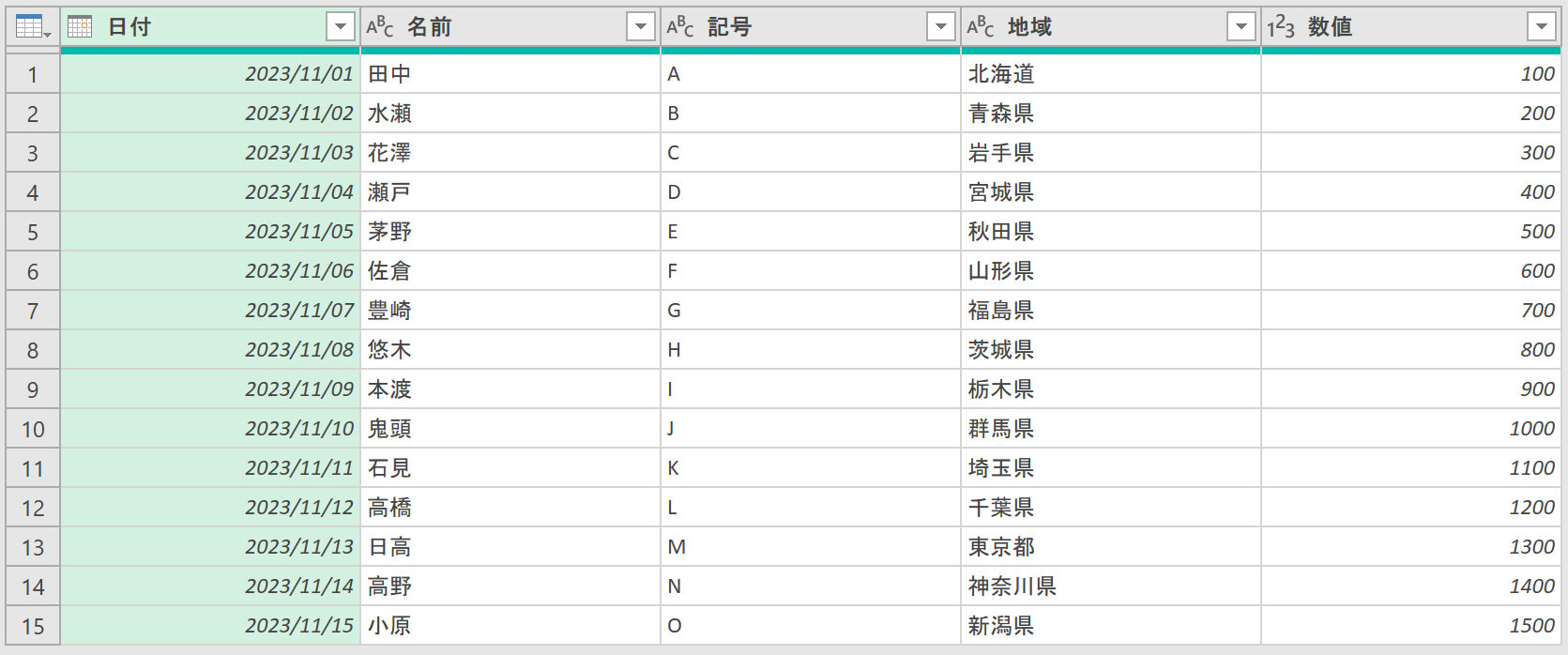
このクエリを[閉じて読み込む]などをクリックして、Excelに読み込んでください。
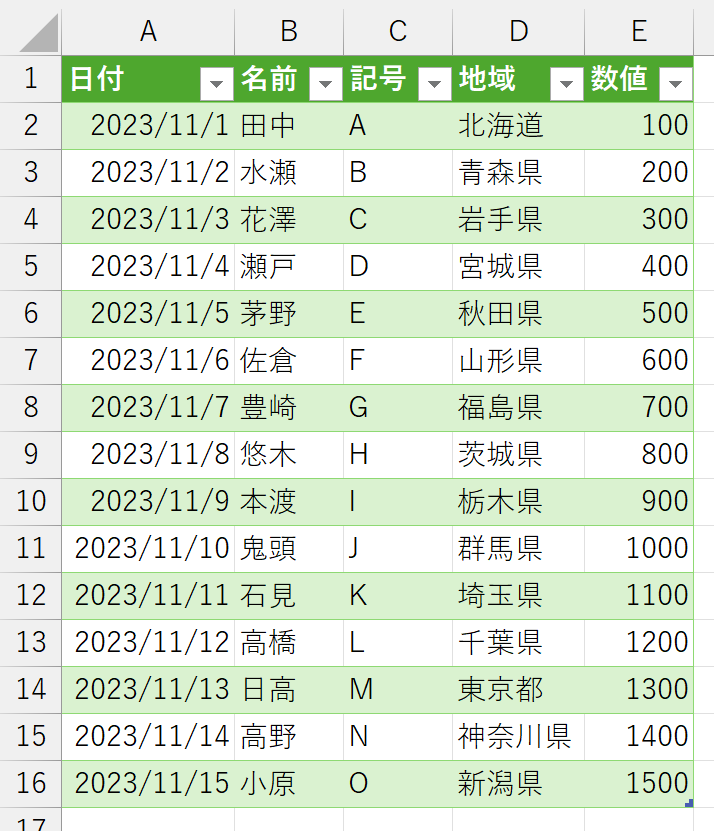
今回は、Power Queryの「フォルダーから」を使ったので、指定したフォルダ内のファイルを変えれば、新しいデータに更新可能です。

こうした処理についてセミナーで質問されたのですが、正直イレギュラーな、めったにない事例なのではと思いました。そしたら、同じくセミナーに参加していた吉本さんから「私も、そういう処理をやったことがありますよ」と教えていただきました。いやぁ、実務というのは教科書どおりにはいかないのだなと、あらためて強く感じた質問でした。