[フォルダーから]の注意
Power Queryを使うと、フォルダ内に存在する"すべてのデータ"あるいは"特定のデータ"を、簡単に結合することができます。詳しくは下記ページをご覧ください。
ただし、気付きにくいミスによって、思わぬトラブルを引き起こすこともあります。今回は、そのへんの仕組みを解説しますので、十分に注意してください。
まずは、正常な動作をお見せします。任意のフォルダ(ここではC:¥Work)に、いくつかのCSVファイルが保存されています。なお、ここでは、サンプルデータを作るのが簡単だという理由でCSVファイルにしましたが、もちろんExcelのブック(*.xlsx)でも同じです。

念のため、CSVファイルの中は、こんな感じです。どれでも同じですけど「4月.csv」を開いてみます。今回は、結果が分かりやすいように、各データの件数(行数)を少なくしています。

さて、[データ]タブ[データの取得]-[ファイルから]-[フォルダーから]を実行して、C:¥Workフォルダを指定します。
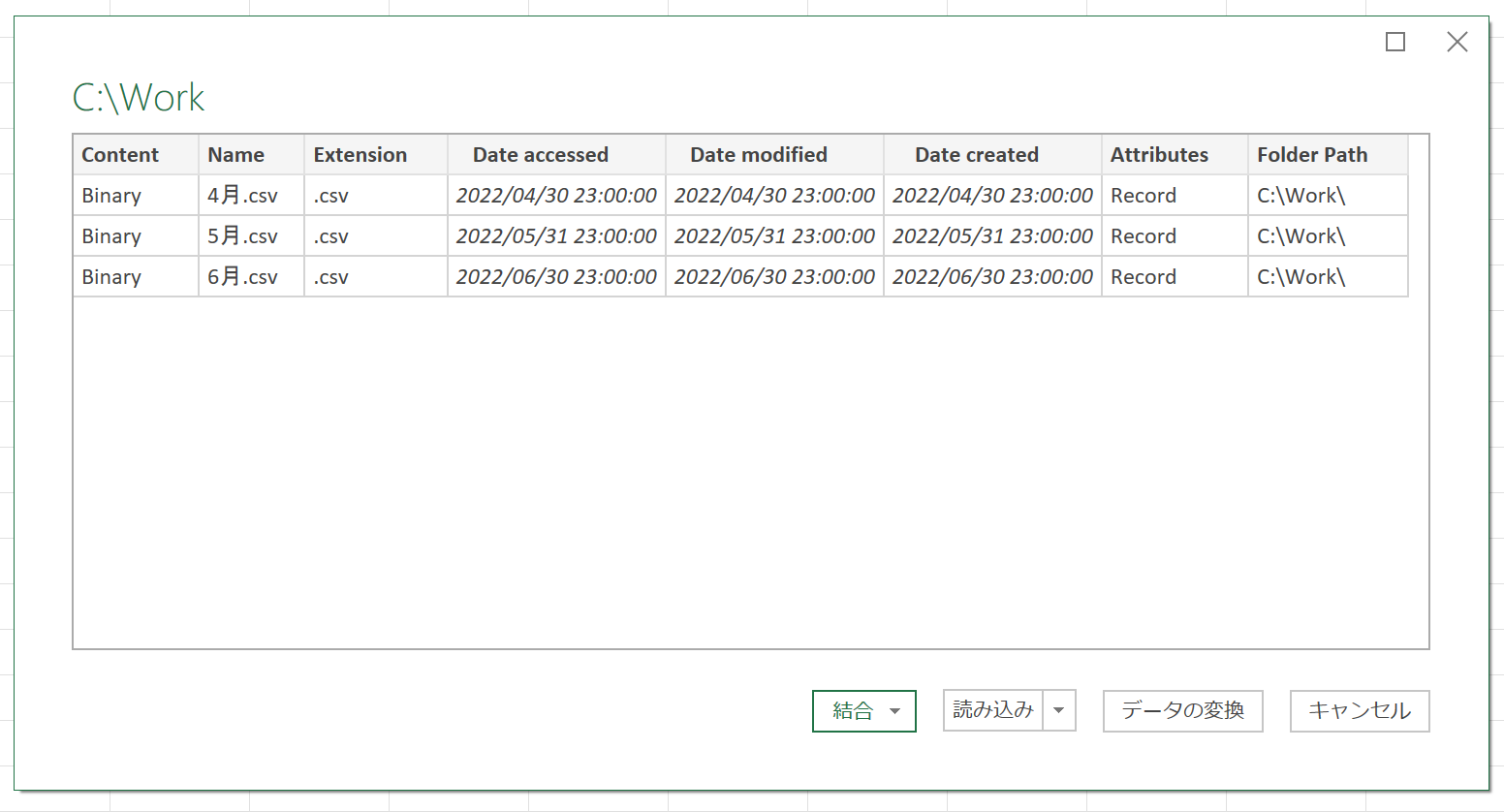
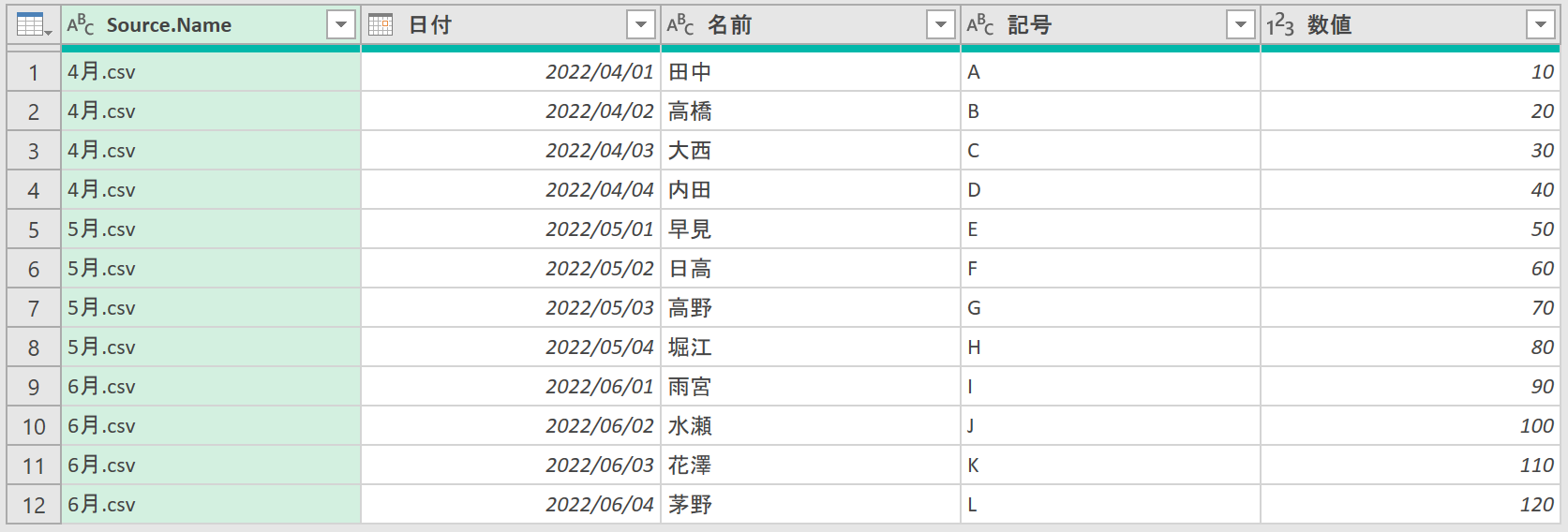
Power Queryエディタ上で、3つのデータが結合されていますので、これをExcelに読み込みます。
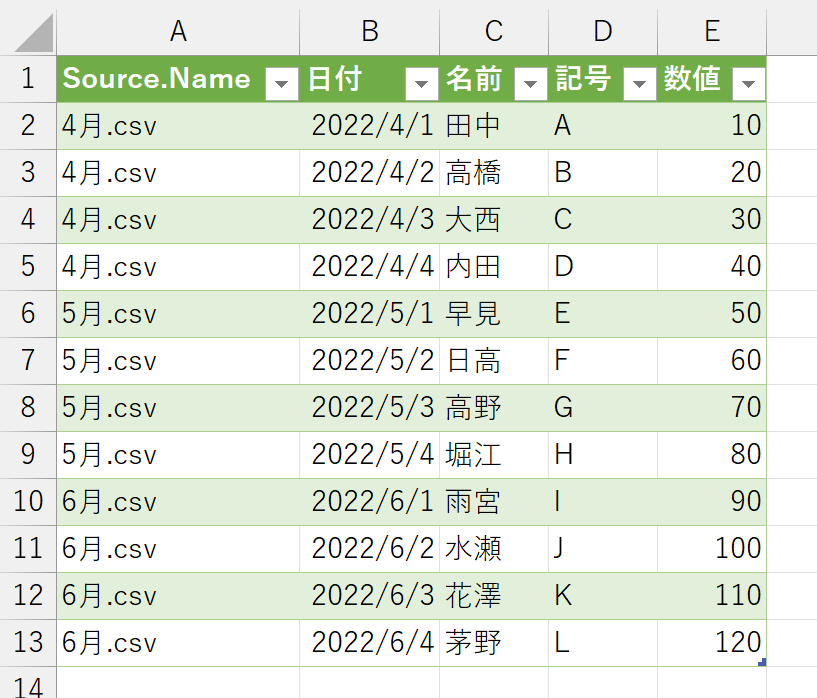
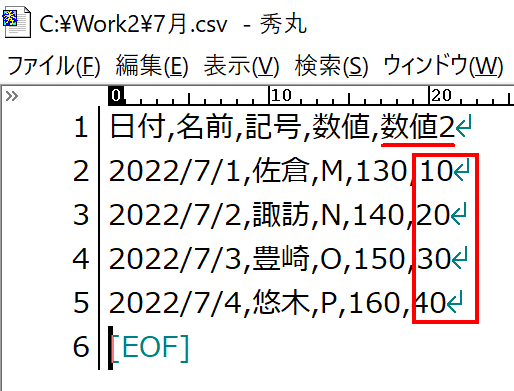
さて、このように複数のデータを結合するようなとき、翌月には新しいデータが提供されることが多いです。翌月になって「7月.csv」を受け取ったとしましょう。これを同じフォルダに入れておけば、あとは"更新"をすることで反映されるはずです。ところが!ここで思わぬ事態が起こりました。「7月.csv」から、新しい項目(列)が追加されたんです。

さあ、こういうとき、どーなるでしょう?というのが、今回のテーマです。
クエリの追加では
Power Queryでは、こうした"項目の増減"に対して、かなり柔軟に対応してくれます。ちょっと、やってみましょう。ここでは、次のデータで試してみます。
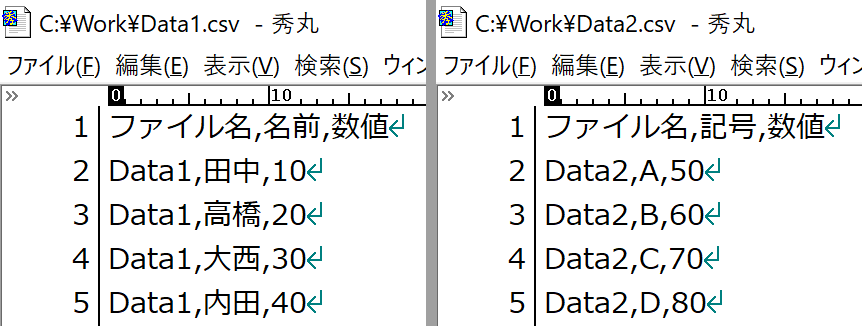
「Data1」には、"名前"があって"記号"がありません。対して「Data2」の方は、"名前"がなくて"記号"があります。なんか、あるなしクイズみたいですけど、このとき両者を結合したらどうなるのでしょう。これ、セミナーでもよく質問されます。
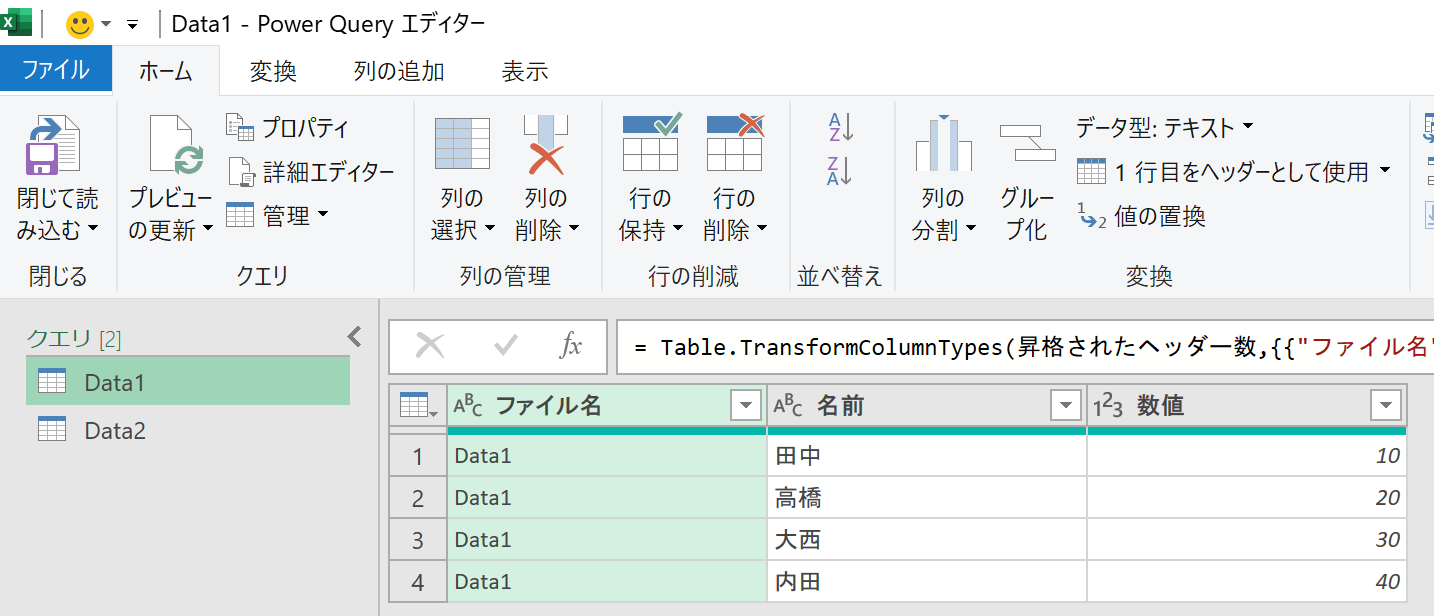
2つのCSVファイルをPower Queryエディタに取得して、[クエリの追加]を実行してみます。
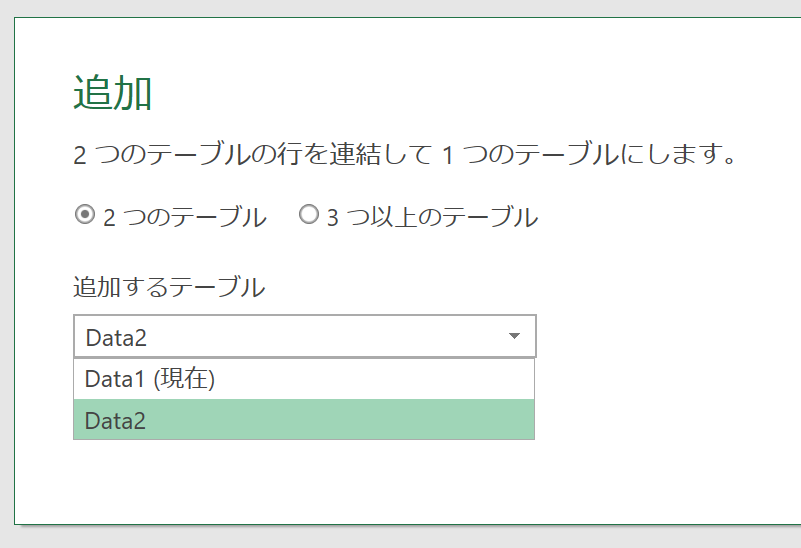
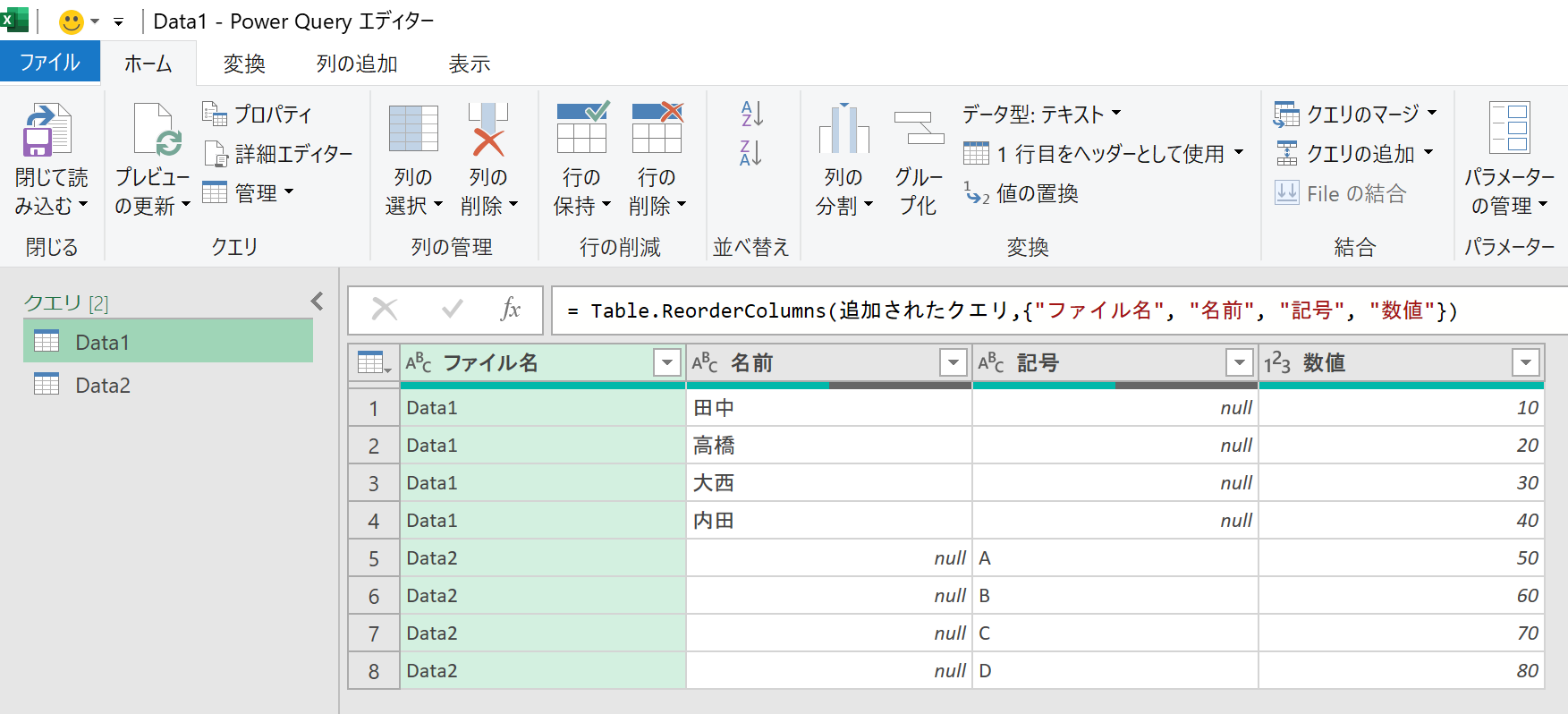
実行結果は上図のとおりです(見やすくするために、列位置を変更しました)。「Data2」には存在しなかった"名前"列ですが、この列がないと「Data1」のデータを表示できません。だから登場します。もちろん「Data1」に存在しない"記号"列も同様です。"記号"列がなかったら、「Data2」のデータを表示できません。データが存在しないところは"null"となっています。"null"とは"データが存在しない"とか"何もない"みたいな意味です。Excelでいうところの"ブランクセル"みたいなものです。
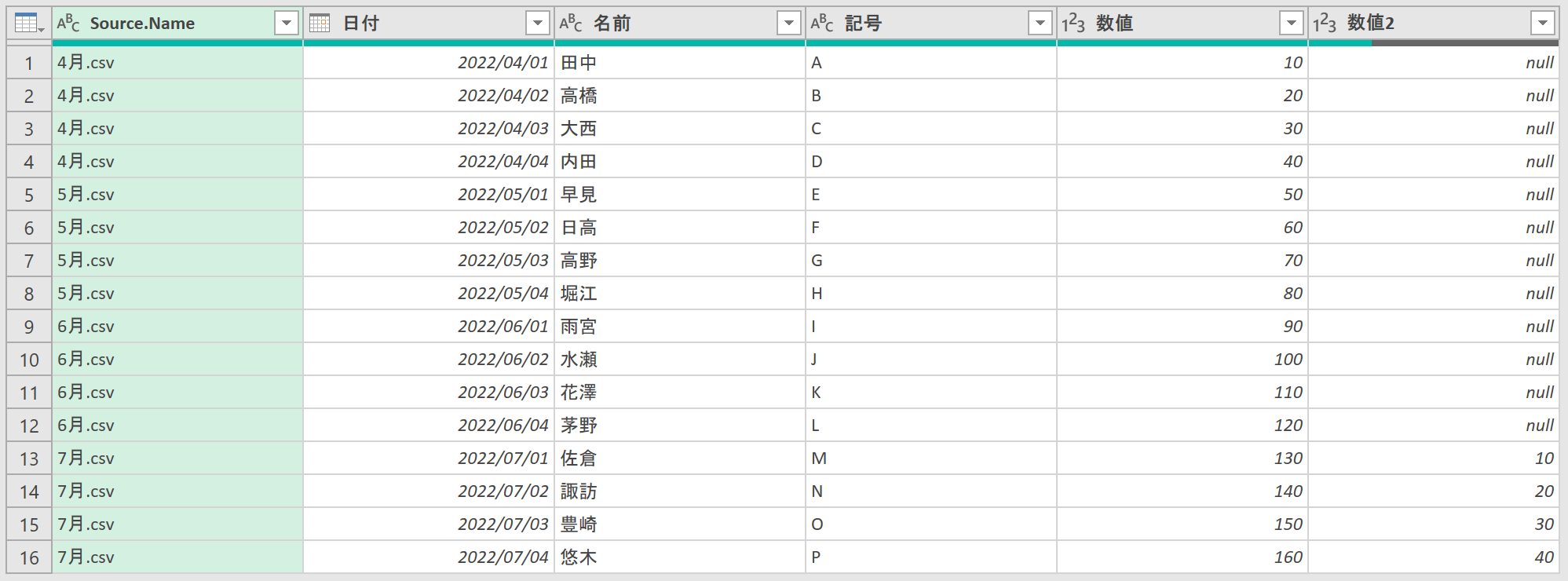
このように、Power Queryの「クエリの追加」では、あるファイルに存在する列は、別のファイルにないからといって無視されません。「クエリの追加」とは、簡単に言えば「複数のリストを、縦方向に結合」するような機能です。本稿でテーマにしている「フォルダーから」も、同じように「複数のリストを、縦方向に結合」してくれます。本来の正確な意味はともかく、ユーザーが「同じように動作するだろう」と考えるのは当然です。では、実際にためしてみましょう。上記のとおり、まずは「4月.csv」「5月.csv」「6月.csv」のファイルを処理しました。この3ファイルは、それぞれの項目が同じでした。そこに追加されたのが「7月.csv」です。もう一度お見せしますが、こちらには新しく「数値2」という列が追加されています。
テーブルを更新した結果は、下図のとおりです。
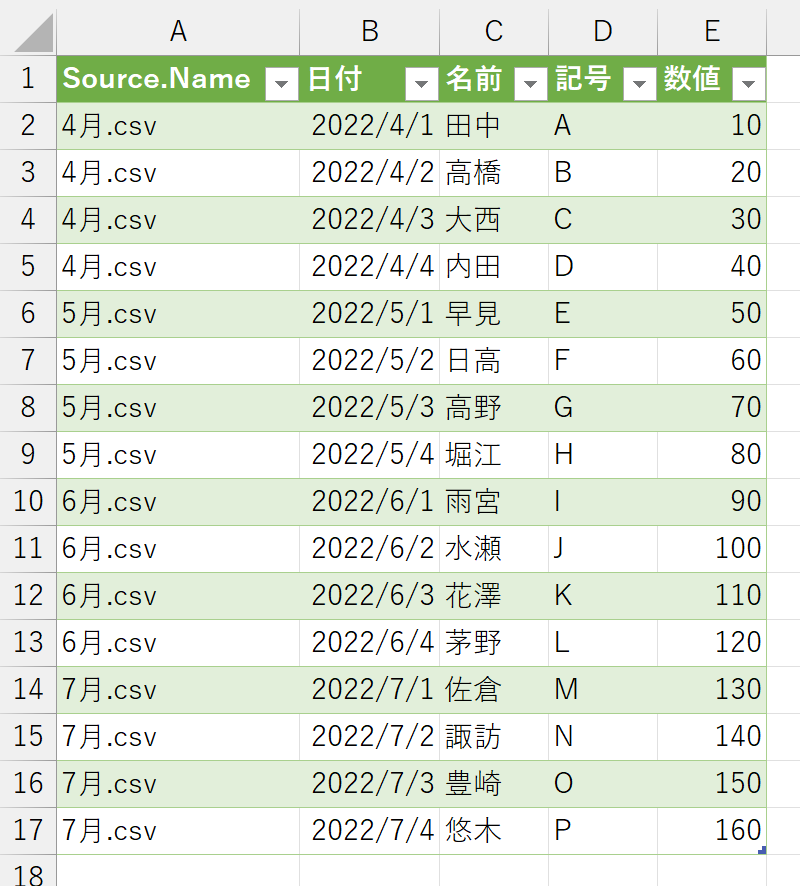
ここまで読んできた方でしたら、何となく予想できたのではありませんか。もしかしたら、上手くいかねんじゃね?って。そのとおりです。後から追加されたファイルに新登場した列は、更新しても読み込まれません。この件、ちゃんと理解していないと、実務では大変なことになりかねません。こうした、定期的に受け取るデータってのは、基幹システムなどから出力されることが多いです。その、基幹システム側で、何か、ちょっとした変更が行われたとき、それを知らされないことだってあるでしょう。すると、思わぬ失敗をしてしまいます。
原因と解決策
どうして「7月.csv」に追加された新しい列"数値2"が読み込まれなかったのか?実はここまでの解説で、あえてお見せしなかった画面があります。もう一度最初から手順を紹介しましょう。なお、今回はすでに「7月.csv」がC:\Workフォルダに存在する状態で行います。まずは、[データ]タブ[データの取得]-[ファイルから]-[フォルダーから]を実行して、C:¥Workフォルダを指定します。
[開く]ボタンをクリックすると、フォルダ内のファイルがリストアップされます。
[データの結合と変換]をクリックすると、下図の画面が表示されます。
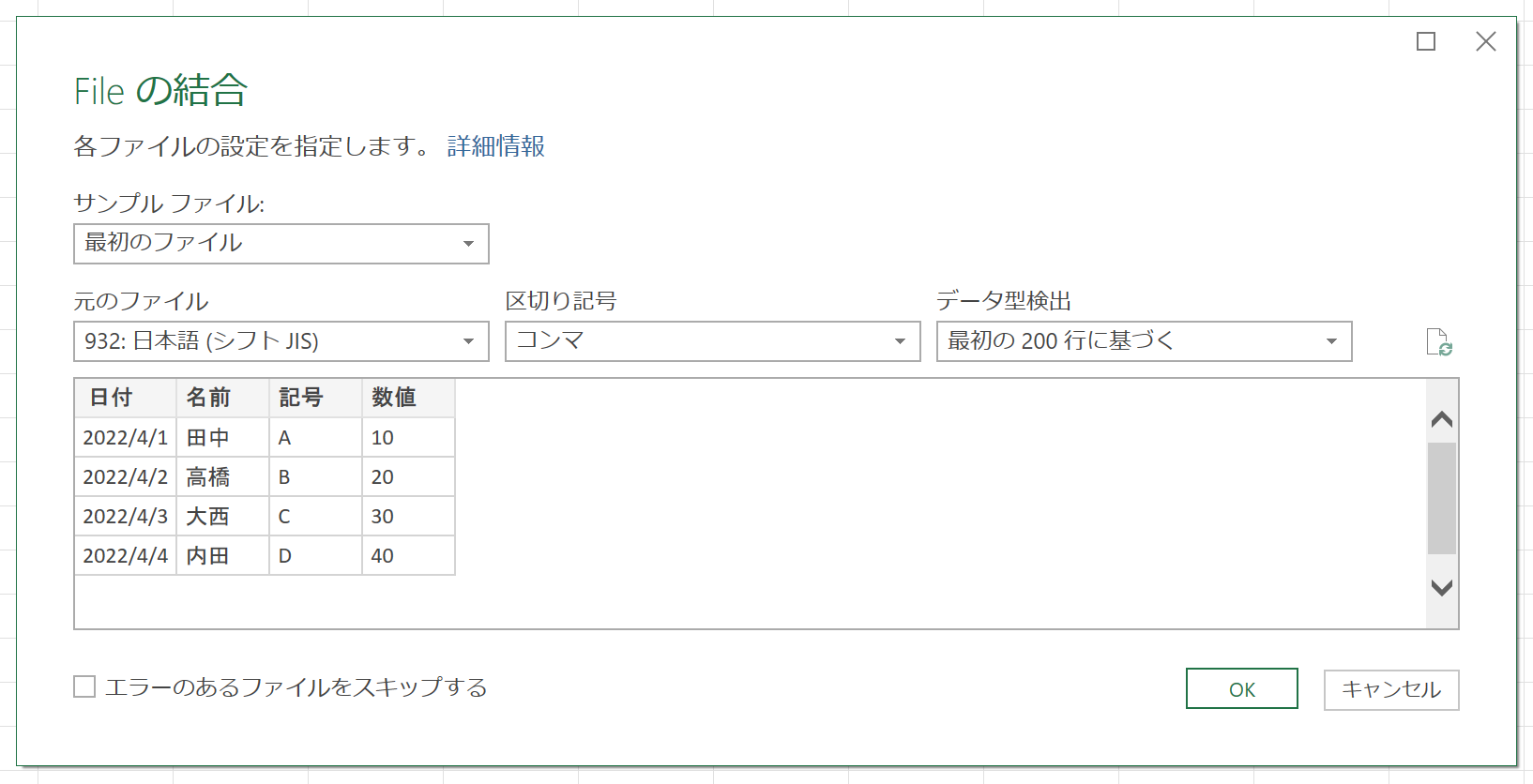
実は、ここまでの解説では、この画面を表示していませんでした。[フォルダーから]を実行し、データの変換を行うと、必ずこの画面が表示されます。これから処理しようとしているファイルは、こんな感じですよという、いわば"プレビュー画面"みたいなものです。これ、CSVファイルを単体で開くときにも表示されるのですが、そのときは一般的に、スルーすることが多いです。なので、[フォルダーから]を実行したときにも、あまり意識していないのでは。よく見ると、画面の左上あたりに[サンプルファイル]という項目があり、「最初のファイル」が選択されています。▼ボタンをクリックすると、フォルダ内のファイルを選択できます。
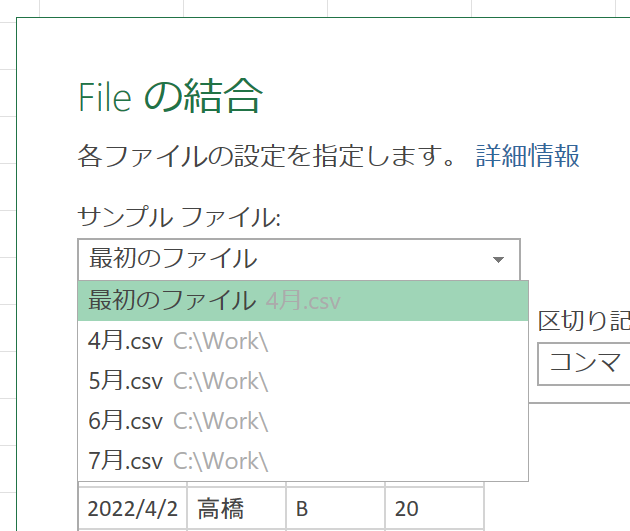
つまり、Power Queryは[フォルダーから]を実行するにあたり、任意のファイルをひとつ決めて、そのファイル内を解析してプレビューに表示してくれたわけです。そして「こんな感じですけど、いいですか」と確認してきます。この"こんな感じ"というのは、文字コードや区切り記号だけでなく「このような列構成ですけど、いいですか?よろしければ、ほかのファイルも、これと同じ列構成で処理します」ということです。試しに、[サンプルファイル]が「4月.csv」のまま[OK]ボタンをクリックしてみましょう。
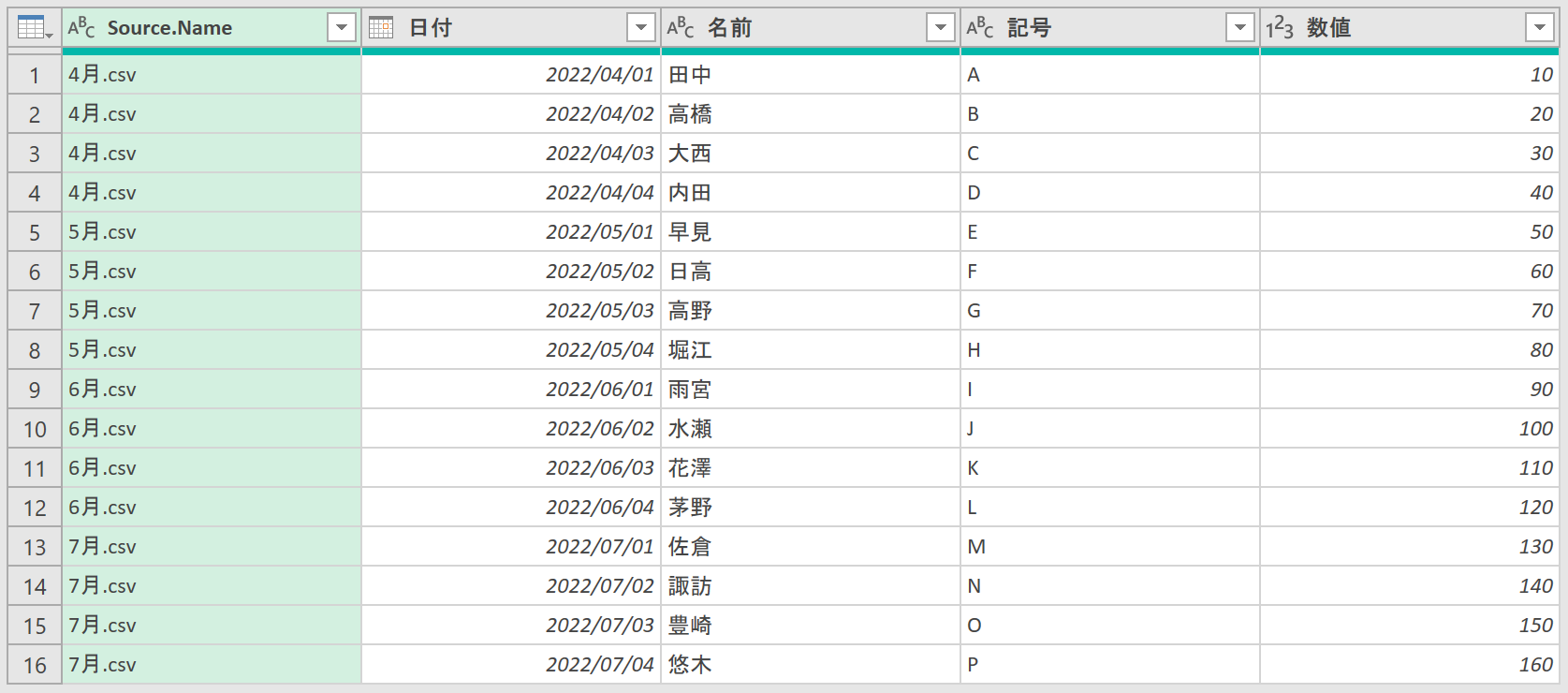
「4月.csv」から「7月.csv」まで、C:\Workフォルダ内に存在するすべてのファイルが読み込まれていますが、よく見るとこの時点ですでに、「7月.csv」の"数値2"列がありません。では、少し戻って、プレビュー画面の[サンプルファイル]で、今度は「7月.csv」を選択してみます。
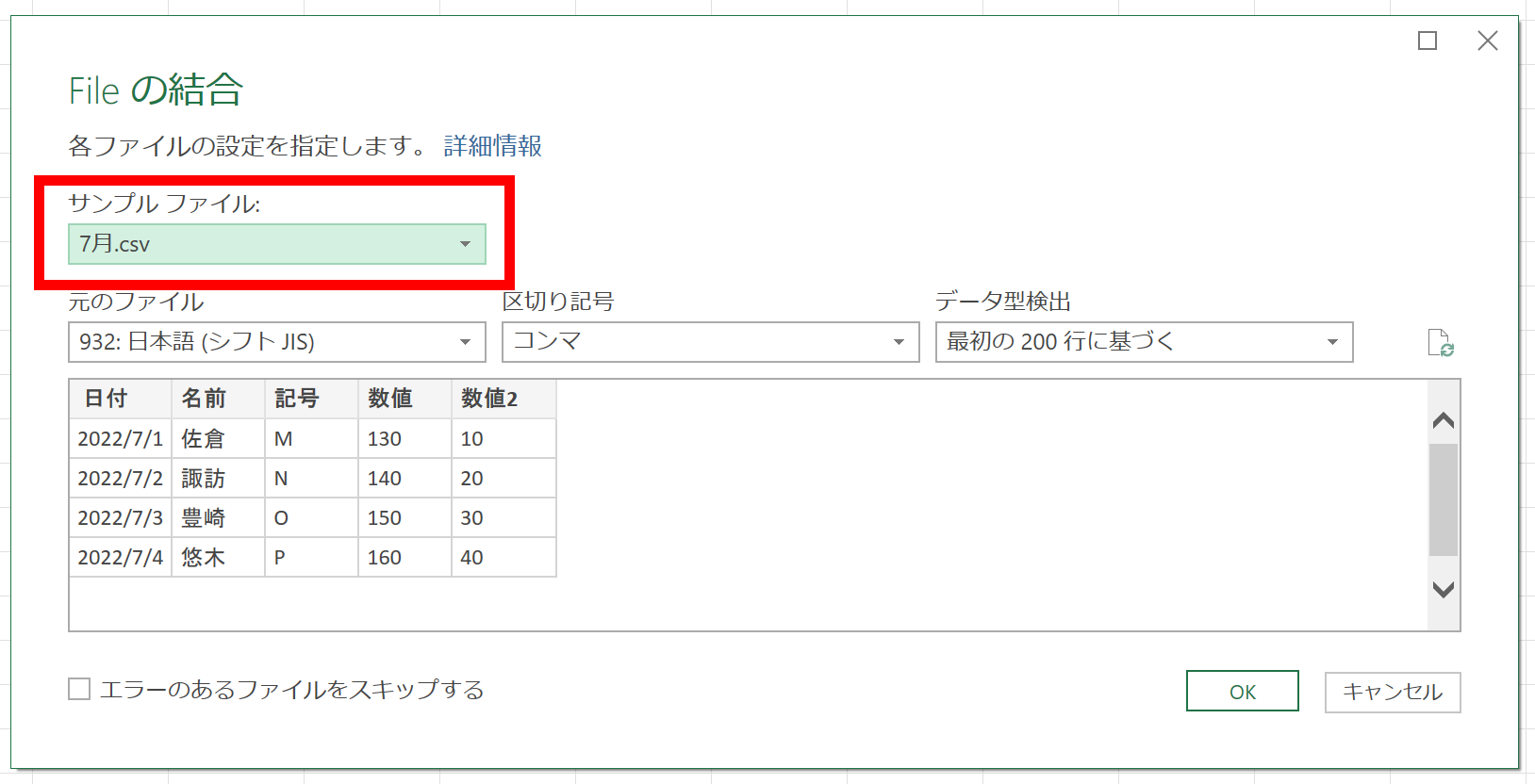
今度の「こんな感じですけど、いいですか?」は「7月.csv」ですから、"数値2"列もあります。この状態で[OK]ボタンをクリックします。
今度は"数値2"列も読み込まれました。
最初に[フォルダーから]を実行したとき、「4月.csv」「5月.csv」「6月.csv」の3ファイルは、どれも同じ列構成でした。だから、Power Queryが「サンプルファイル」として選んだ「4月.csv」の列構成で処理しても問題ありません。その後「7月.csv」が追加されて、このクエリを更新しました。しかし、更新したクエリは「4月.csvの列構成で処理する」という内容です。その結果、あとから新登場した列は処理されなかったという訳です。
では最後に「じゃ、どーする?」という解決策を考えてみます。たとえば今回でしたら、「7月.csv」が追加された後で、ただ"クエリの更新"を行うのではなく、一度Power Queryエディタを起動して、何らかの方法で、サンプルファイルを「7月.csv」に変更すればいいです。でも、そんなこと毎回やってられません。それに、今回の事案は、そもそも「ファイルによって列構成が異なる」という点が問題です。仮にサンプルファイルを「7月.csv」に変えたところで、本当にそれでいいんですか?今度は「4月.csv」の列が失われることはあり得ませんか?そう考えると、もうね、どれをサンプルファイルに指定すればいいのかさえ決められません。
そうなんです。もし「ファイルによって列構成が異なる」という状況では、「フォルダーから」を使って複数ファイルを結合して、新しいファイルはフォルダ内にコピーすればいい、あとは更新するだけ~♪という、安易な発想は危険です。もし、新しいファイルの列構成が変わっていることを知らなかったら、データが漏れていることすら気づきません。これを防ぐ抜本的な解決策はないと思います。「列構成は統一する」という、運用での対応が、最も一般的なのではないかと。