複数列でSUMIF的なことをしたい
先日のセミナーで質問されたお題なんですが、なかなか楽しかったのでご紹介します。
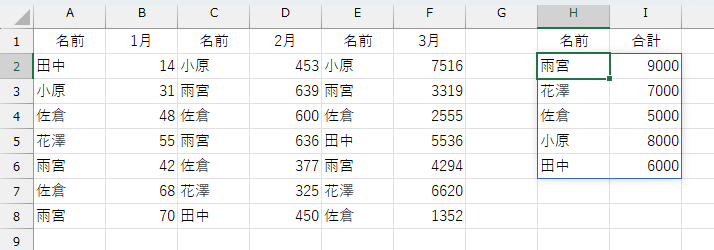
A列からF列のデータは、A列とB列が"1月分データ"で、C列とD列で"2月分データ"みたく「2列で1セット」になっているそうです。"各月のデータ"には、名前が重複する場合もあります。たとえば「雨宮」や「佐倉」みたいに。本音を言えば、このデータをどうやって作っているのかと。これの元データは?ってのが気になるのですが、なんか別の部署が作ってくるんで、よく分からないらしいですw で、こいつら(3ヶ月分のデータ)をまとめて、名前ごとの合計を出したいと。まぁ、SUMIF的なことをしたいらしいです。もともとSUMIF関数って、元のデータが複数の列に分散していると、ちょっと使い勝手が悪いんですよね。これなんか、典型的なケースでしょ。
あとですね、追加の設定です。まず、このデータはテーブル化できません。見出し(ヘッダ)に同じ「名前」が存在するので、そもそも無理なんですけど。そして、毎月のデータ件数は不定です。上図は、話を簡単にするため、まずは3ヶ月すべて同じデータ件数にしています。さらに、この調子で翌月は新しいデータが増えます。来月はG列とH列に「名前」「4月」が追加されると。そんな状況です。ね、けっこう楽しそうでしょw
では解説します。まず、現在のデータは下図のようなレイアウトになっています。簡略化するため、2ヶ月分にしました。
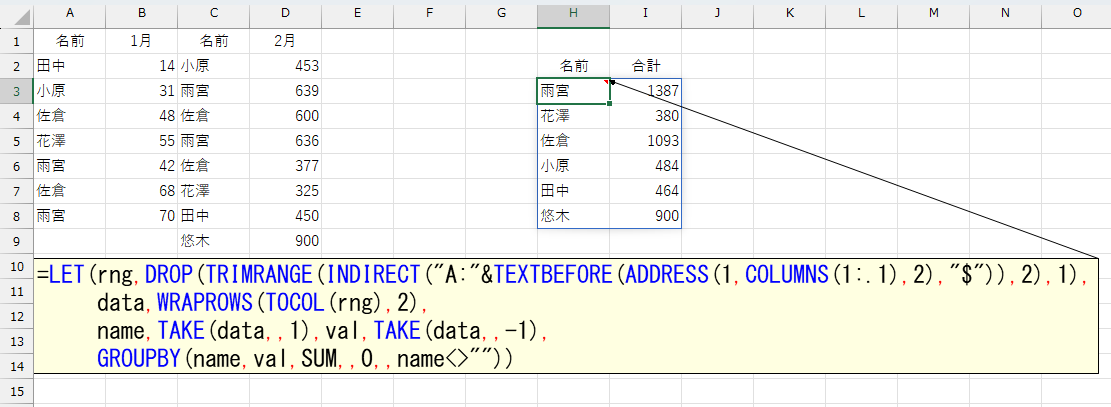
もしこれが、下図のようになったらGROUPBY関数でSUMIF的な集計を行えます。

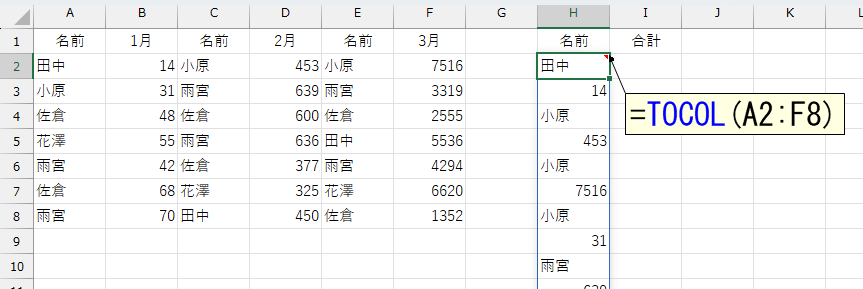
実は、上図のようなデータを作る関数があります。それは、1列のデータを複数列に変換するWRAPROWS関数です。WRAPROWS関数については、下記のページをご覧ください。
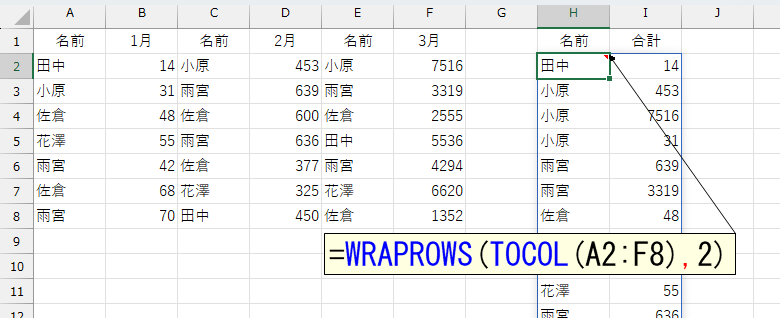
さて、WRAPROWS関数で上図を作るには、その前のデータが、下図のようになっていなければなりません。逆に言えば、下図のようなデータを作れれば、事件解決なんです。

それを実現してくれるのがTOCOL関数です。TOCOL関数については、下記のページをご覧ください。
では、実際にやってみましょう。
このあと、WRAPROWS関数の結果から、左の列と右の列を抽出しますので、LET関数で変数に入れておきます。列の抽出にはTAKE関数を使います。
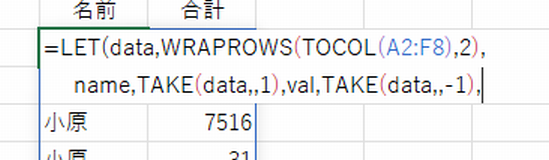
最後にGROUPBY関数で集計します。
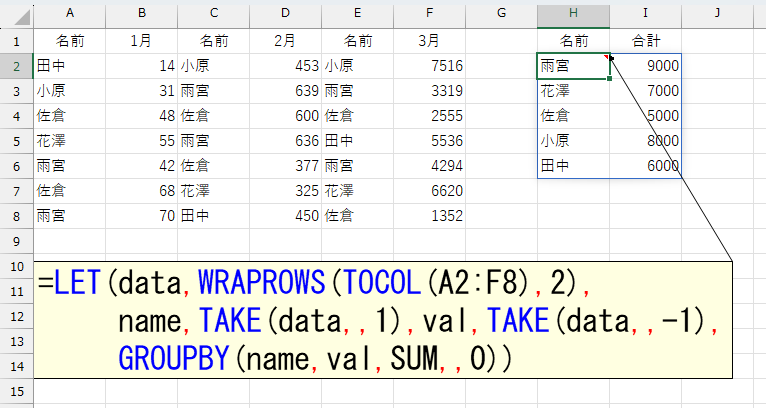
=LET(data,WRAPROWS(TOCOL(A2:F8),2),
name,TAKE(data,,1),val,TAKE(data,,-1),
GROUPBY(name,val,SUM,,0))
難易度アップ
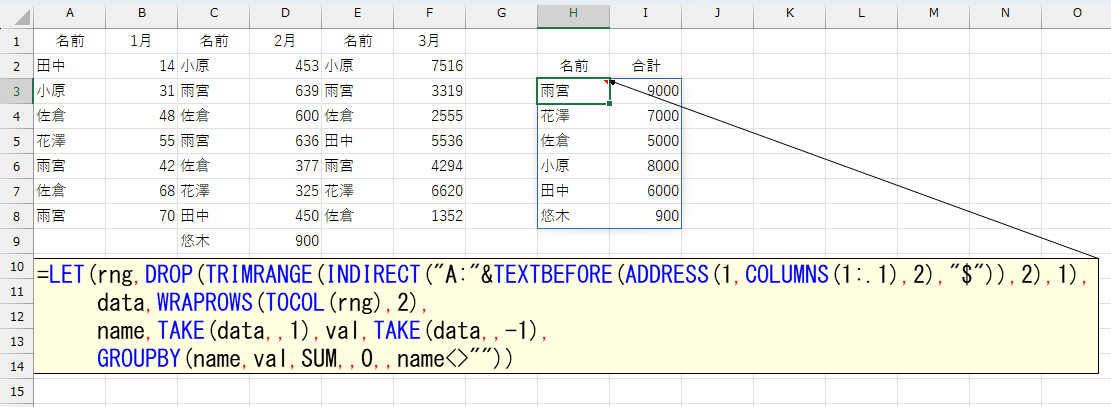
ここまでは、意外と簡単です。TOCOL関数やWRAPROWS関数などを知っているかどうかですね。さて、実際には、あと2つ問題がありまして。次は少し難易度が上がります。先に書いたように「毎月のデータ件数」は不定だそうです。となると「A2:F8」のようにアドレスを決め打ちできません。たとえば、これまでの例で、2月だけ件数が違っていたら。
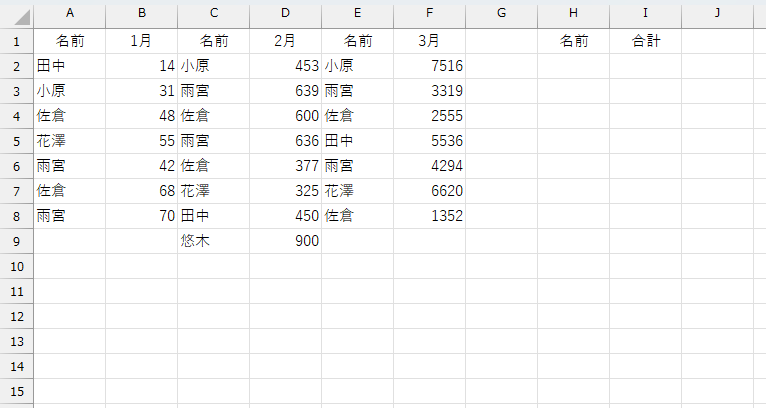
これも設定に書きましたが、このデータは「テーブルにできません」。何でも、ここで集計したブックを、また別の処理で使うそうで。そちらの処理で、テーブルになっていると困るんだそうです。いったい何の処理を、どうやっているのか疑問です。そもそも、そっちを変更しろって話です。なんですが、まぁ確かにこのレイアウトや内容って、テーブル化するデータベースではありませんね。さて、データの件数が分からないなら、ここはトリム参照を使いましょう。これも、あとのことを考えて、LET関数内で変数に入れておきます。今回の変数名はrngとしました。
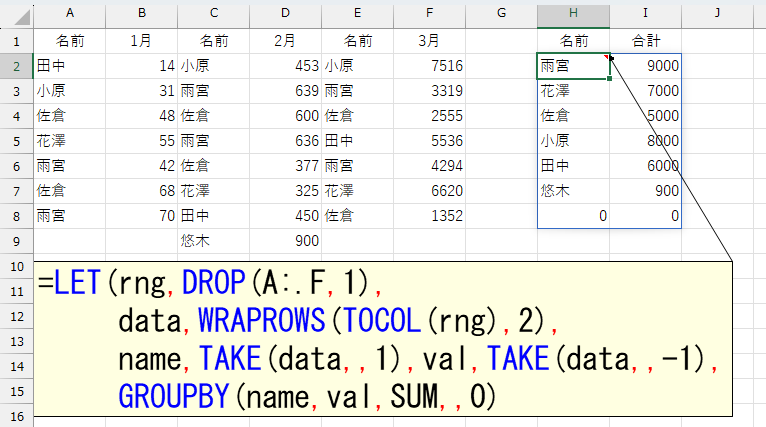
とりあえずできました。できましたけど、こうなると「0」が含まれます。これは要するに空欄("")です。1月と3月の9行目は空欄("")なので、こうなっちゃいます。さて、どうしましょう。きっと、多くの方は「FILTER関数を使えばええやん」って思うかも知れません。まぁ、それでもいいんですけど、今回だったらFILTER関数使わなくても大丈夫です。GROUPBY関数の引数に「こういうデータだけ集計して」というフィルタ機能がありますから。
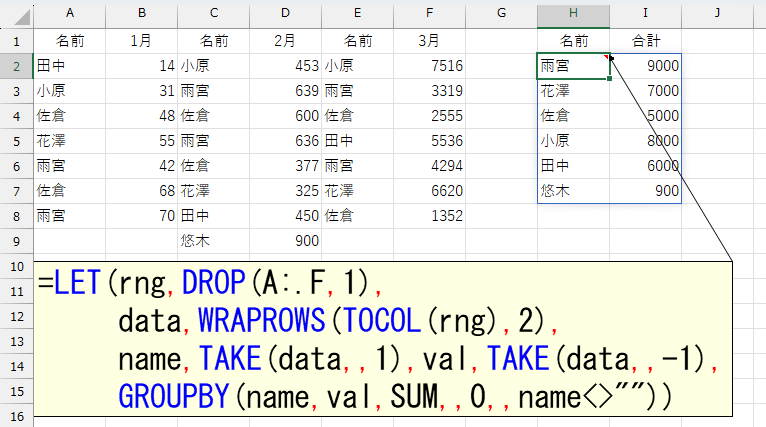
=LET(rng,DROP(A:.F,1),
data,WRAPROWS(TOCOL(rng),2),
name,TAKE(data,,1),val,TAKE(data,,-1),
GROUPBY(name,val,SUM,,0,,name<>""))
さらに難易度アップ
最後の設定が難しいです。ここまでは、教室で質問者さんとやり取りをしながら、具体的な数式を思いついていました。ですが最後に「こうしたデータが、毎月右方向に増えていくんです!できますか?」と。データ件数(行数)の不定と合わせて、いわゆるVBAのCurrentRegion的な自動処理が求められます。これ、実はけっこう前から考えてました。具体的には試していなかったですが、たぶん行ける気がしていたので「できると思いますよ、詳しくはWebで」って逃げました。なので、こうして長いコンテンツを書いているわけです。
要するに、式の冒頭で指定している「DROP(A:.F,1),」の"A:.F"部分を、データの件数(列数)によって自動処理をしたいんです。話を簡単にするため(てか、画像の関係で)2ヶ月分のデータで考えてみましょう。
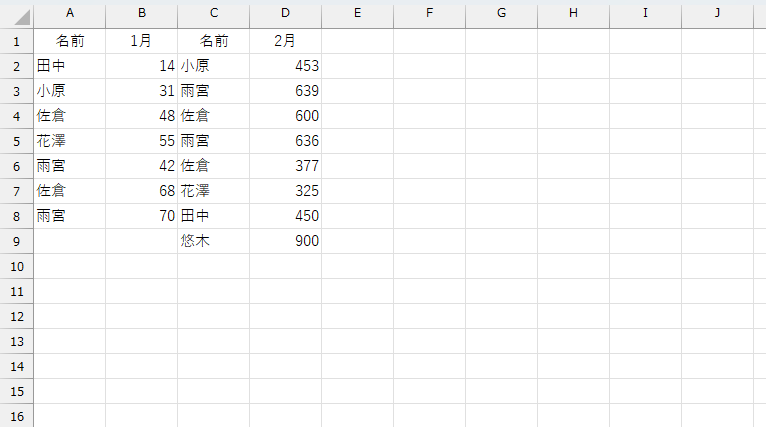
1行目の見出し(ヘッダ)は必ず入力されているとして、まずは1行目の件数を調べます。
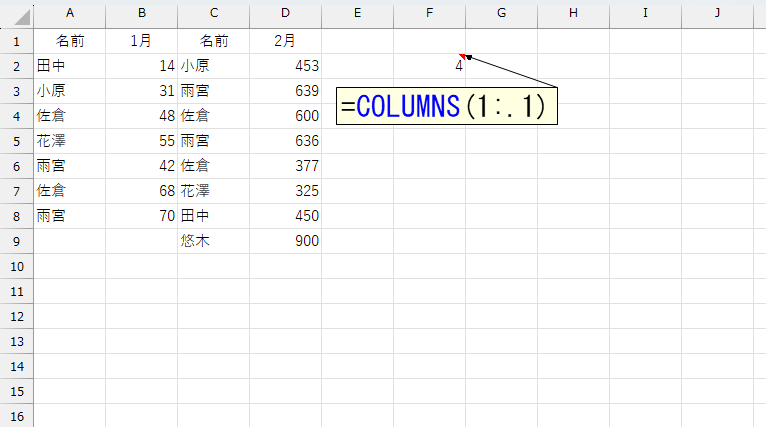
行番号と列番号が分かれば、ADDRESS関数でアドレスを作れます。
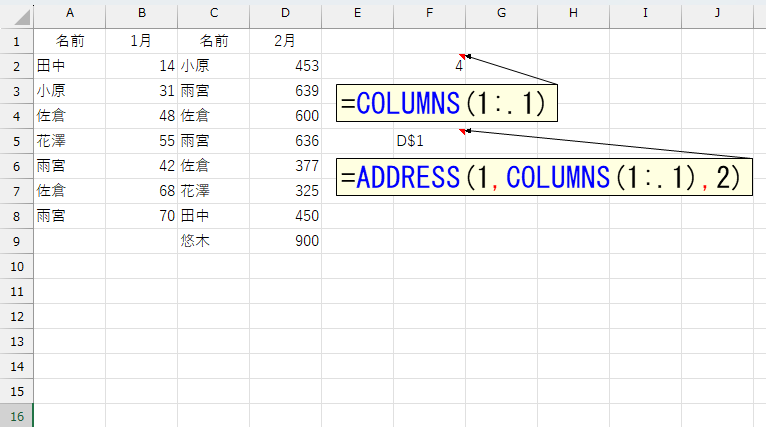
このとき「D$1」のように、列は相対参照、行は絶対参照にして、列文字(ここでは"D")と行番号(ここでは"1")の間に"$"を表示させるのがポイントです。さて、欲しい列文字は"$"の左側ですから、TEXTBEFORE関数で抜き出します。LEFT関数で「左1文字」とか抜き出すと"AB1"などで困りますから、ここはTEXTBEFOR関数ですね。
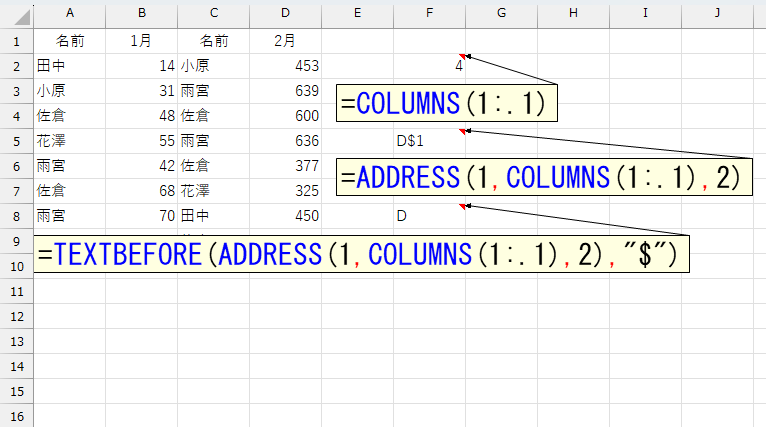
左端は"A列"固定ですから、文字列の"A:."と結合します。
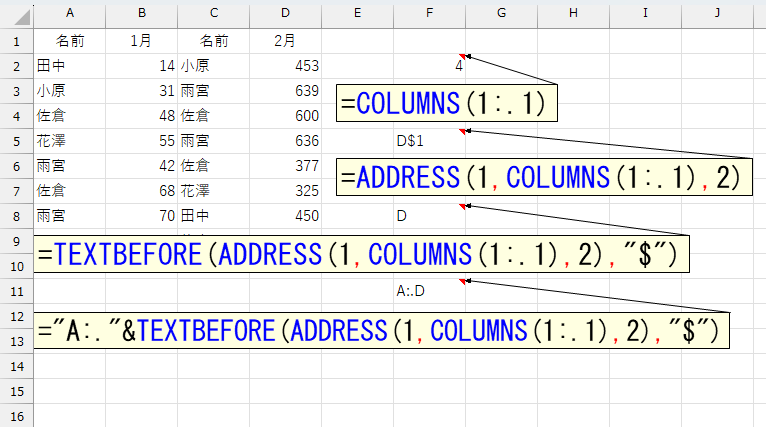
完成です。ただし、これでは「A:.D」という文字列を作っただけですから、この文字列を使ってセル範囲を参照します。使うのはINDIRECT関数です。
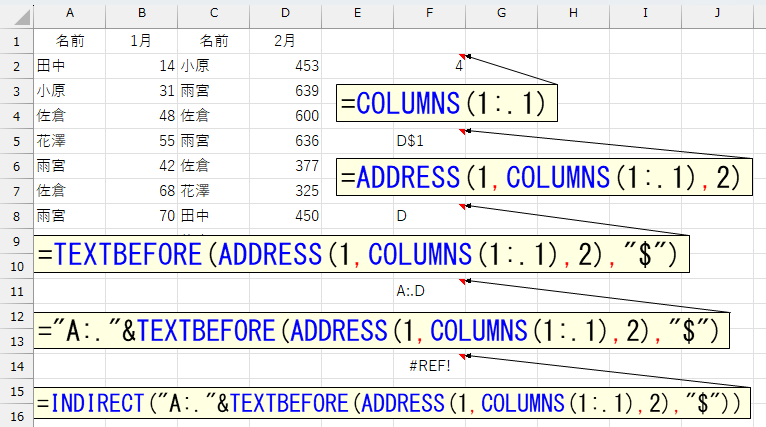
ありゃ、最後でエラーになってしまいました。考え方は正しいはずなのに。これ、実際に試して分かったのですが、INDIRECT関数にトリム参照を指定するとき、今回のように「INDIRECT("A:.D")」みたくするとエラーになります。INDIRECT関数がトリム参照に対応していないようです。
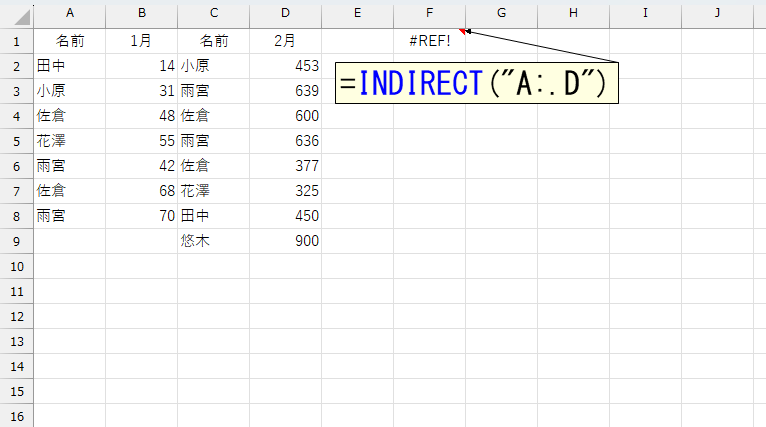
まぁ、考えてみれば納得できます。そもそもトリム参照とは、単にセル範囲を参照しているのではなく、"空欄セルを除去する"という配列処理を内部で行っているわけです。ってことは、トリム参照が返すのは"配列"です。INDIRECT関数の中に配列を指定したら、そりゃエラーですね。んなもん、試す前から分かるだろ!と、ちょっと自分が情けなく感じました。さて、INDIRECT関数の中でトリム参照は使えないと。しかし「INDIRECT("A:D")」という普通の参照は使えます。だったら、INDIRECT関数内では普通の":"を使い、INDIRECT関数が返す"列全体"をトリム参照してやりましょう。TRIMRANGE関数を使えば、そうした後処理ができるはずです。
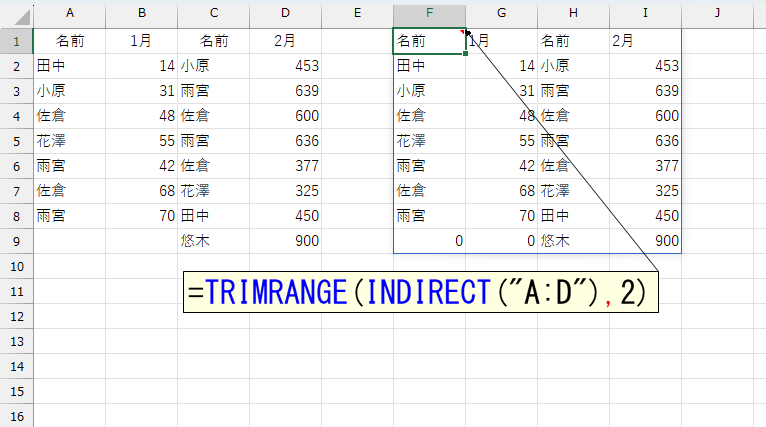
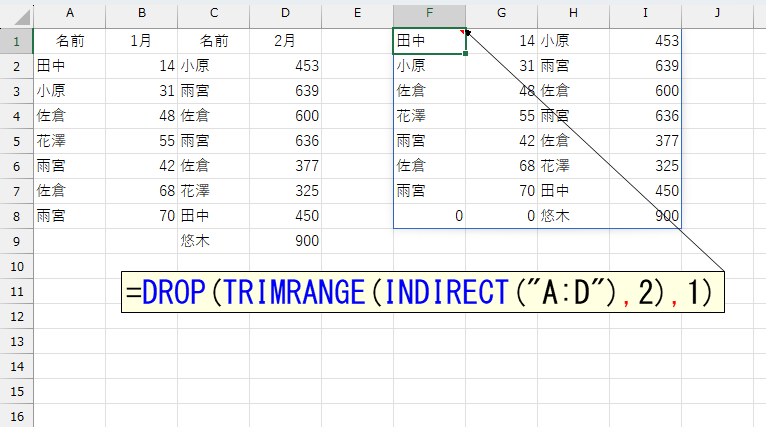
最後に、DROP関数で1行目の見出し(ヘッダ)を除去すれば、処理したいデータ部分を特定できます。
=LET(rng,DROP(TRIMRANGE(INDIRECT("A:"&TEXTBEFORE(ADDRESS(1,COLUMNS(1:.1),2),"$")),2),1),
data,WRAPROWS(TOCOL(rng),2),
name,TAKE(data,,1),val,TAKE(data,,-1),
GROUPBY(name,val,SUM,,0,,name<>""))
とりあえずできましたので、解説は以上にします。ただ、上記「CurrentRegion的な処理」って、けっこう前から考えていて。今回ご紹介した「アドレスを作る」方法を使えば可能だろうな~とは思ってました。でも、いざやってみたら、やっぱ美しくないですねw 何か他の方法がないかどうか、引き続き考えてみます。思いついたら、本稿に追記しますね。