決められた順番で並べ替える(2)
データの手入力をしない昨今において、漢字を五十音順に並べ替えるなんて、("読み"のデータが別にない限り)ほぼ無理ゲーです。まぁ、それは諦めてもらうとして、「都道府県コード」順のように、あらかじめ決められている任意の順番で並べ替えるなら可能です。そのやり方は、下記のページをご覧ください。
上記の解説では、今まであまり使わなかったSORTBY関数の利便性についても触れていますが、このSORTBY関数って、もっと便利に使えないかなと思案しました。そしたら、上記ページで紹介したやり方より、もっと簡単な方法を思いついたので、そちらもご紹介します。
「都道府県コード」順で並べ替えるには、事前に「都道府県名」と「都道府県コード」という"2列"のリストを作りましょう、って書きましたけど、これ「都道府県名」だけの"1列"リストでOKなのでは?と気づきました。
「都道府県コード」順というのは、あくまで一例です。こうした発想で、たとえば「営業所名」順や「製品名」順であったり「役員名」の順番など、いろいろな用途に応用できます。ただ、そうした社内専用の並べ替え基準には、必ずしも数値の"コード"が存在するとは限りません。まぁ、どうせリストを作るのですから、ついでに手で入力してもいいのですが、そもそも数値の"コード"は必須ではありません。要するに調べたい文字列が「上から何番目」に存在しているかを判別できればいいわけで。だったら、MATCH関数で調べちゃえばいいですよね。
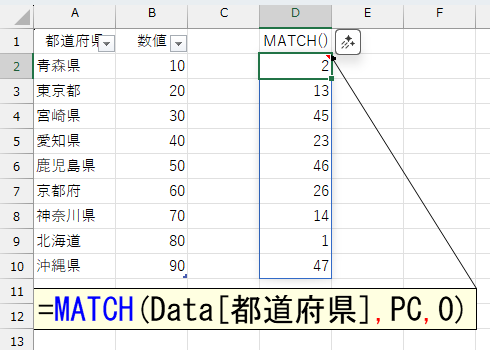
この結果をSORTBY関数に指定します。
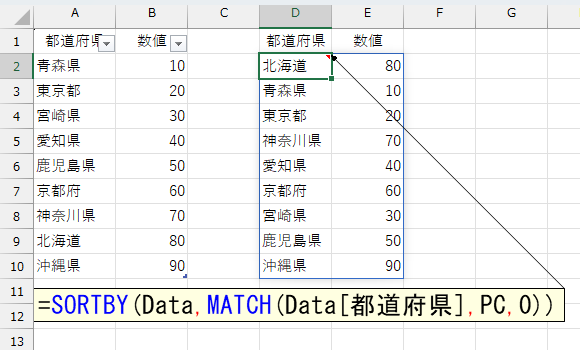
こっちの方がシンプルですね。さらに、この発想なら「存在しない項目」の処理にも対応が容易です。簡単なケースでやってみましょう。
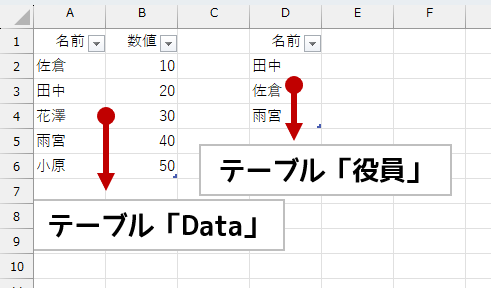
まず、テーブル「Data」の[名前]列を、テーブル「役員」で検索します。
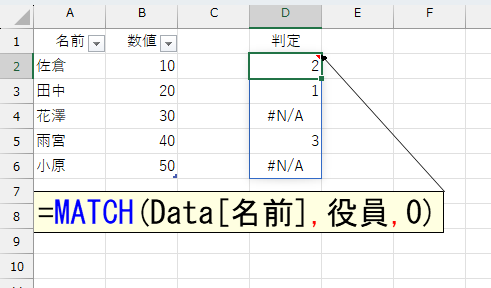
役員リストに存在しない人が2名います。まず、この2名が「役員の上」に表示されるようにします。このMATCH関数の結果を、このあとSORTBY関数に指定するのですが、結果の数値を並べ替えたとき「1よりも上」にしたいので、「エラーだったら0」とします。
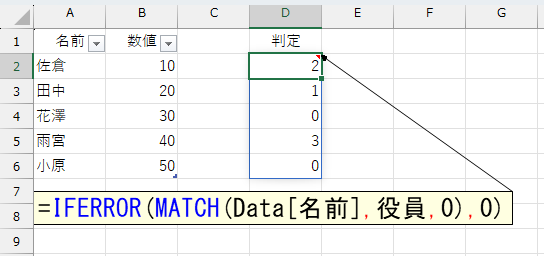
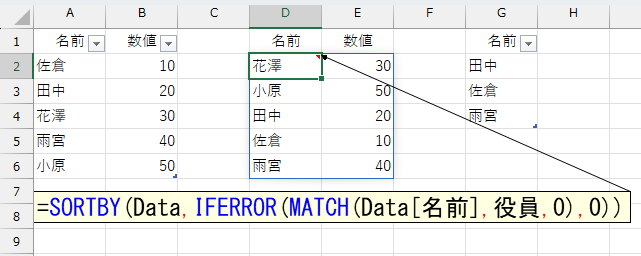
結果はこうなります。
では、存在しない人を「役員の下」に表示するには、どうしたらいいでしょう。今回のケースでしたら「エラーだったら4」のように"決め打ち"でも可能です。でも、もし役員の数が増えたら困りますね。毎回この数値を変更しなければなりません。もちろん、256とか1024など十分に大きい数値を指定してもいいのですが、あまり美しくありませんし汎用性も乏しいです。こんなときは「エラーだったら"役員の数"より大きい数値」を指定しましょう。役員の数は、テーブル「役員」の行数ですから、ROWS関数で調べられます。その行数に+1をすれば、役員の数より大きくなります。
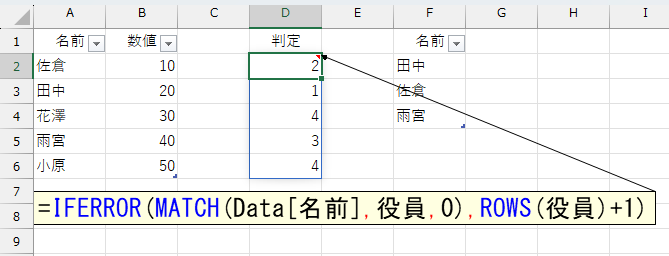
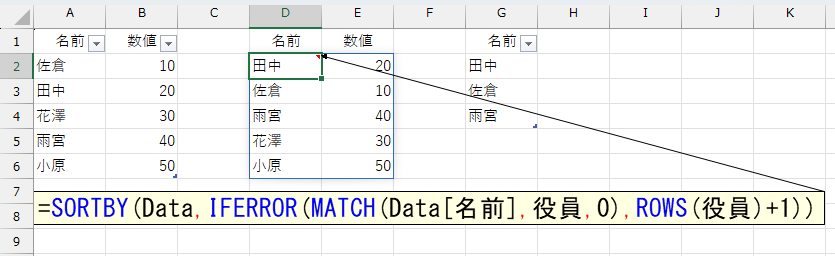
=SORTBY(Data,IFERROR(MATCH(Data[名前],役員,0),ROWS(役員)+1))