累計の計算(テーブル編)
テーブルに入力されている数値の累計を計算してみます。
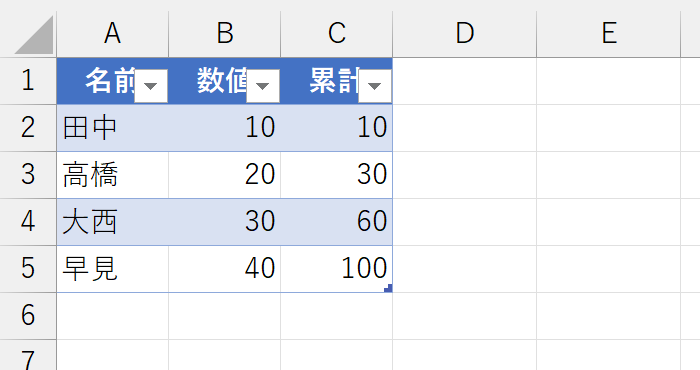
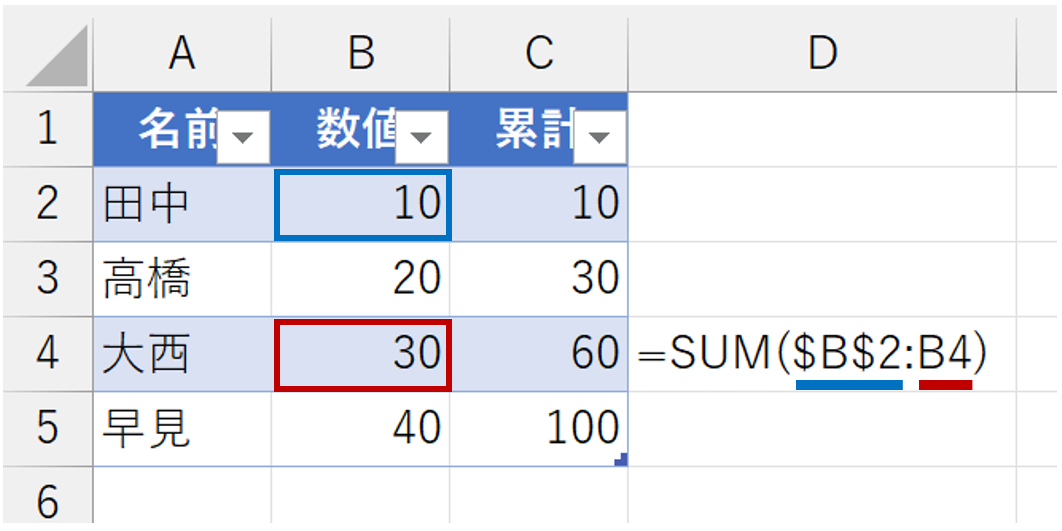
C列の[累計]列には、次のような数式を入力しました。

なお、D列にはFORMULATEXT関数を入力してありますので、C列の数式が変化したらD列の表示も変わります。この数式の考え方は、下記のページで解説していますのでご覧ください。
さて、無事に累計が計算されています。では、新しいデータを追加してみましょう。まずは、名前を入力します。
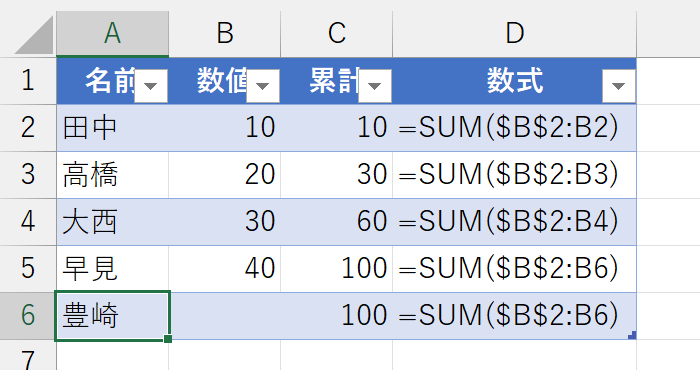
続いて、B列に新しい数値を入力します。
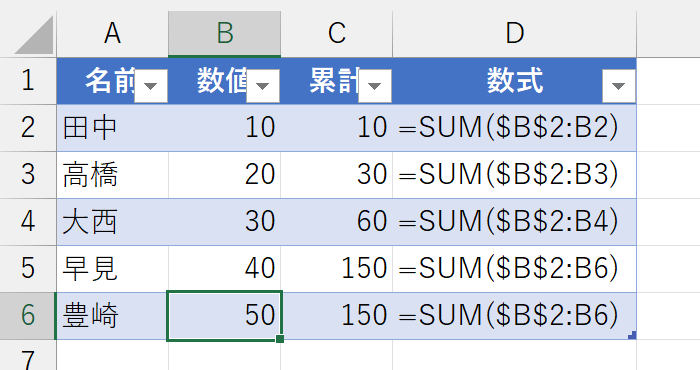
あれ?C列に"150"が2つ並んでいます。そんなはずはありませんよね。この現象、ときどき質問されるのですが、正直わたしも最初は戸惑いました。まず、どの時点で何が起こったのかを確認してみましょう。上記の、新しい名前を入力した時点での画像をよく見てください。テーブルは、新しいデータが入力されると、テーブル内の数式も自動的に拡張されます。とても便利な仕組みです。ですが、新しい名前を入力した直後にセルC5の数式が変わってしまいました。新しく入力した行のセルC6には、正しい数式が拡張されています。6行目を入力したとき、ひとつ上の5行目に入力されている数式が変化するとは、なんとも不思議な現象です。
ある意味で当然
なぜだろう?と考えてみました。Excelは内部で何をしているのだろうと。しばらく考えた結果、何となく理解しました。そもそもテーブルは、通常のワークシート領域とは異なります。セル範囲をテーブルにすると、そこはExcelがデータベースとして管理する特別な領域となります。普通のワークシートやセルとは、根本的に違うんです。その仕組みによって、構造化参照などが実現され、われわれは便利な機能を享受しています。そう、テーブルはデータベースなんです。言い換えると、テーブルはデータベースでなければいけないんです。だから、テーブル内ではセルの結合ができません。セルを単体で挿入や削除もできません。それは、データベース的に考えたら、あり得ない操作だからです。
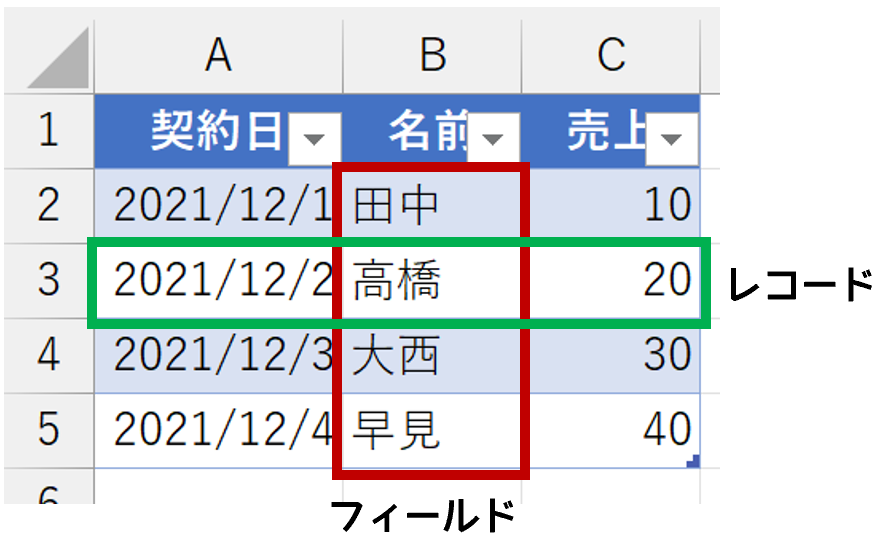
データベースの世界では、Excelで言うところの「列のデータ」を"フィールド"、「行のデータ」を"レコード"と呼びます。そして、フィールドには「同じ類いのデータ」が入力されていなければなりません。日付フィールドなら、そこは日付だけ。数値フィールドには、数値しか入力できません。さらに、その数値も「同じ意味を持つデータ」が入力されていて、初めてデータベースとして機能します。たとえば、数値フィールドに文字列が入力されているのは論外ですし、同じ数値フィールドに売上と原価が混在していることもあり得ません。それがデータベースです。対してExcelは、良い意味で"無法地帯"です。列や行というのは、人間が便宜的に区別しているに過ぎず、そこには好き勝手に何でも入力できてしまいます。
データベースがデータとして扱えるものは、極論を言えば"数値"か"文字列"です。もちろん、"論理値"であるとか"日付"だとかも扱えますし、詳しくは知りませんが、最近のデータベースでは、もっと高度なこともできるのでしょう。しかし、いずれにしてもデータベースで扱えるものは"数値"や"文字列"などのデータ(値)です。ところが、困ったことに、Excelではセルに「データ(値)ではないもの」を入力できてしまいます。それは「数式」です。おそらくデーベースの世界では、状況によって結果が変化する数式を、データとして扱うという発想は、一般的ではないと思います。でも、Excelはそれを、普通にできてしまいます。Excelのテーブルはデータベースです。ですから、テーブル内に数式を入力するときであっても、データベースの流儀には従わなければなりません。その流儀とは「フィールドには、同じ意味を持つものが入力されている」ということです。だからExcelのテーブルでは、ひとつのセルに数式を入力すると、その列内すべてのセルに、同じパターンの数式が自動入力されます。
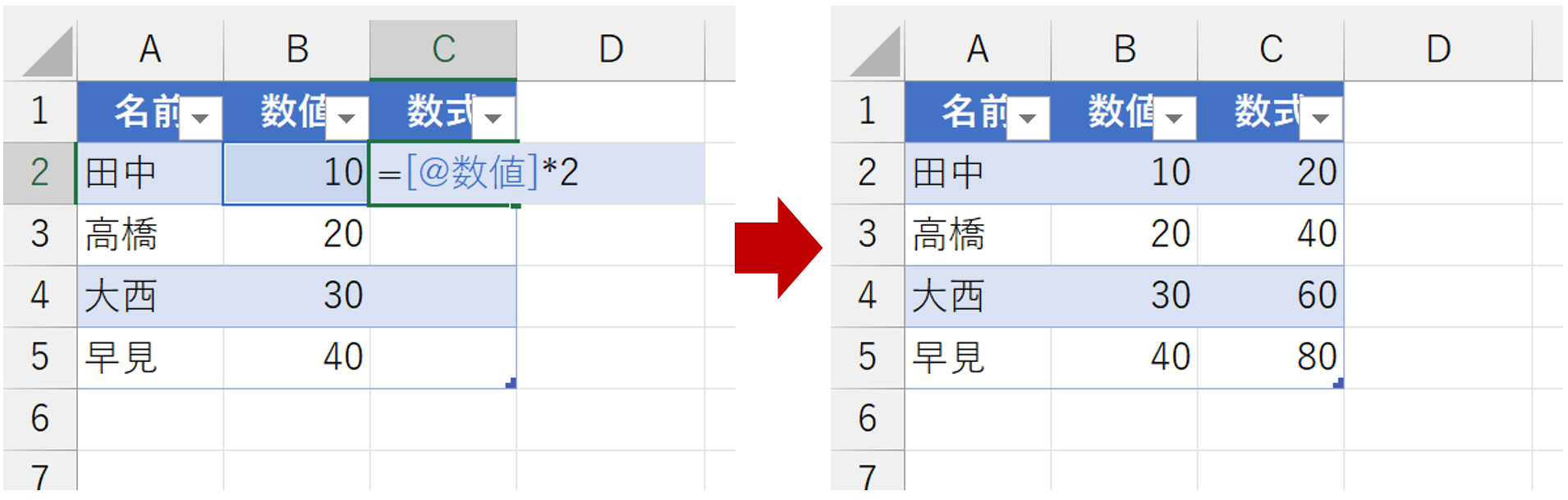
あるいは、入力されている数式列のうち、どれかひとつの数式を変更すると、すべての数式が同じパターンに変更されます。
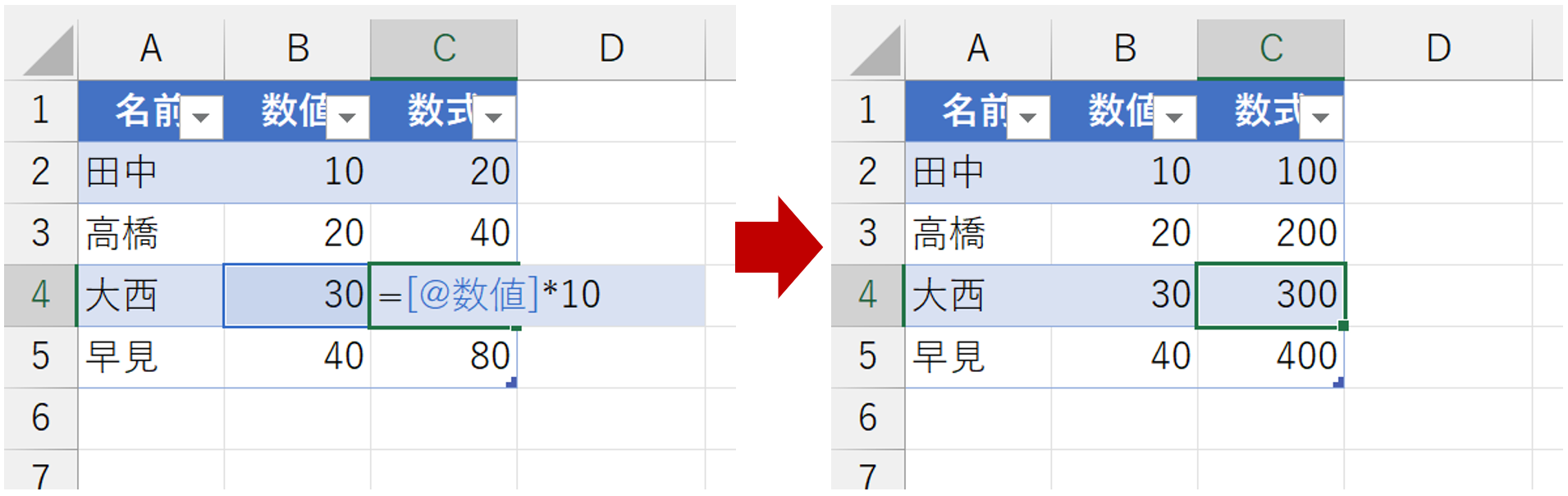
つまり、テーブルの列内には、すべて同じパターンの数式が入力されていなければならないのです。それがデータベースの考え方です。もちろん、手動操作で、セルごとに異なる数式を入力することも可能です。今回の「累計の計算」で使用している数式などは、その典型です。セルごとに、数式で参照しているセル範囲が異なっています。これ、データベース的にはルール違反です。ルールに違反したのですから、われわれの望むような結果にならないのは、ある意味で当然です。ルールを破ったのはこちらなのですから。道具は、正しい使い方をしないと、そのポテンシャルを発揮できません。今回の事例って、そういうことだと思います。
解決策
と、まぁ、おそらくそういうことだろうなと、少なくとも私は納得しました。これは、しかたないと。でも、こうした累計ってやりたいです。理屈は分かりましたので、何とか実現しましょう。もちろん、データベースの流儀に則った、正しい使い方で。
今回、何がいけなかったって、C列([累計]列)の各セルに異なるパターンの数式を入力したのが原因です。
- セルC2:=SUM($B$2:B2) → 1つのセルを合計する
- セルC3:=SUM($B$2:B3) → 2つのセルを合計する
- セルC4:=SUM($B$2:B4) → 3つのセルを合計する
- セルC5:=SUM($B$2:B5) → 4つのセルを合計する
まず、すぐ思いついたのは、次のような発想です。各数式はSUM関数で参照しているセル範囲が異なります。このセル範囲が「自動的に変化するひとつの数式」を作ってやればいいのではって。たとえば、こんな数式で実現できそうです。
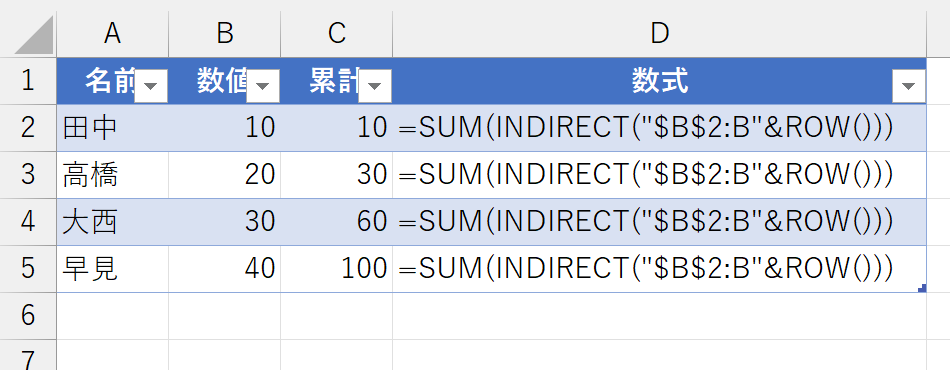
新しいデータを入力してみましょう。
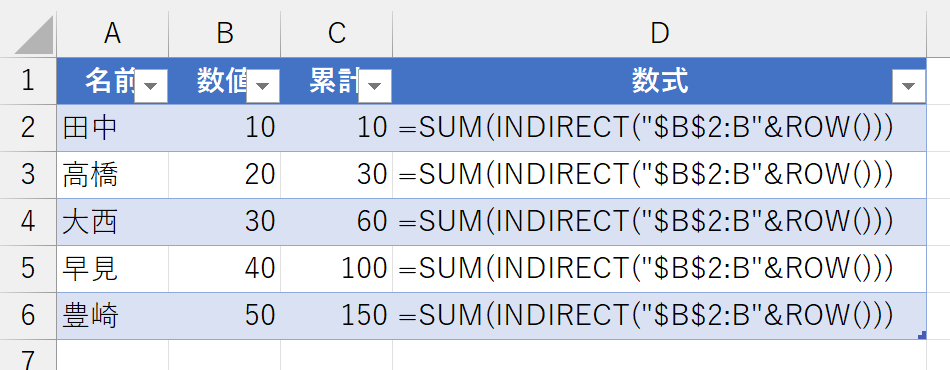
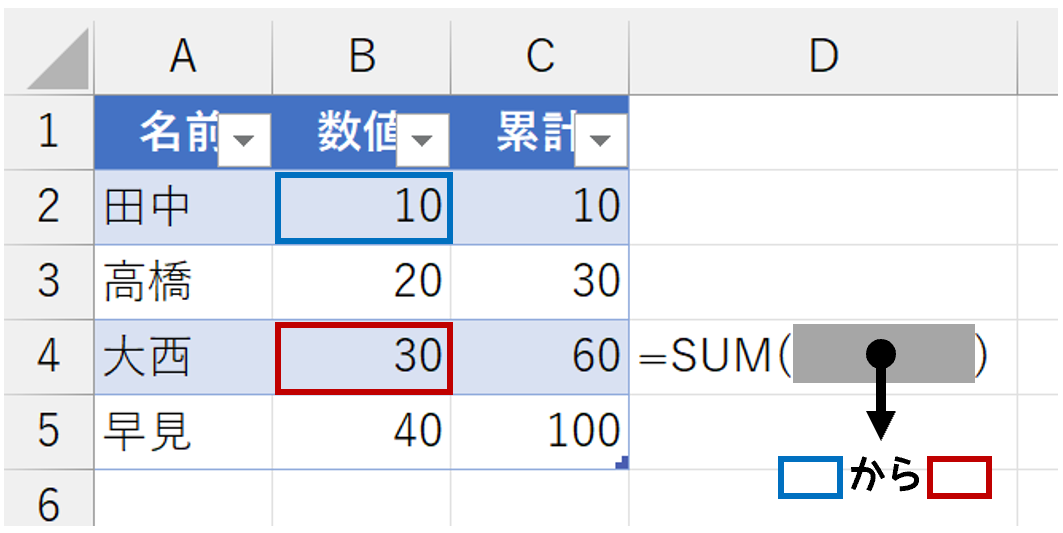
できました。できましたが、この発想は、何となく美しくないです。データベースの世界で「このセル」とか「この行」などのように、セルや行を単体で特定するってのは、ちょっと違う気がします。これ、セルの位置を決め打ちするという"表計算的な発想"です。そこで、次のように考えてみました。ここでは、例としてセルC4の数式で解説します。
テーブル内では、できるだけセルの"アドレス"で考えたくありません。それは、表計算的な発想ですから。
セルC4では「セル範囲B2:B4」を参照したいです。上端の「B2」は後で考えるとして、この数式を入力するセルC4にとって参照したいセルB2というのは「テーブル内の[数値]列にあるセル」であり、なおかつ「数式を入力しているセルC4と同じレコード(行)」にあるセルのことです。「数式を入力しているセルと同じレコード(行)」のセルって、構造化参照で次のように表されます。
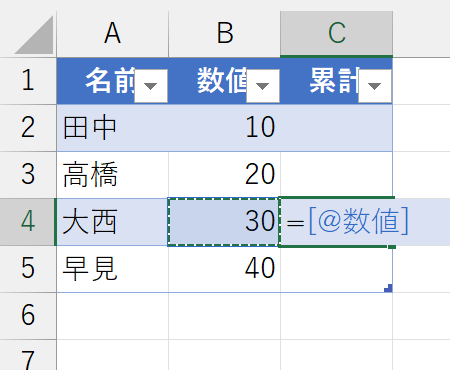
この"@"を「暗黙的なインターセクション演算子」と呼びます。つまり、セルC4で参照するセル範囲は次のように指定できます。
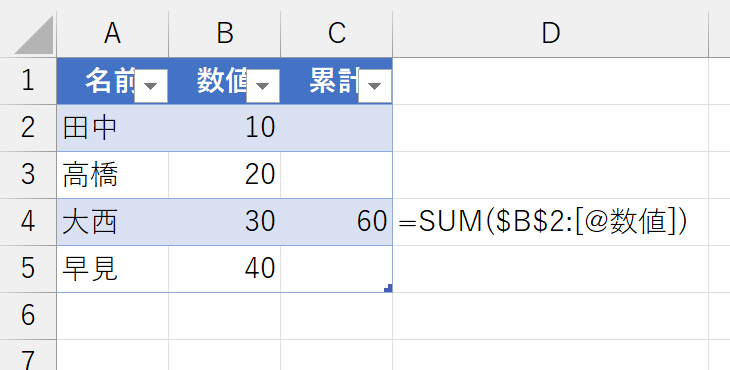
セルを編集モードにすると、正しく参照されているのが確認できます。
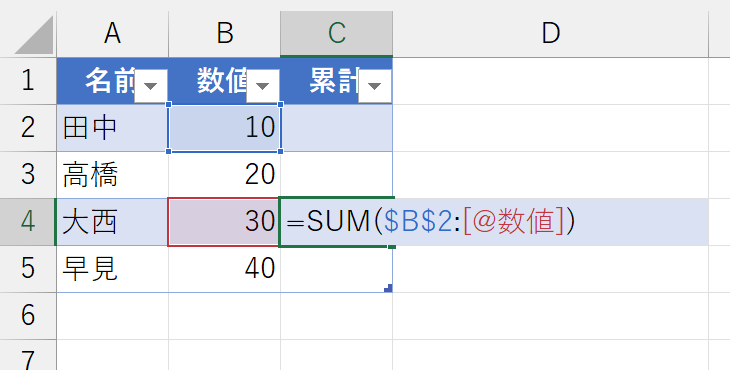
さあ、ここまで来ると、上端の「$B$2」もアドレスを使わずに指定したいところです。しかし、構造化参照では"異なるレコード(行)"のセルを参照しようとすると、セルのアドレスが使われます。まぁ、しかたないですね。
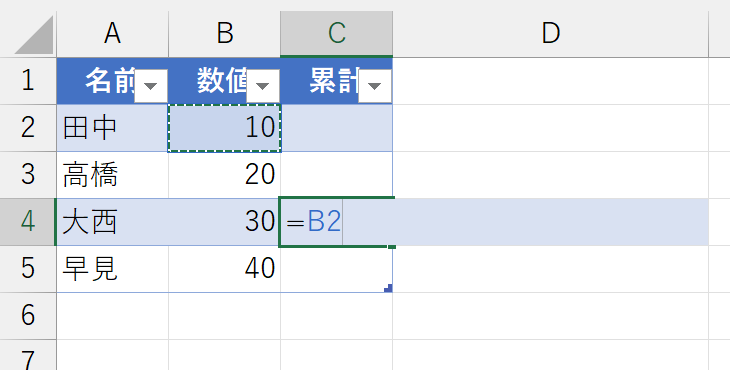
でも、ちょっと待ってください。この上端「$B$2」って、要するに「[数値]列の先頭セル」です。ということは「[数値]列の、見出し(タイトル)から見て1つ下のセル」です。[数値]列の見出しでしたら、構造化参照で指定できます。
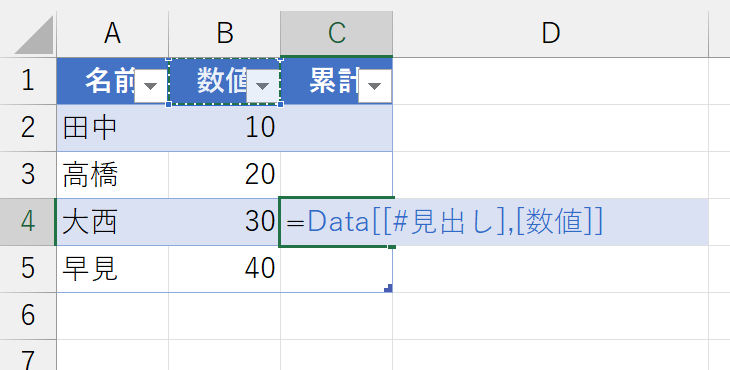
ああ、言い忘れましたが、"Data"というのはこのテーブルの名前です。"テーブル1"だと長いので変えました。さて、構造化参照で[数値]列の見出しを特定できましたので、このセルから1つ下を参照してみます。
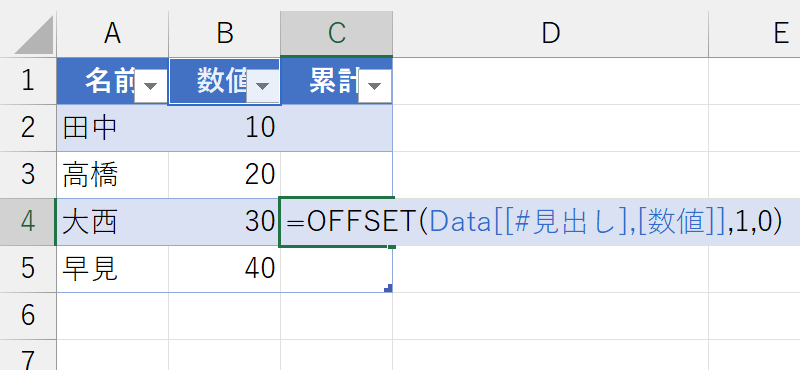
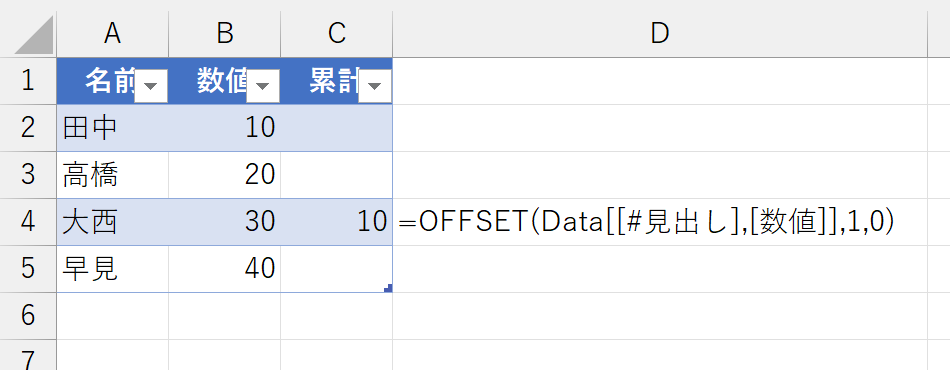
役者は揃いました。アドレスでセル単体を特定するという表計算的な発想ではなく、テーブル内の"どういう値"みたくデータベース的な発想で計算してみます。
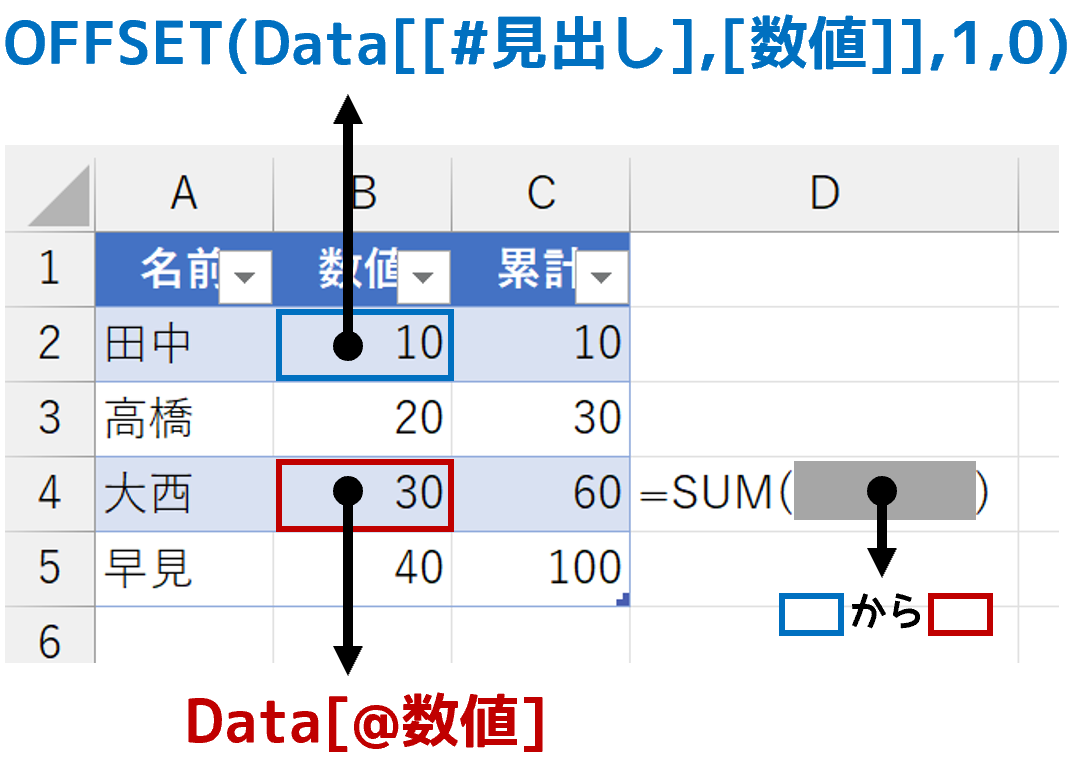
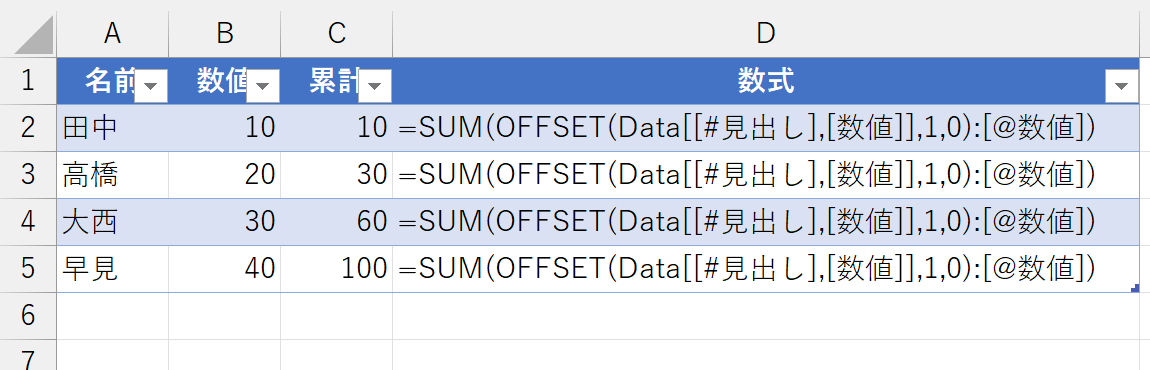
新しいデータを入力してみましょう。

うまくいきました。「テーブルはデータベースとして操作する」がポイントですね。余談ですけど、Excelを教えているトレーナーさんから「テーブルって、よく分からないから教えられない」という声をよく聞きます。長い間、表計算ソフトとしてのExcelを、表計算的な発想で教えてきたトレーナーさんにとっては、テーブルに関してだけ「データベース的な発想で考える」というのは、確かに荷が重たいのかもしれません。でもね、そんなことは言っていられないんですよ。これからはテーブルの時代です。テーブルを使うのが普通になりますし、いかにテーブルを活用するかがExcelのポイントになります。Power Queryから出力されるのは必ずテーブルですしね。苦手意識を持っている方は、がんばって発想を切り替えてくださいね。
追記:
本稿を見直していて、ふと「え?もっと簡単な方法があるのに」って思いました。自分で書いたコンテンツに、自分でツッコミを入れたようなものです。まぁ、よくありますw 本稿では、[数値]列の一番上のセル(今回はセルB2)を「列見出し("数値")のひとつ下」としましたが、そんな回りくどいことをしなくても「[数値]列データの先頭(一番上)」って考えた方が自然です。[数値]列のデータ(アドレスで言えばセル範囲B2:B6)は、構造化参照で「Data[数値]」です。その先頭なのですから、INDEX関数やTAKE関数を使えば一発です。

なので、テーブル内で累計を求めるなら、次の数式になります。
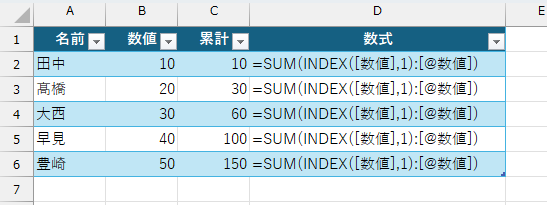
私はTAKE関数が好きなので、自分用のブックだったらTAKE関数を使いますが、一般にはINDEX関数の方が多くの人に分かりやすいでしょうね。