TEXTBEFORE 関数 / TEXTAFTER 関数
ここで解説する TEXTBEFORE関数とTEXTAFTER関数 は、ProPlusに追加された関数です。Excel 2016/2019/2021では使用できませんのでご注意ください。また、本稿執筆時点(2022/3/20)では、まだInSider Programに実装されただけですので、製品版で使えるようになるには、まだ少し時間がかかると思います。なお、この関数については、YouTubeの動画でも解説しています。ぜひ、ご覧ください。
【追記】(2022/7/25)
冒頭で"追記"ってのもナニですが。本稿は上述のとおり、2022/3/20に執筆しましたが、先日ふと見たら、引数に変化がありました。最初に書いた解説とは、かなり変わってきましたので、思い切って書き直します。まだ、ベータ版的な扱いなので、また何か変わったら追記します。
文字列(TEXT)のうち、指定した区切り文字から"前(BEFORE)"を抜き出すのがTEXTBEFORE関数で、"後ろ(AFTER)"を抜き出すのがTEXTAFTER関数です。


もちろん、区切り文字が「何文字目にあるか分からない」という状況ですね。これ、実務では、よくやる作業です。今までのExcelでしたら、FIND関数やSEARCH関数で区切り文字の位置を調べて、LEFT関数やMID関数などで抜き出していました。
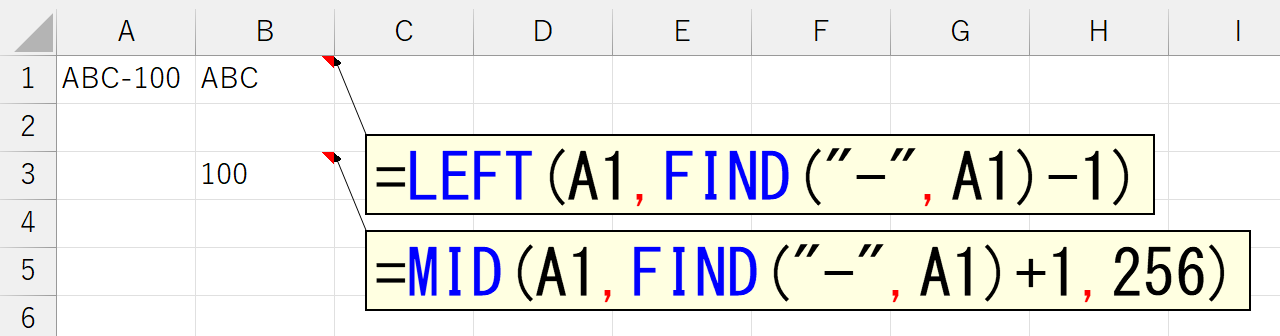
この処理が、ひとつの関数だけでできるようになりました。ですが正直、今までだって複数の関数を組み合わせればできたし、別にそれで困ってなかったし、今さら「1発でできるよ~」って言われても、それほど感動はありません。まぁ実際には、最新版ということで、ちょっと便利な仕組みも搭載されているのですが、それは後述するとして、まずは引数を見てみましょう。
TEXTAFTER(text,delimiter,instance_num,match_mode,match_end,if_not_found) TEXTBEFORE(text,delimiter,instance_num,match_mode,match_end,if_not_found)
まだ、搭載ホヤホヤの新参者ですから、引数も英語表記のままです。ちなみに、どちらも指定できる引数は同じです。正式版として実装されるときには、ちゃんと日本語の引数名に翻訳されるでしょうけど、ここでは、解説がしやすいように、私流に翻訳してみます。
TEXTBEFORE(元の文字列,区切り文字,区切り位置,検索方法,文字列の終端,見つからないとき) TEXTAFTER(元の文字列,区切り文字,区切り位置,検索方法,文字列の終端,見つからないとき)
引数が多いので、順番に解説します。
元の文字列(text)
これは簡単ですね。悩むこともないでしょう。区切る前の、元の文字列を指定します。セルに入力されていれば、そのセルを指定すればいいし、括弧内の引数に直接"ABC-100"のように書いてもいいですし、別の関数を指定することもできます。
区切り文字(delimiter)
分割する位置を定める文字を指定します。一般的には、スペースとか"-"などの記号を指定するケースが多いでしょう。もちろん、記号だけでなく単なる文字も指定できますし、それは複数文字でもOKです。
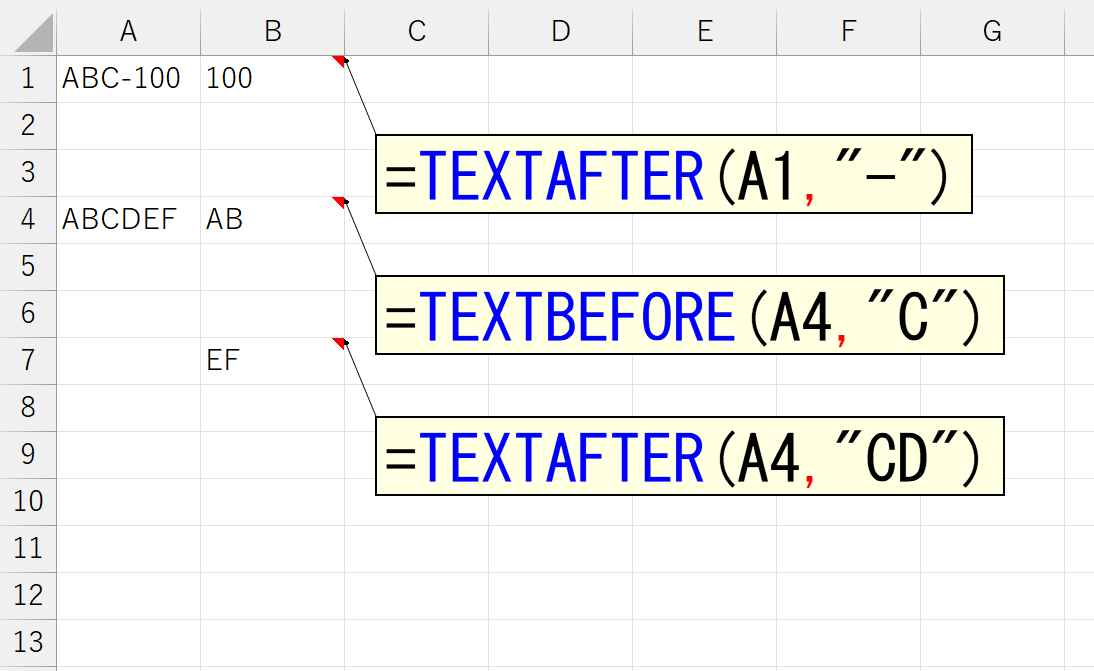
日本語もいけます。
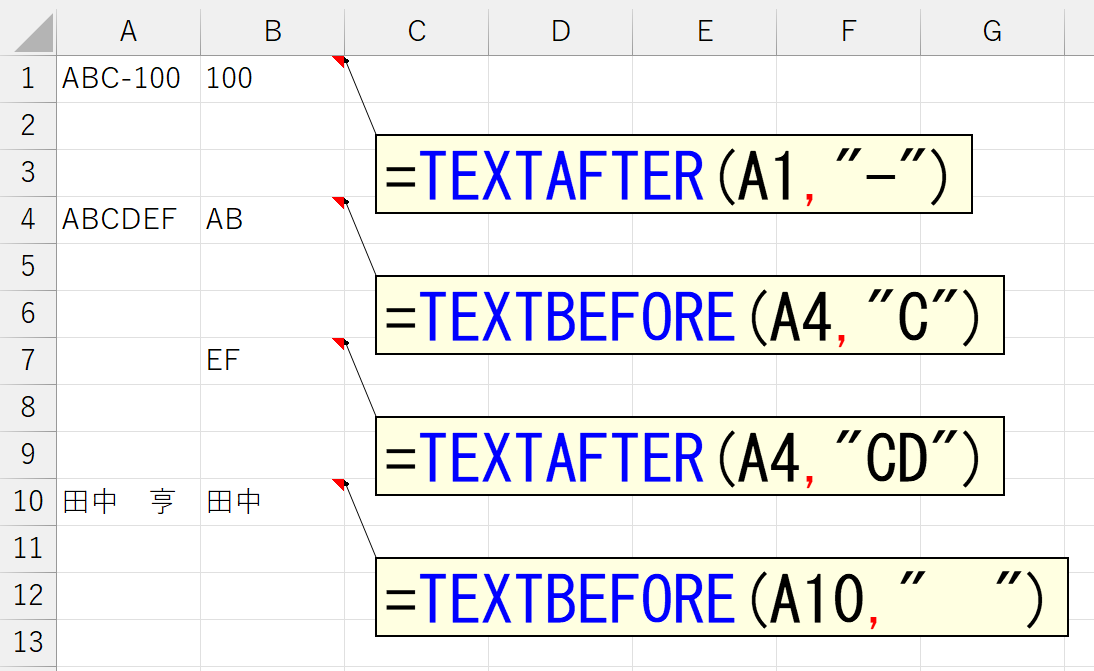
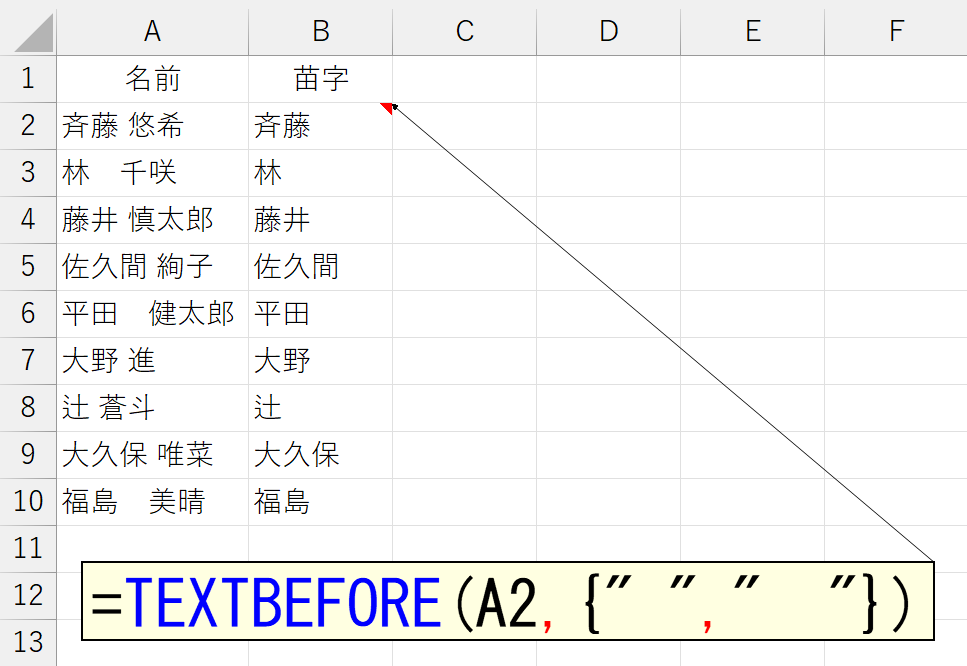
上図のセルA10は、苗字と名前を全角のスペースで区切っていますので、区切り文字に全角のスペースを指定しました。
区切り文字に「*」や「?」などのワイルドカードは使えません。それらは、単なる文字として扱われます。

区切り位置(instance_num)
3つめの引数「区切り位置」は、もし指定した区切り文字が、元の文字列内に複数存在していたとき、左から"何番目に登場した区切り文字"で区切るかを指定します。
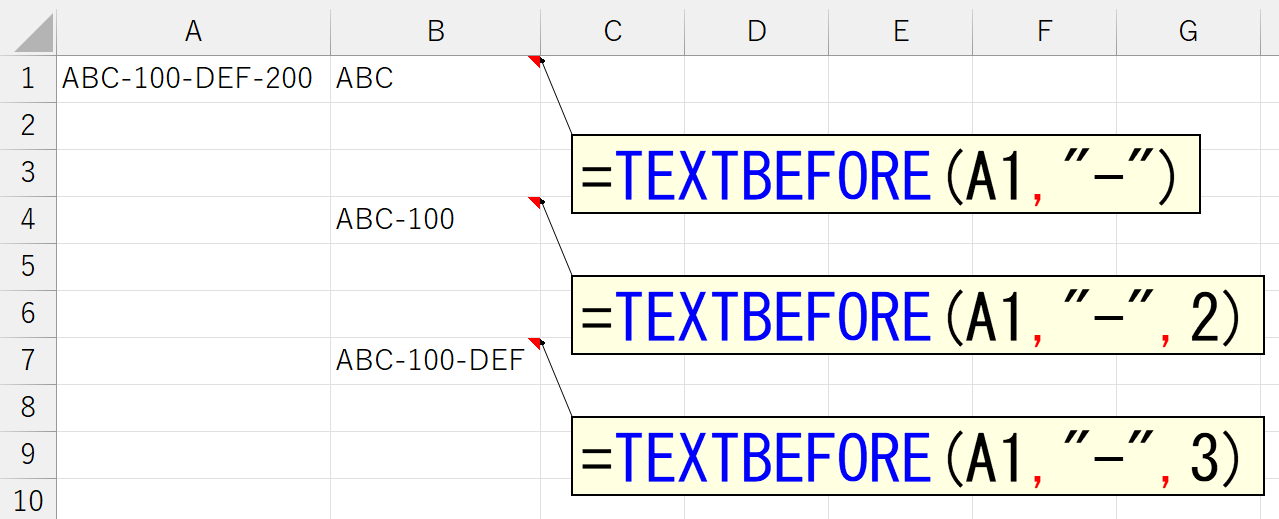
引数「区切り位置」を省略すると、1を指定したものとみなされます。
検索方法(match_mode)
引数「検索方法」は、引数「区切り文字」にアルファベットを指定したとき、大文字と小文字を区別するかを指定します。0を指定すると、大文字と小文字を区別して、1を指定すると区別しません。この引数を省略すると1を指定したとみなされて、大文字と小文字は区別されます。
文字列の終端(match_end)
ハッキリ言って、この引数は意味が分かりません。ちなみにヘルプには、次のように書かれています。

これ以上はMicrosoftのサイトにも情報がありませんし、サンプルもないです。英語のサイトも調べてみましたが、思うようなヒントは得られませんでした。しかたないので、どんな元データで、どう設定すると、どういう結果になるのかをあれこれと試してみました。その結果、違いが分かったのは次のケースです。
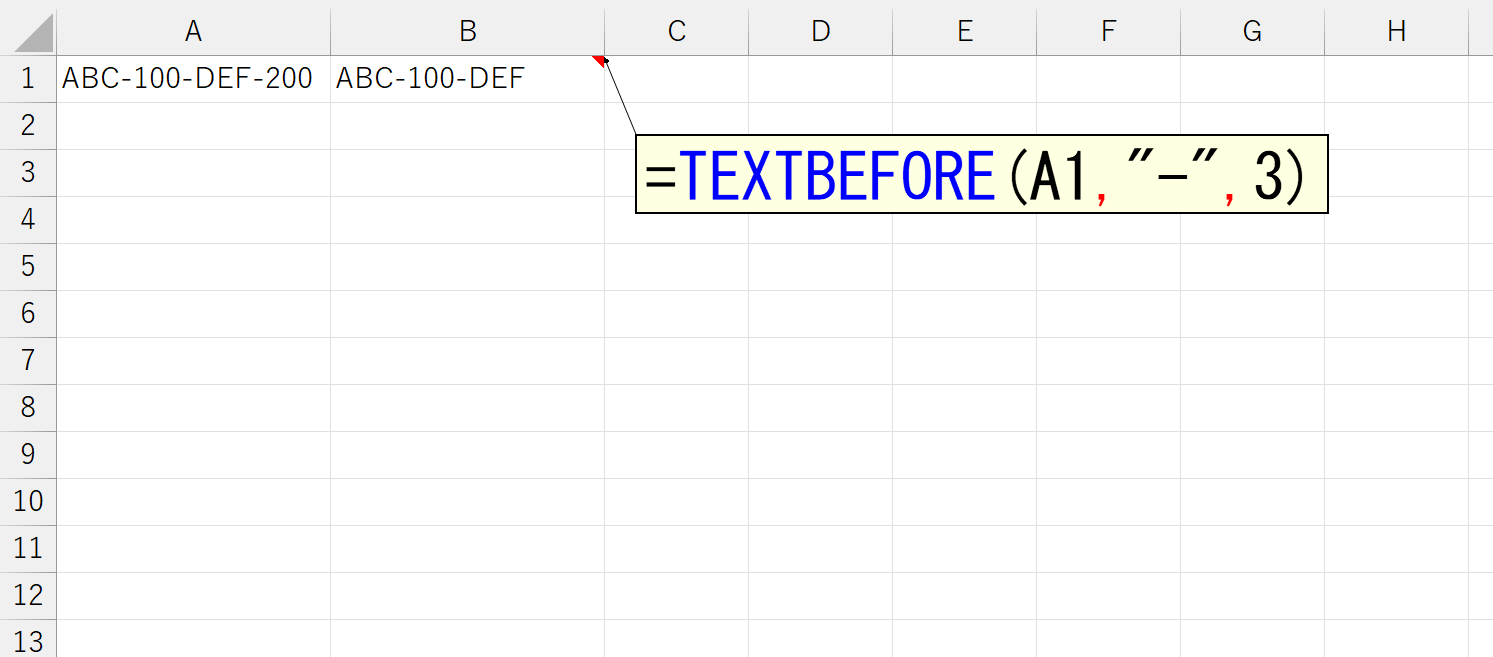
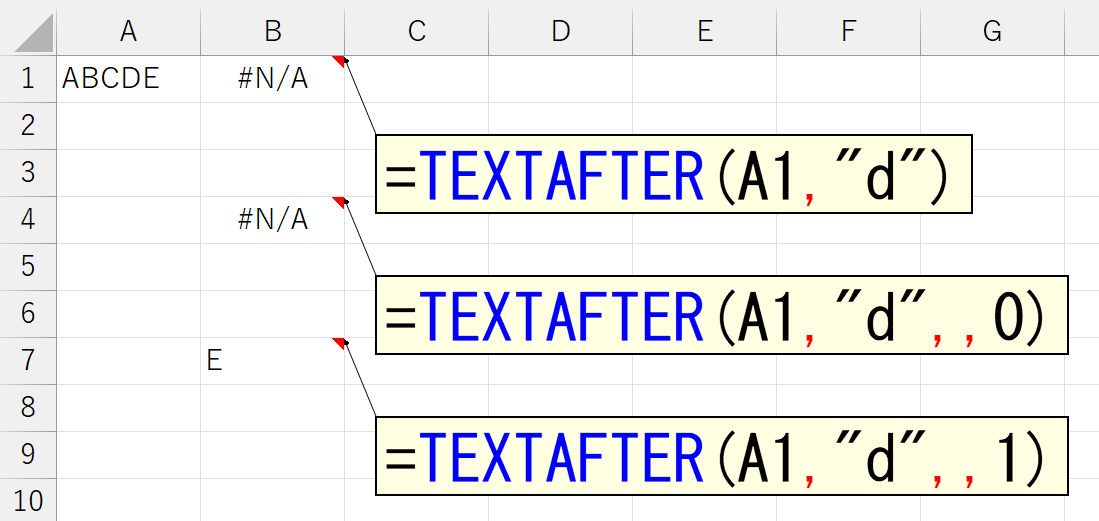
区切り文字が複数存在するとき、引数「区切り位置」に指定した位置で区切ることができます。上図は、セルA1の文字列中に、区切り文字であるハイフン(-)が3つ存在し、左から3番目のハイフン(-)で区切っています。このとき、存在しない4番目のハイフン(-)を指定したら、どうなるでしょう。
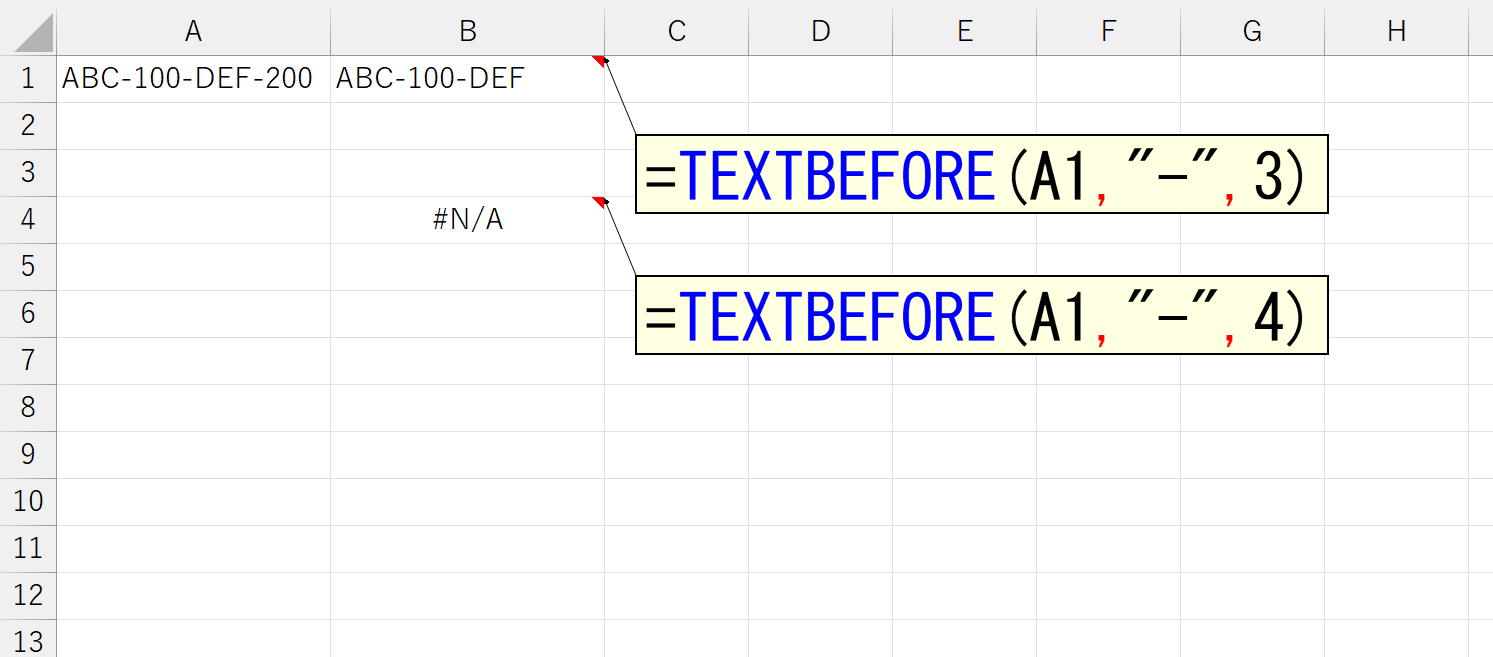
結果はご覧のとおり。4番目の区切り文字など存在しないのですから、エラーになって当然です。では、ここで引数「文字列の終端(match_end)」を指定してみます。まずは「0」から。

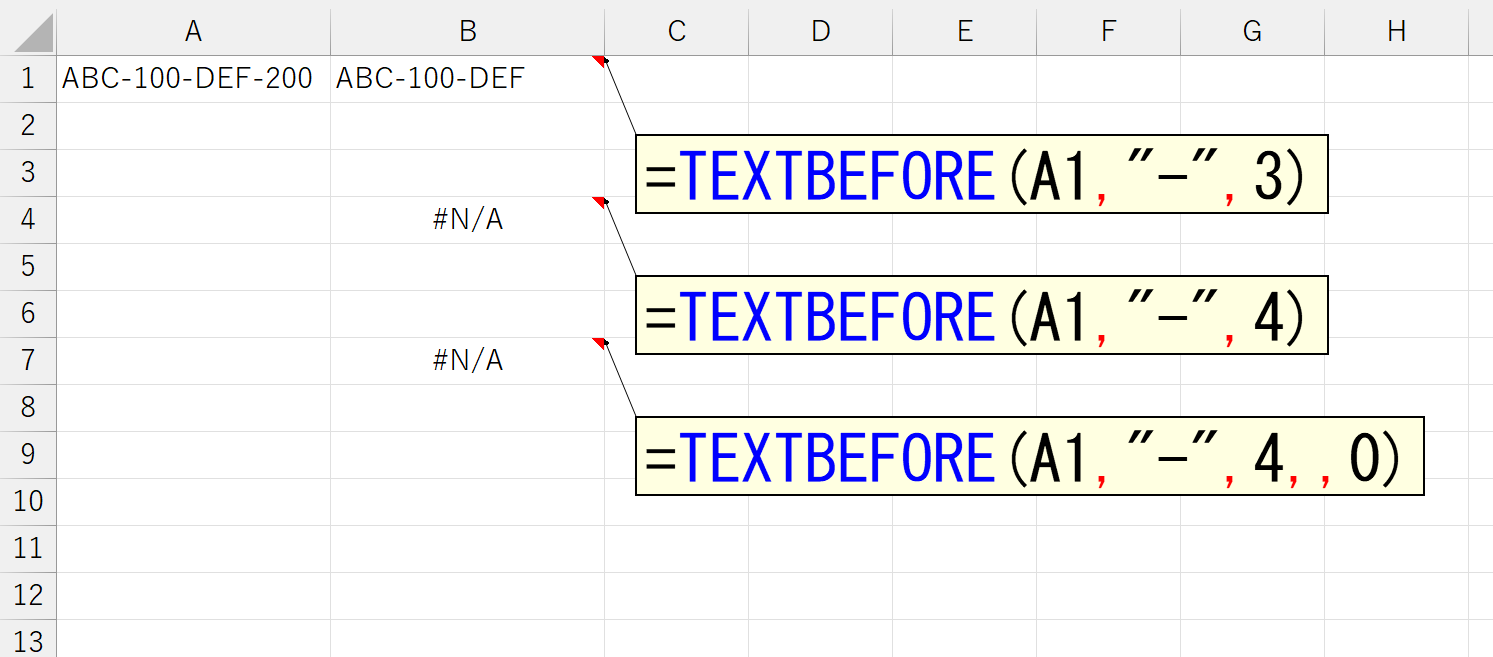
結果はエラーです。これは引数「文字列の終端(match_end)」を省略したときと同じ動作です。では、次に「1」を指定してみましょう。

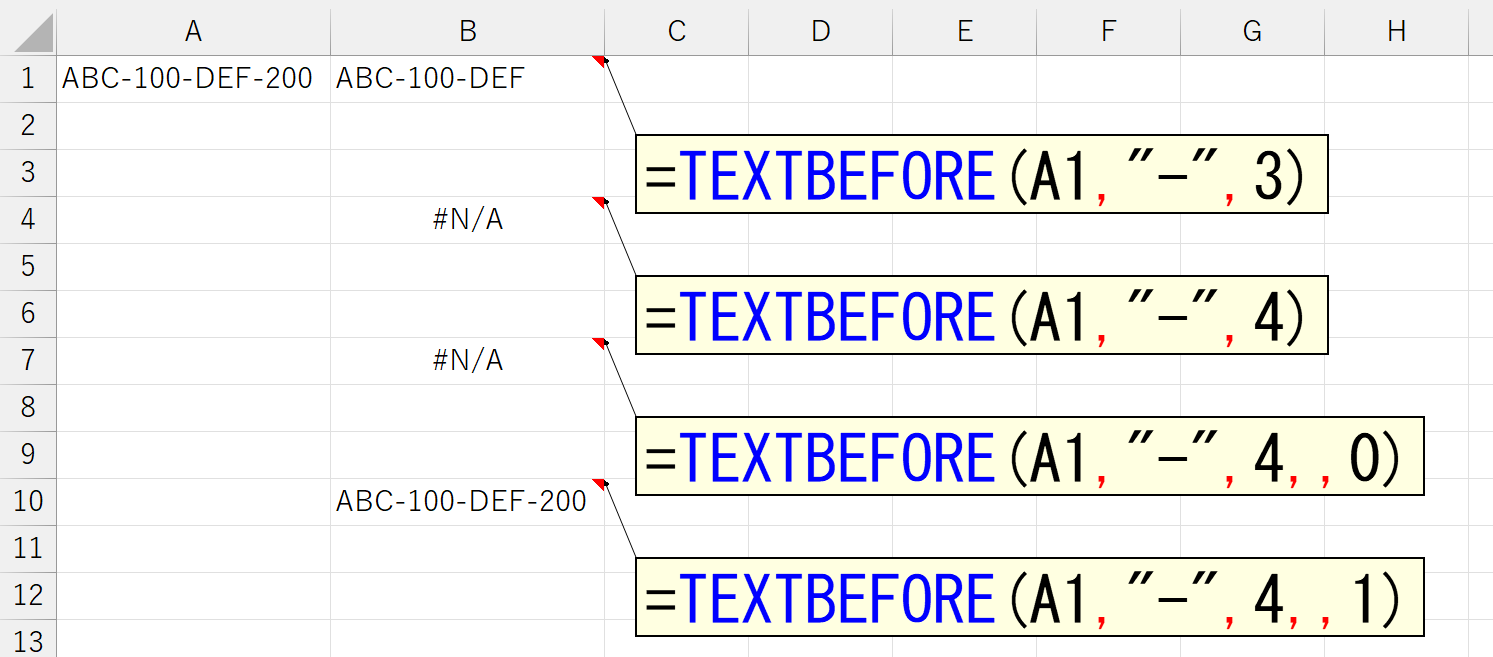
今度は左側を抜き出せました。じゃ、引数「区切り位置」に、もっと大きい数値を指定したらどうなるでしょう。
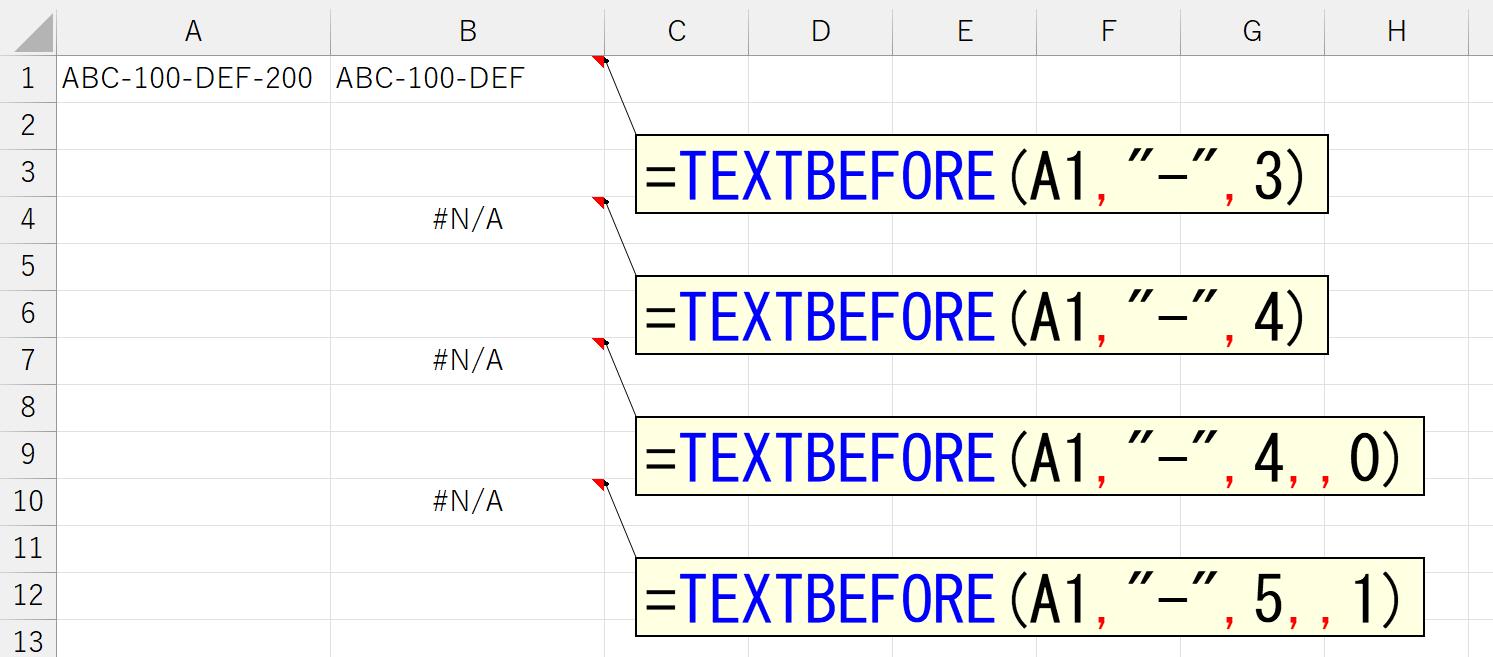
これは無理でした。以上のことから、この引数「文字列の終端(match_end)」は次のように推測できます。
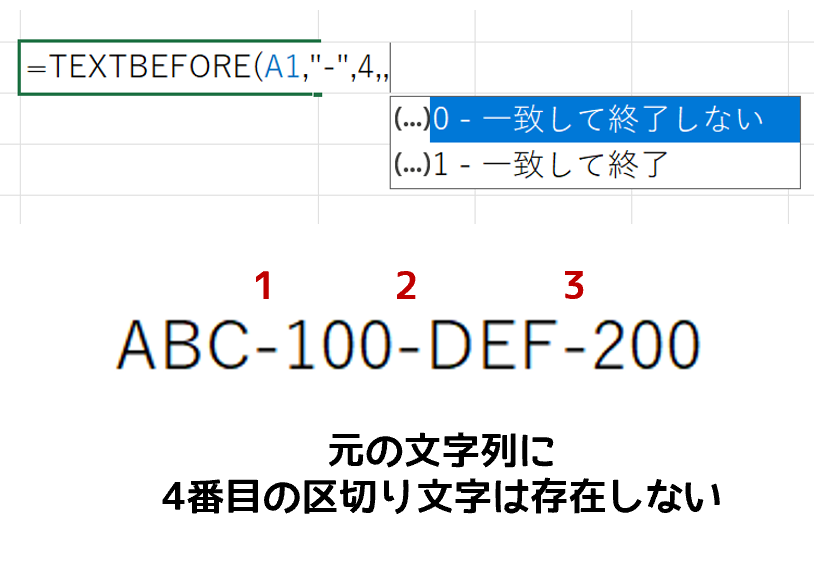
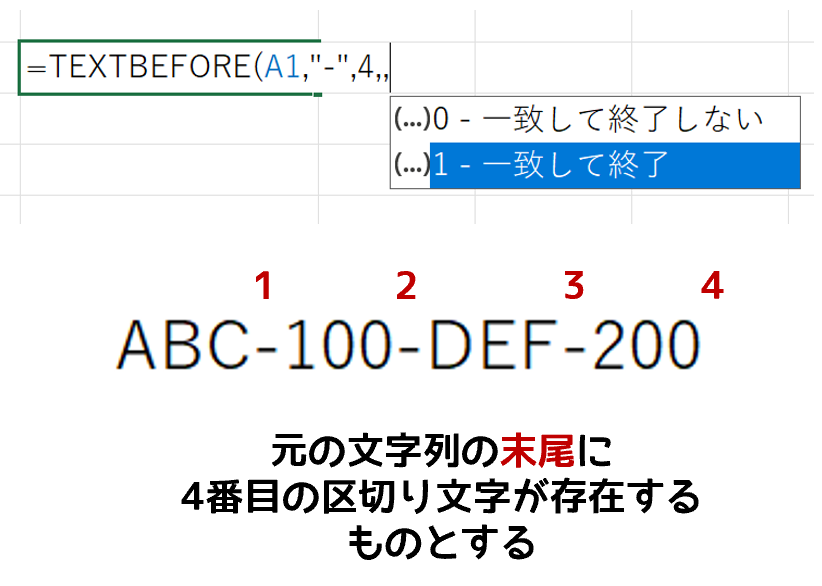
たぶん、こういうことだと思います。これね、ここまで分かったところでヘルプを見ると、何となく意味が分かりますけど、ここに至るまで、かなり試行錯誤したんですよ。それに、冒頭で「意味が分からない」と書いたのは、もうひとつ、そもそもこの引数って、どんなときに活躍するんだろうって。その、使いどころがイメージできないという意味もあります。まぁ、まだベータ版ですし、今後どうなるか分かりません。もし何か便利に活用できる事例を思いついたら、また追記します。
見つからないとき(if_not_found)
指定した「区切り文字」が存在しないとエラーになります。
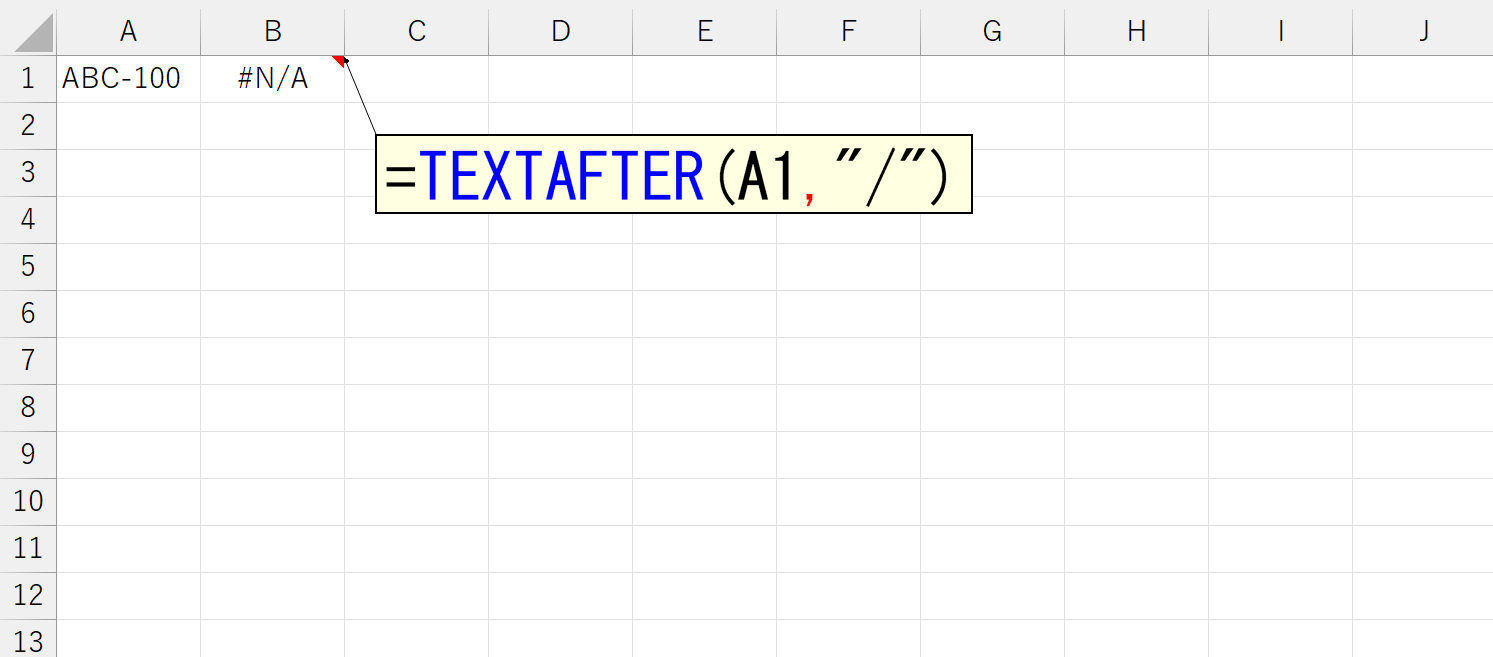
こうしたエラーは、IFERROR関数と組み合わせることで対応できます。
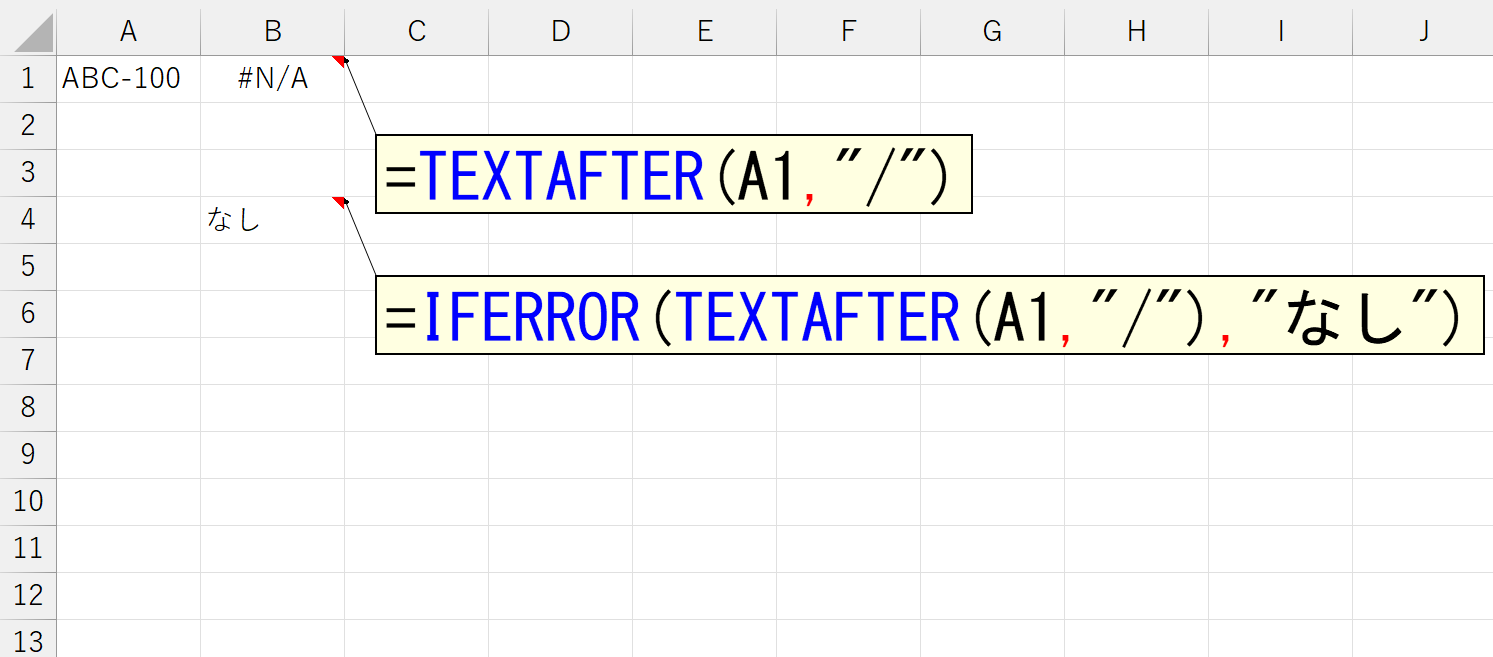
できますけど、もっと簡単な方法があります。TEXTAFTER関数とTEXTBEFORE関数には、最後の引数に「見つからないとき」が用意されています。この引数は省略可能で、省略すると上図みたくエラーになりますが、指定しておくと、「区切り文字」が見つからなかったときに何らかの文字を表示したり、別の計算をするなどが可能です。
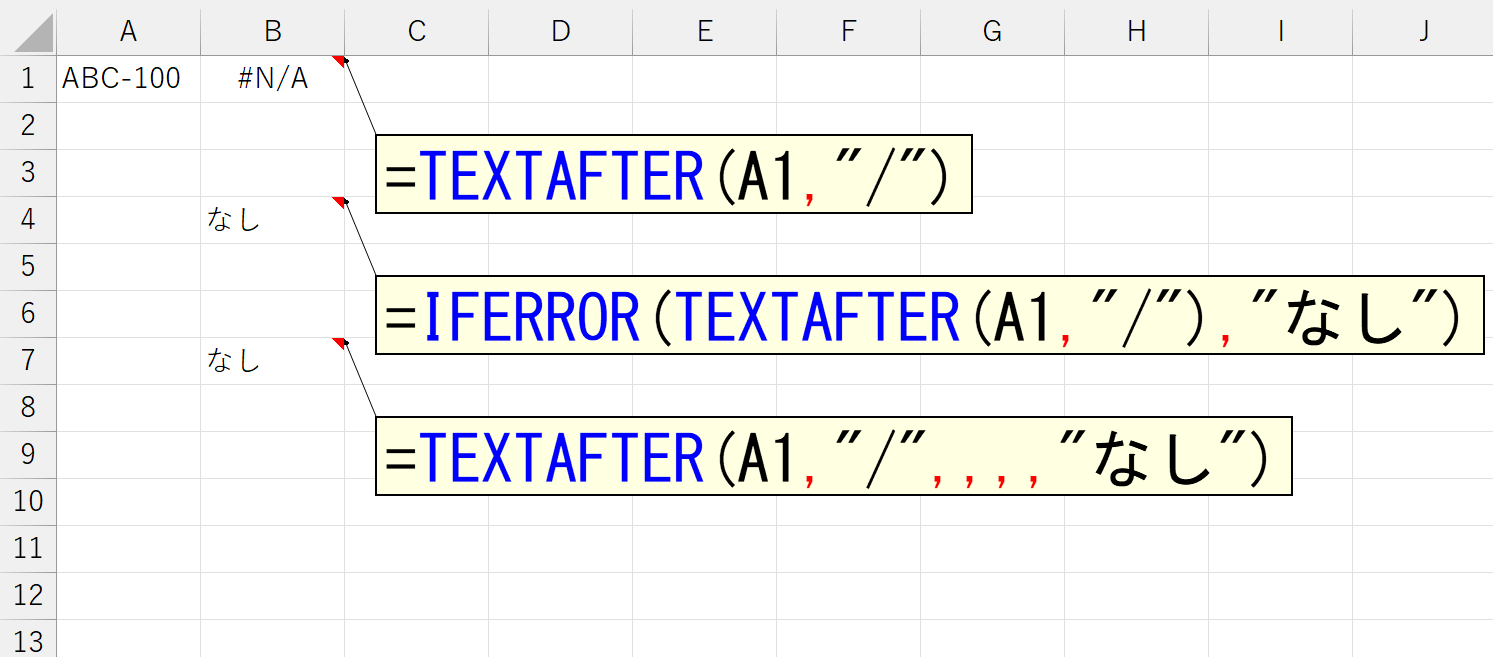
ただし、勘違いしないでください。この引数「見つからないとき」は、単に"区切り文字がみつかったかどうか"を判定しているに過ぎず、TEXTAFTER関数やTEXTBEFORE関数そのものの、あらゆるエラーを回避する仕組みではありません。
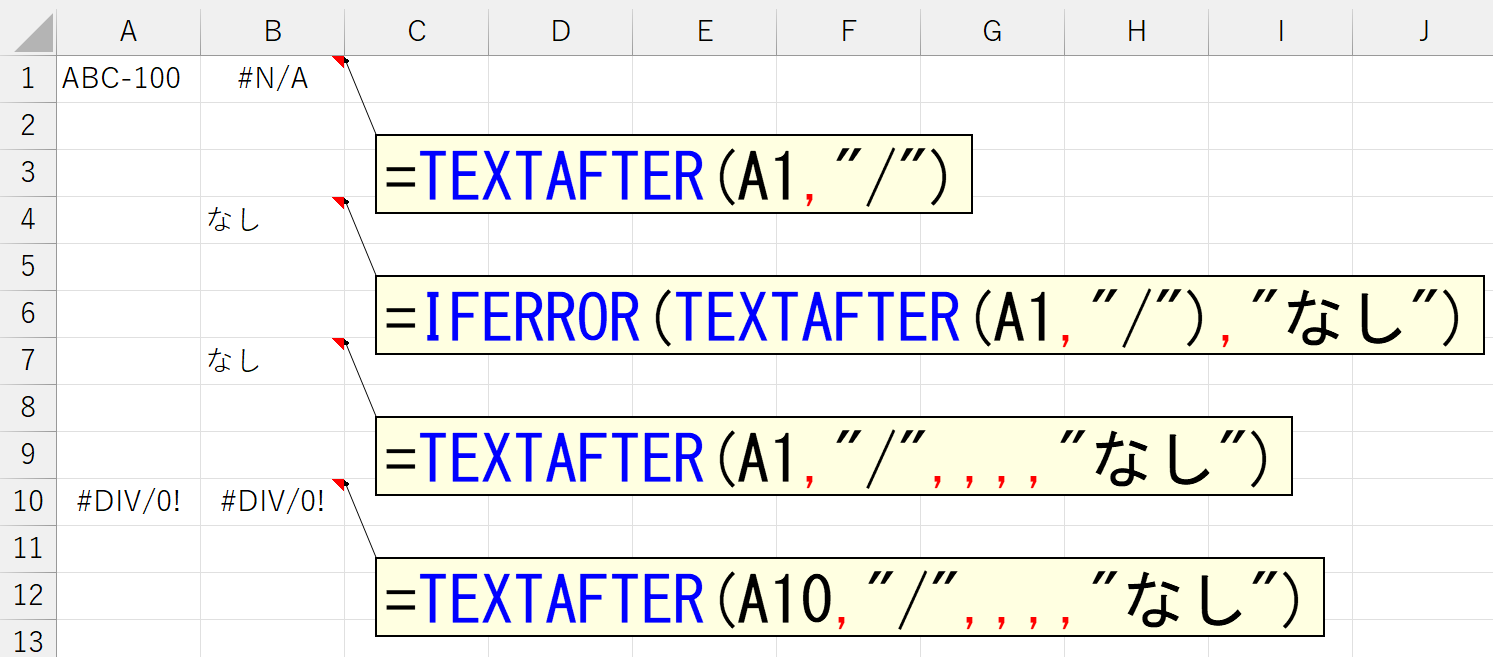
上図の最後は、セルB10のTEXTAFTER関数で「元の文字列」としてセルA10を指定しています。しかし、セルA10が何らかの理由でエラーだったとき、そもそもTEXTAFTER関数は機能しません。もちろんTEXTAFTER関数はエラーになります。これは「区切り文字が見つからなかった」というレベルの話ではありませんので、引数「見つからなかったとき」を指定していても意味がありません。こんなときもあるでしょうから、IFERROR関数と組み合わせる方法も忘れないようにしてくださいね。
複数の区切り文字を指定できる
さて、上記で「ちょっと便利な仕組みも搭載されている」と書きましたが、引数「区切り文字」には、複数の文字や記号を同時に指定できます。下記は、区切り文字に"-"と"/"を指定しています。
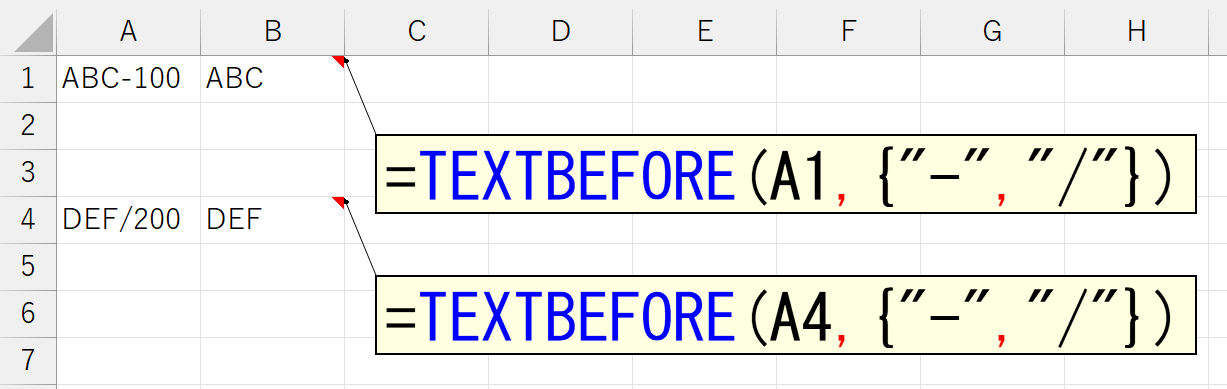
複数の区切り文字を指定すると「(区切り文字は)○または×」とみなされます。上記でしたら、区切り文字は「"-"または"/"」ですから、どちらで区切られていても同じように抽出できます。複数の区切り文字を指定するときは、それらを配列形式で指定します。数式内に直接配列を記述するときは、上記のように中括弧{}で囲みます。こうして数式内に直接記述した配列形式の値を「配列リテラル」とか「配列定数」などと呼びます。リテラルとは聞き慣れない言葉かもしれませんが、プログラムコードの中に直接記述する値を指します。ザックリ言えば、今回のように文字や数値を中括弧{}で囲むと「これって、配列だよ」という意味になります。ちなみに、"tanaka"のようにダブルコーテーション("")で囲むものを文字列リテラル、#2022/3/20#を日付リテラルなどと呼びます。
複数の区切り文字を同時に指定できるということは、次のようなデータも楽勝です。

苗字と名前の間にスペースが入っていますが、そのスペースが半角だったり全角だったりと。このような"データの揺れ"や"データのブレ"って、実務ではつきものです。従来でしたら、まず関数かマクロで統一してから処理をしていたでしょうけど、TEXTBEFORE関数やTEXTAFTER関数だったら、両方の区切り文字を同時に指定しちゃえば済みます。
囲まれている範囲を抜き出す
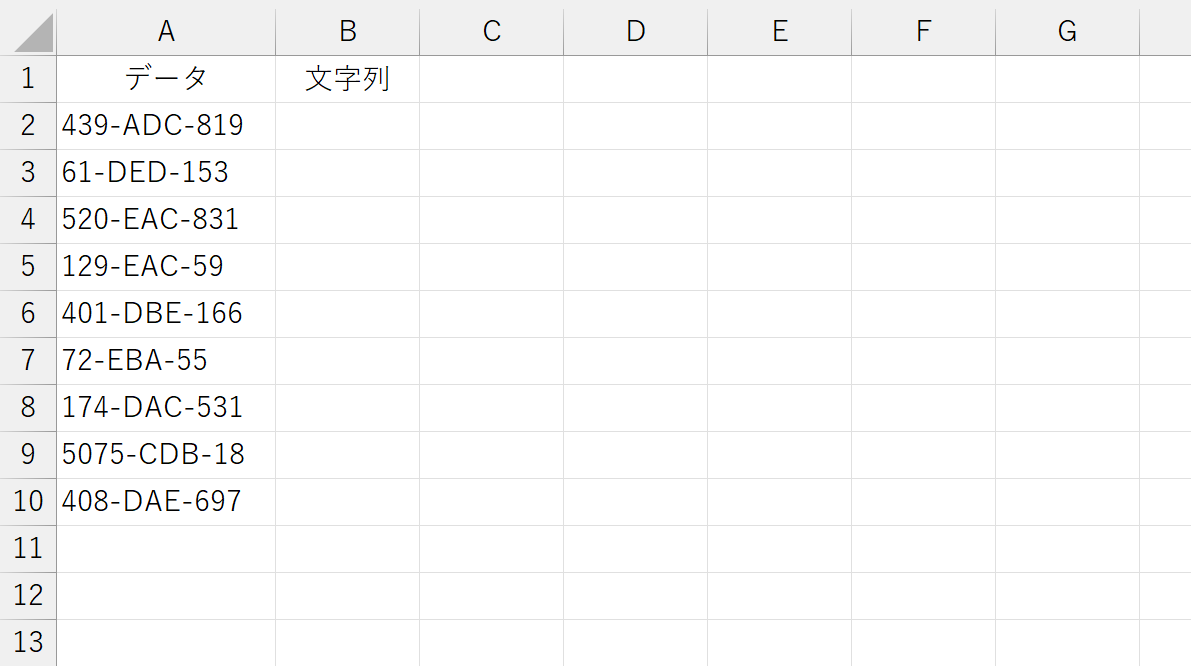
上図のようなデータがあったとしましょう。「数値-文字列-数値」という組合せで、数値の桁数は決まっていません。このデータから「ハイフン(-)で囲まれた部分」の文字列だけを抜き出します。さあ、どうしましょう。これ、従来の関数だけで実現するのは、けっこう面倒くさいです。FIND関数を2回やらなくちゃですし。こうなると、ほとんどの方が、Excelの機能である[データ]タブの[区切り位置]を使うでしょう。ただ、その結果は元のデータにリンクしていません。こんなときも、今回ご紹介しているTEXTBEFORE関数やTEXTAFTER関数を使えば楽勝です。
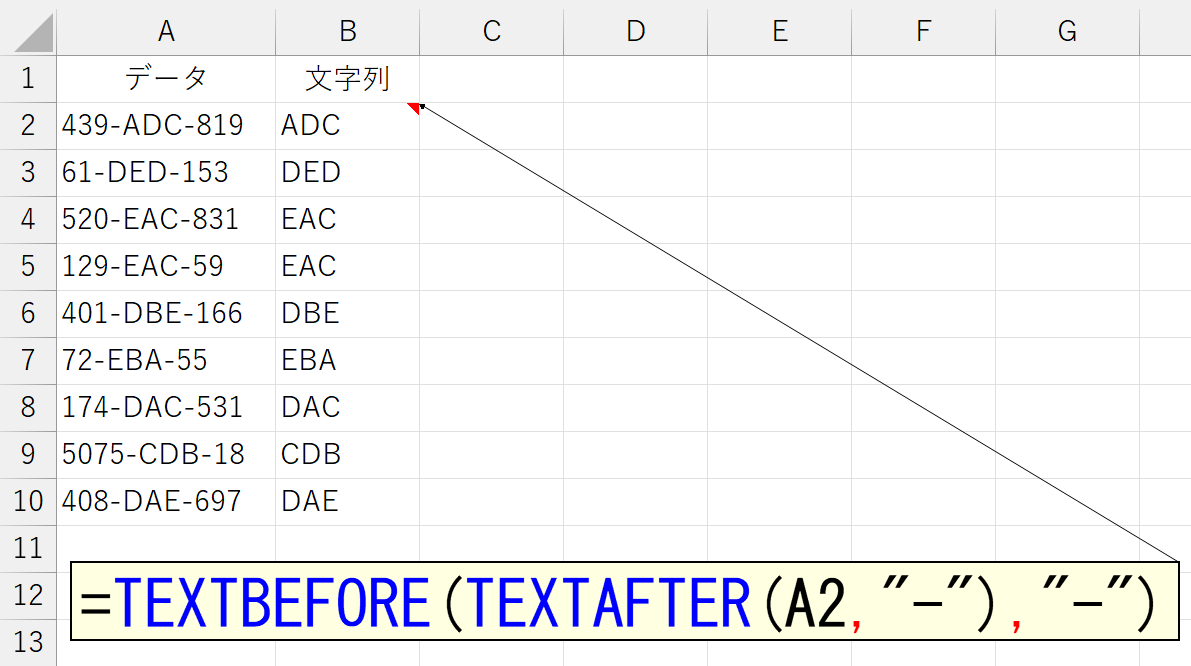
順番はどうでもいいんですけど、要するに2回区切ってやればいいんです。これに、上記で解説した「複数の区切り文字を指定できる」を組み合わせたら、かなりいろいろなことができそうです。もちろん、このケースでしたらTEXTSPLIT関数でも対応可能です。TEXTSPLIT関数に関しては、下記のページをご覧ください。
では、最後に応用編です。下図のようなデータを考えてみましょう。
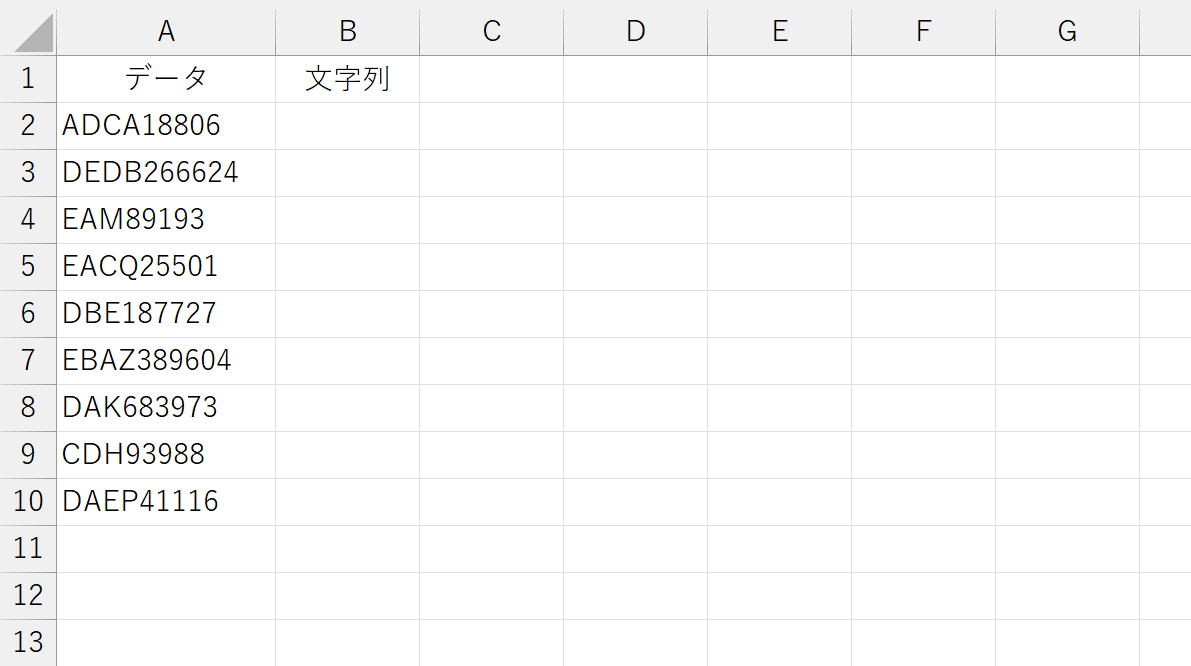
今度のデータは「文字列+数値」という組合せです。間を区切っている文字や記号はありません。このデータから「文字列部分」だけを抜き出してみましょう。まずは、先頭のデータだけ考えてみます。
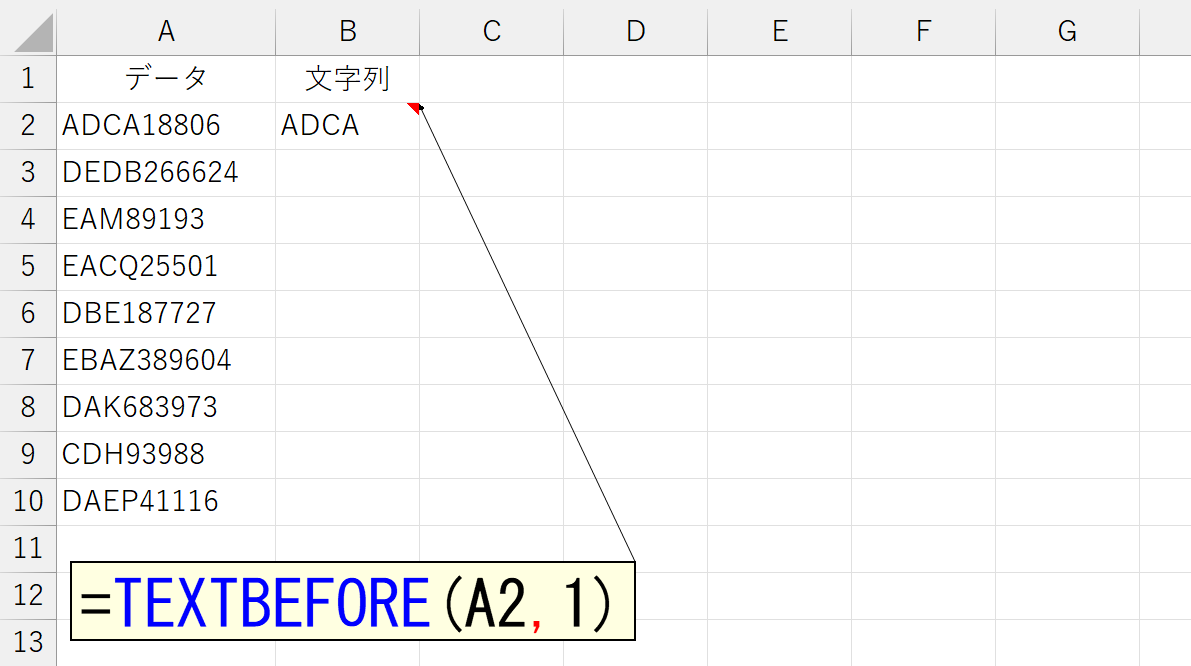
数値部分の先頭、つまり"最初に登場する数値"は「1」です。したがって、それを区切り文字に指定すればいいですね。では、次のデータ(セルA3)はどうでしょう。今度の"最初に登場する数値"は「2」です。「1」と「2」の両方に対応させたいのですから、区切り文字を2つ指定します。
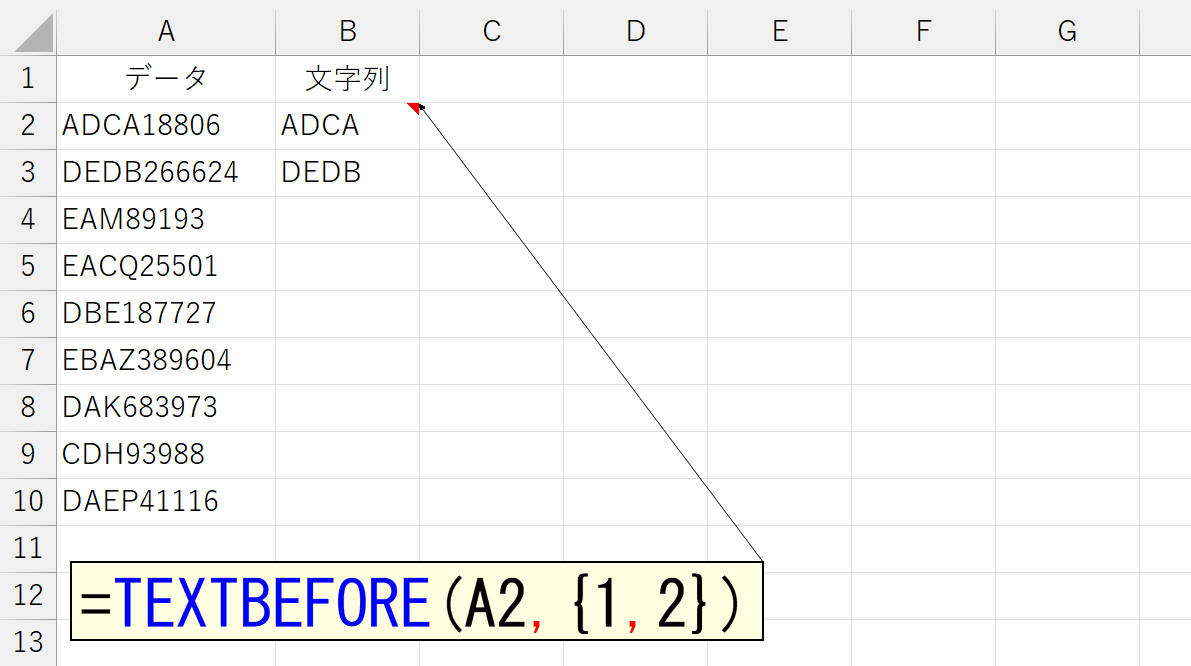
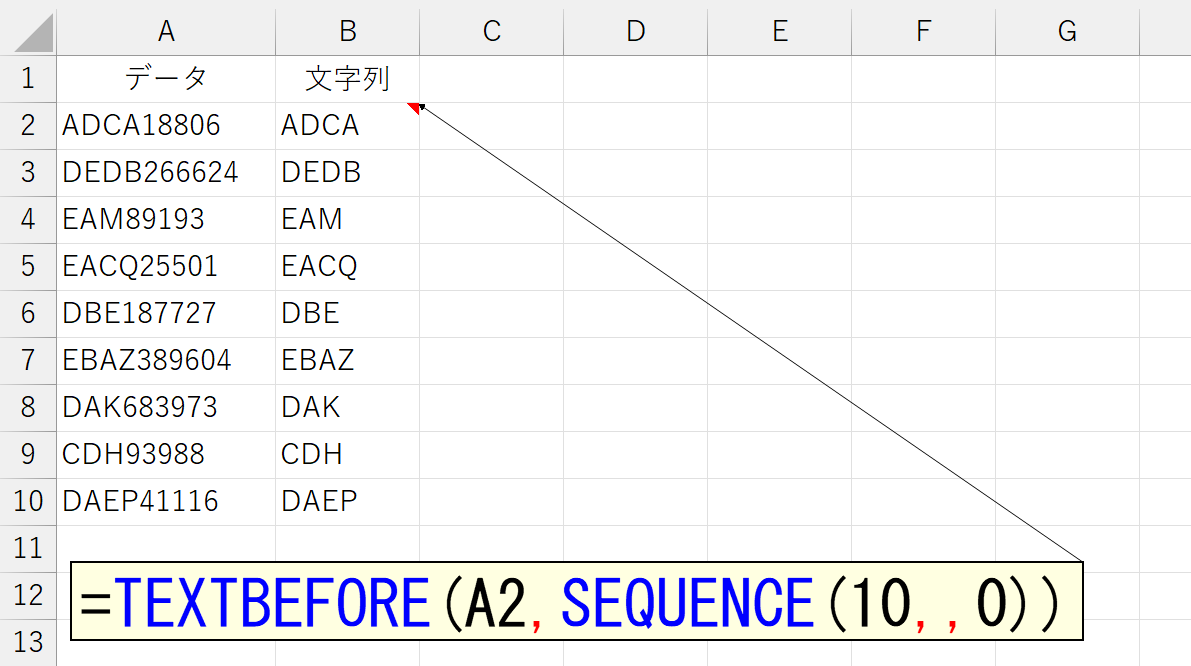
こんな調子で考えればいいのですが、"最初に登場する数値"がいくつになるか分かりません。「0」から「9」までの10種類を指定しなければなりません。もちろん「=TEXTBEFORE(A2,{0,1,2,3,4,5,6,7,8,9})」と書いてもいいんですが、なんか美しくありません。こんなときは、実務ではめったに使う機会がないSEQUENCE関数を使いましょう。SEQUENCE関数に関しては、下記のページをご覧ください。
ちなみにこれ、同じ発想で「じゃ、後ろの数値部分だけ抜き出すには」って考えるとドツボにはまります。さっきのは"最初に登場する数値"を区切り文字に指定できたので簡単でした。でも"最後に登場する文字"って、どうすれば分かるのでしょう。よしんば分かったところで、それが"先頭から何番目の区切り文字"かが分からなかったら、今回のやり方では対応できません。私も、ちょっと考えてすぐ「あ、めんどくさそ、やめた」って思いました。そんなときは発想の転換です。「文字列+数値」の組合せで、左の文字列部分なら抽出可能です。だったら、実際に欲しい数値部分って「文字列+数値」から、文字列部分を除去したものになります。はい、実務では必須のSUBSTITUTE関数の出番ですね。
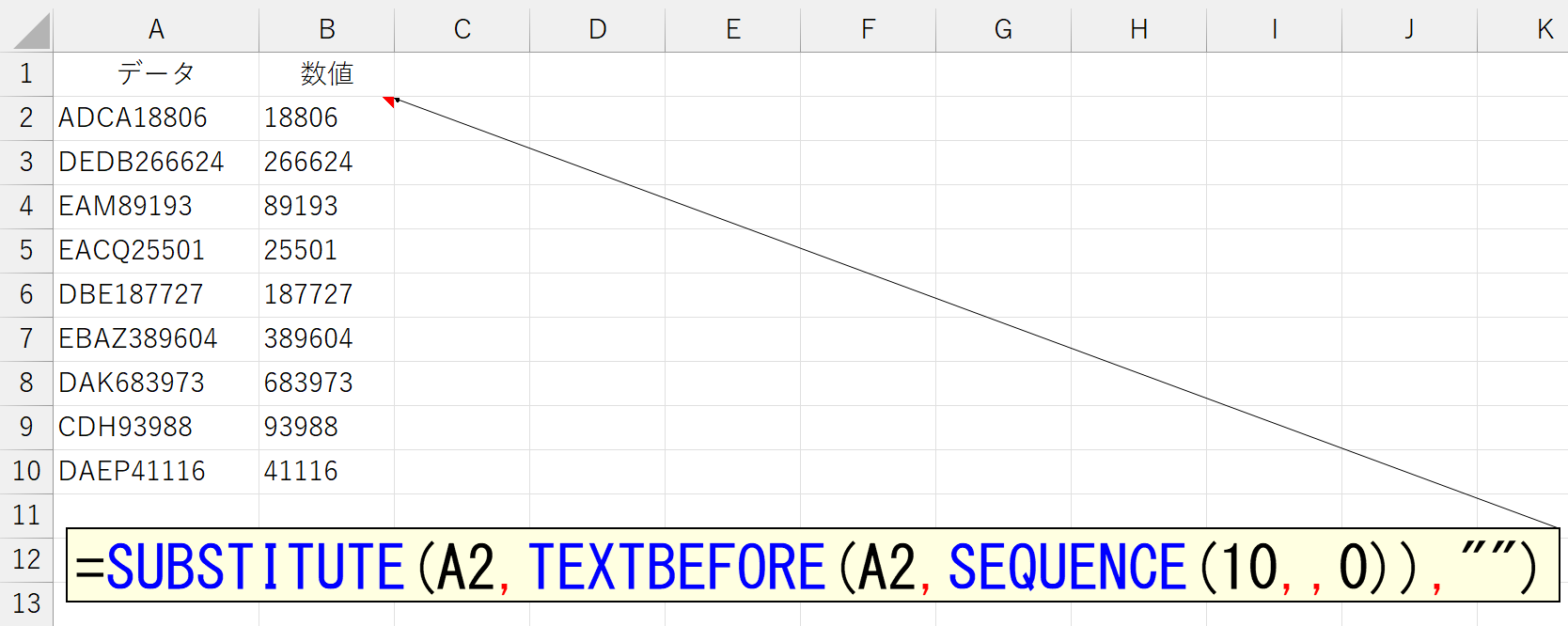
なんか楽しくなってきたので、もうひとつオマケです。
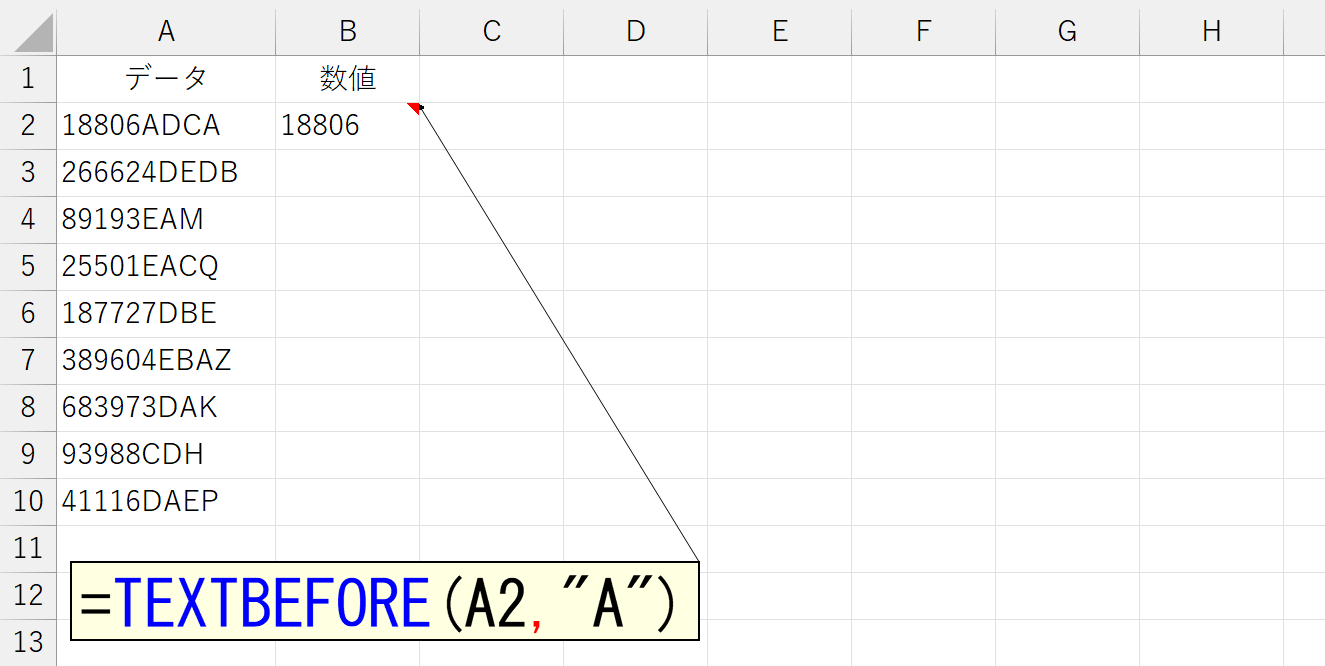
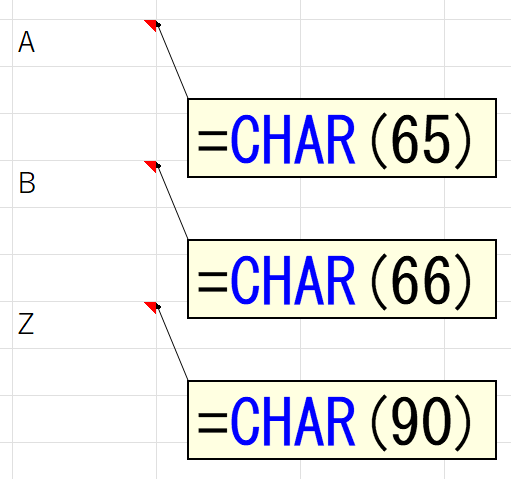
今度は「数値+文字列」のパターンです。なお、話を簡単にするため文字列はすべて「半角の大文字アルファベット」とします。発想はさっきと同じ、"最初に登場する文字列"を区切り文字として指定すればいいです。もちろん、どんな文字が先頭に来るか分かりませんので、"A"から"Z"までの26文字を指定しなければなりません。これ、「=TEXTBEFORE(A2,{"A","B","C",…,"Z"})」なんてやってたら日が暮れちまいます。でもぉ、さっきの「=TEXTBEFORE(A2,{0,1,2,3,4,5,6,7,8,9})」は数値だったからSEQUENCE関数で作れたけどぉ、今度のはアルファベットでしょ?文字っしょ?連続した文字を作るのって、どーすりゃいいの?な~んてお悩みのあなたに朗報です。いいことをお教えしましょう。コンピュータでは、すべての文字にコードが割り当てられています。そのコードとは数値です。ちなみに、アルファベットの"A"は65、"B"は66で、"Z"は90です。これはASCIIコードと呼ばれます。興味のある方はWikipediaなどで調べてください。そして、こうしたコードから、そのコードに割り当てられている文字列を返す関数ってのが、Excelには昔から備わっています。それは、CHAR関数です。ちなみに"キャラクター関数"と読みます。"チャー関数"じゃありませんからね。くれぐれも、そんな恥ずかしい読み間違いはしないでくださいね。
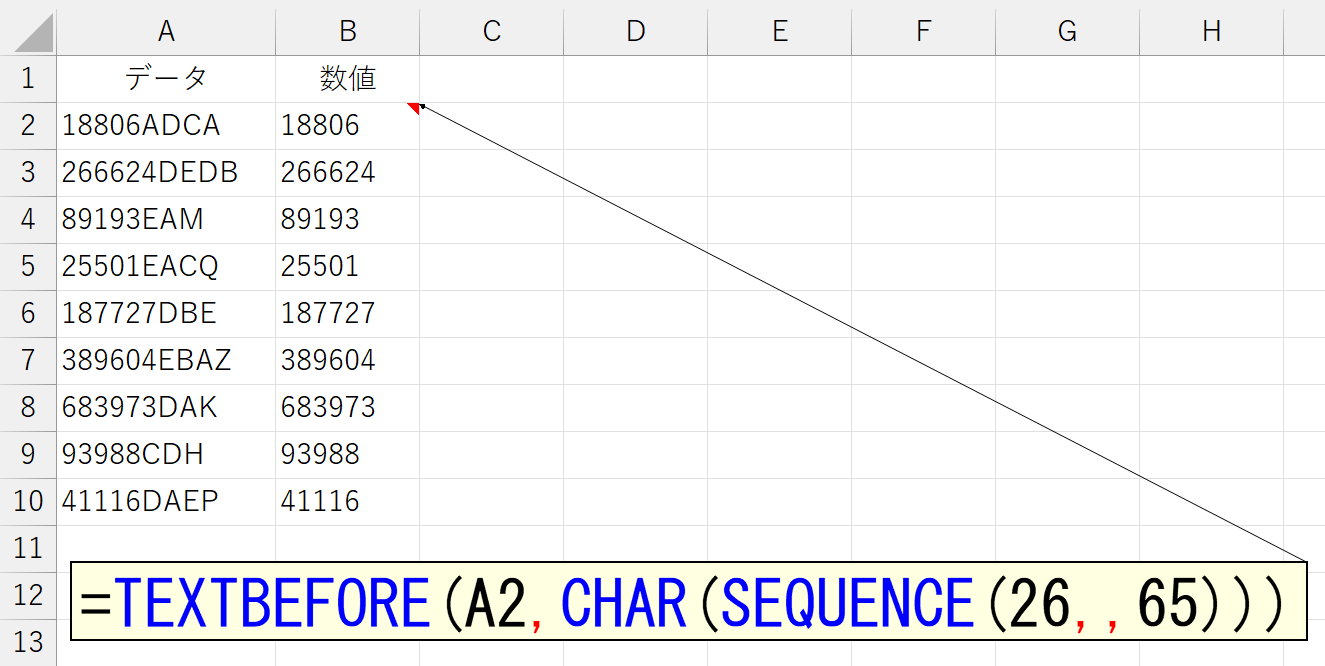
「TEXTBEFORE(A2,"A")」というのは「TEXTBEFORE(A2,CHAR(65))」なのですから、CHAR関数の括弧の中が、65・66・67…90ってなればOKです。
"A"から"Z"までの連続したアルファベットを作るとなって、ワークシートの列文字を使えば何とかなるんじゃね?って思った方はいませんか?いますよね。私もさっき思いました。今回は文字コードをCHAR関数でアルファベットに変換しましたが、もちろん列文字を使う手もあります。でも、そっちの方が面倒くさいですよ。一応お見せします。

ADDRESS関数の第1引数に出てくる「1」と、後半に連続して出てくる「26」「1」「2」「1」の意味が、パッと見て分かりますか?「これでできる」って話ではなく、こういう数式を実務で使っちゃうと、このシートの作成者がいなくなったら、引き継いだ後任者が気絶する、ってことになります。くれぐれも実務では「できればいい」と安易に考えるのではなく、自分にとって悩ましい数式や、他人に分かりやすく説明できないような数式は、使わないようにしてください。