GROUPBY 関数
2023年11月に追加されたGROUPBY関数の解説です。ちなみに、本稿は2024年4月に書いています。新しい関数が追加されたら、できるだけ早く解説しようと考えていますが、この関数に関しては時間がかかりました。意外と奥が深いからです。ただ、半年近く経って、ひとつ言えるのは、現在メッチャ使ってるということです。そもそも、これは何をする関数かと言えば、簡単にザックリ言うと「SUMIFやCOUNTIFを、ワンタッチで計算」してくれるヤツです。「だったら、SUMIF関数やCOUNTIF関数を使えばいいやん!」って思うかも知れませんが、実務では必須のSUMIF関数とCOUNTIF関数って、すごく特殊な関数です。両者は2002年に追加されたのですが、他の関数と比べて異様です。確かに便利なのですけど、便利を追求した結果、現在主流である"スピル"とは相性が悪いです。2002年の時点で、"スピル"みたいな"表計算ソフトの常識を覆すような仕組み"が実装されるなんて、想定しなかったのでしょうね。
まずは、簡単な実行結果をごらんください。なお、本稿では、特に明記しない限り、元データは「Data」という名前のテーブル形式にしています。
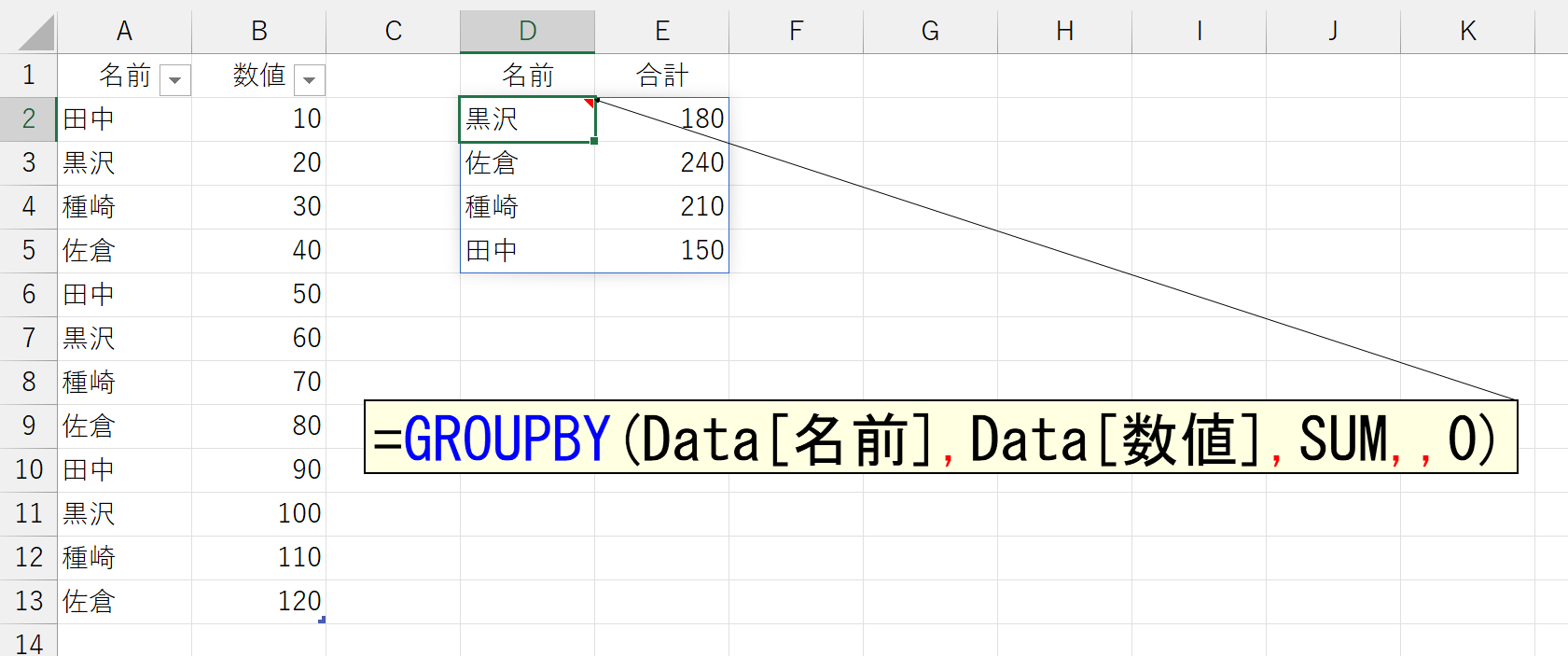
引数
GROUPBY関数の引数は、次のとおりです。
GROUPBY(row_fields,values,function,field_headers,total_depth,sort_order,filter_array,field_relationship) 日本語で表すと GROUPBY(行データ,値,計算方法,ヘッダ,総計,並べ替え,フィルタ,リレーション) かな?
引数「行データ」「値」「計算方法」は必須です。それ以外の引数は省略可能です。引数が多くて分かりにくいので、順番に解説します。
引数「行データ(row_fields)」
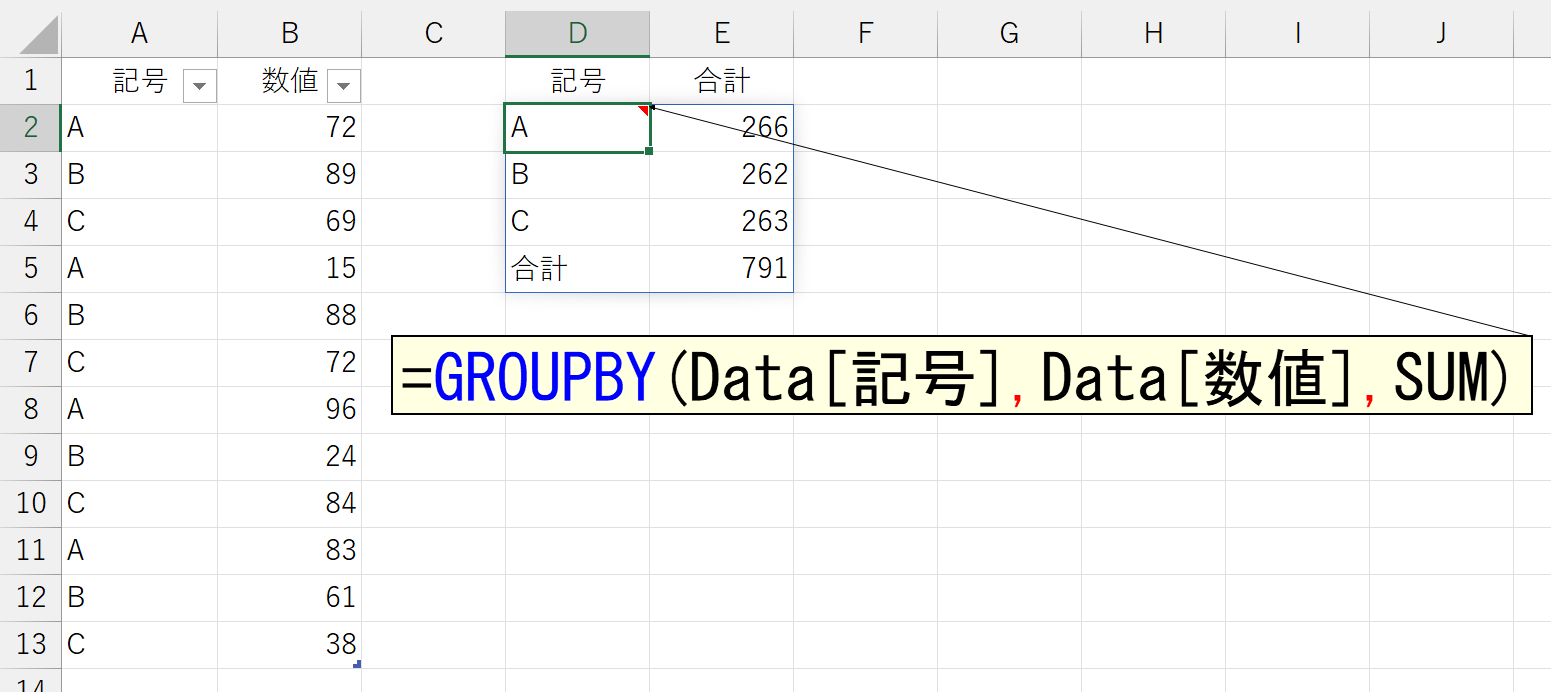
まず引数「行データ」から。まぁ、これは簡単ですね。グループ化する行データを指定します。
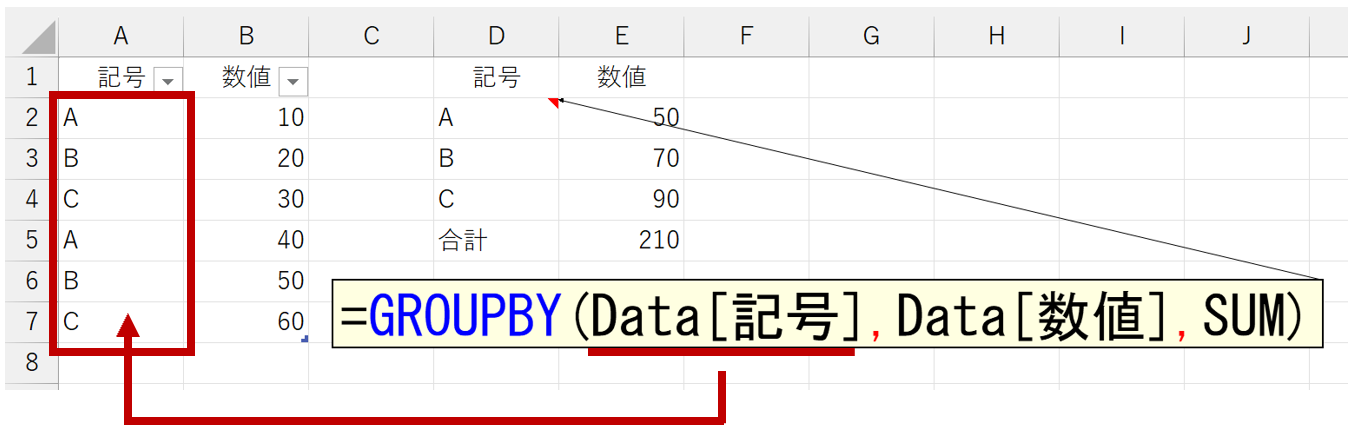
なお、引数「行データ」で指定した項目は、標準で自動的に並べ替えられます。
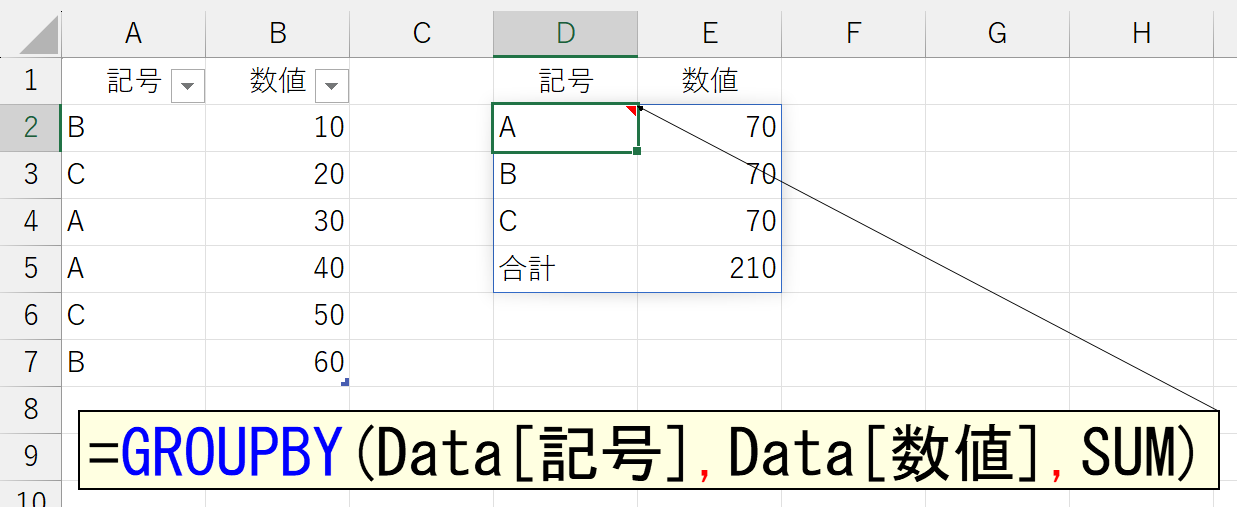
この並べ替えは、後述する引数「並べ替え」で並べ替える列や、"降順"を指定することも可能です。(適当にやったら、すべて合計が70になっちゃいましたが、偶然です。気にしないでください)
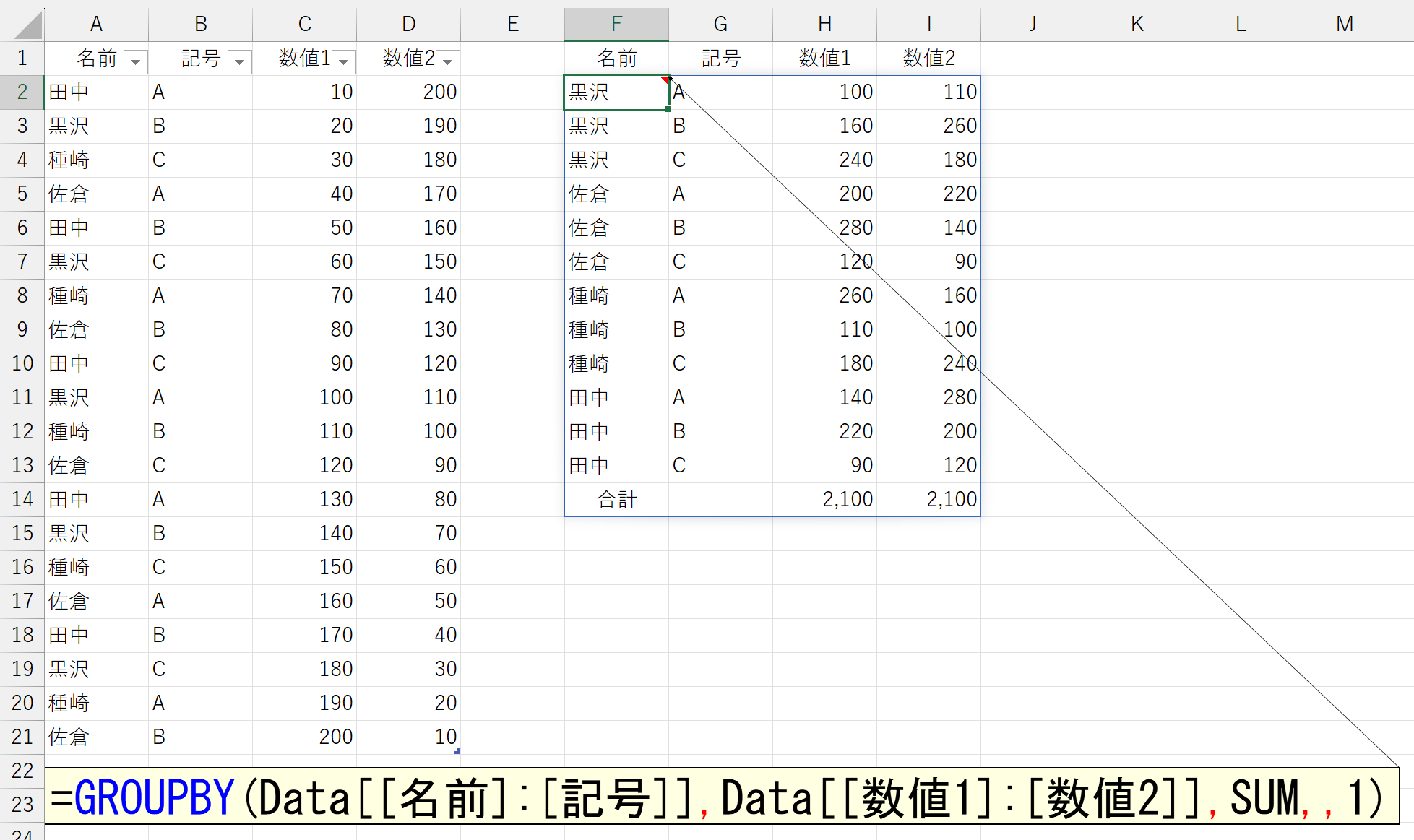
さて、引数「行データ」には、複数の列を指定できます。
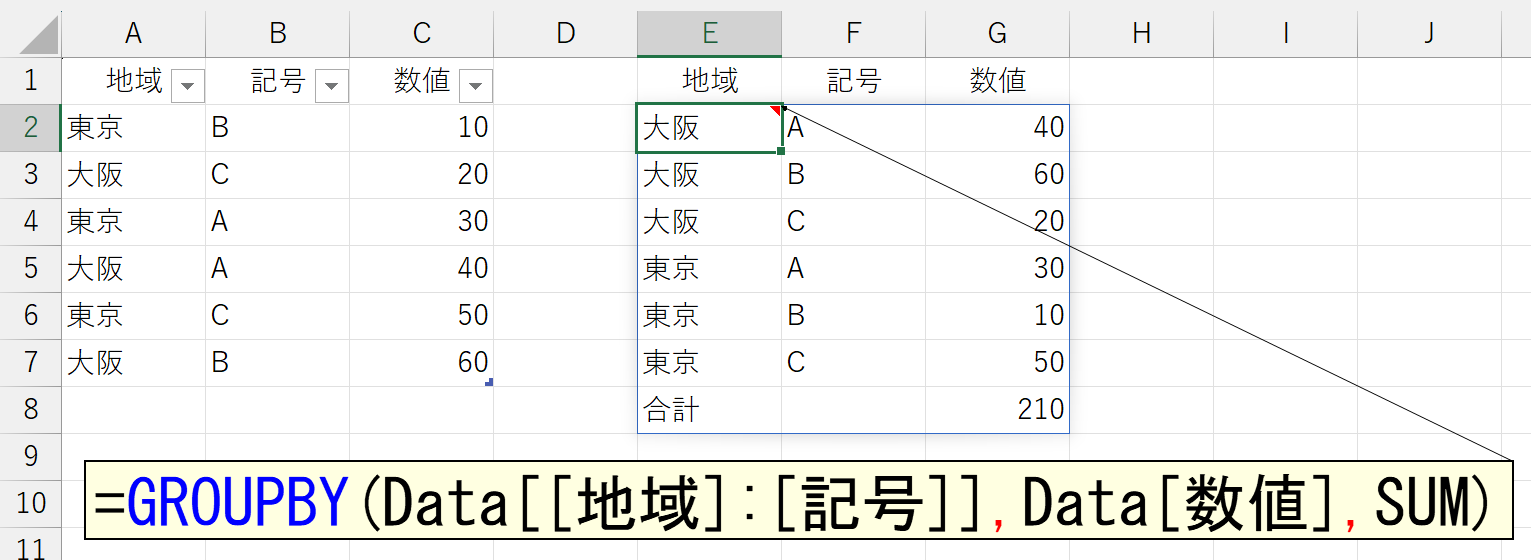
上図の、「行データ」と集計結果の位置関係に注目してください。当たり前ですが、「行データ」の左側にある項目が、集計結果でも左(上位)に来ています。
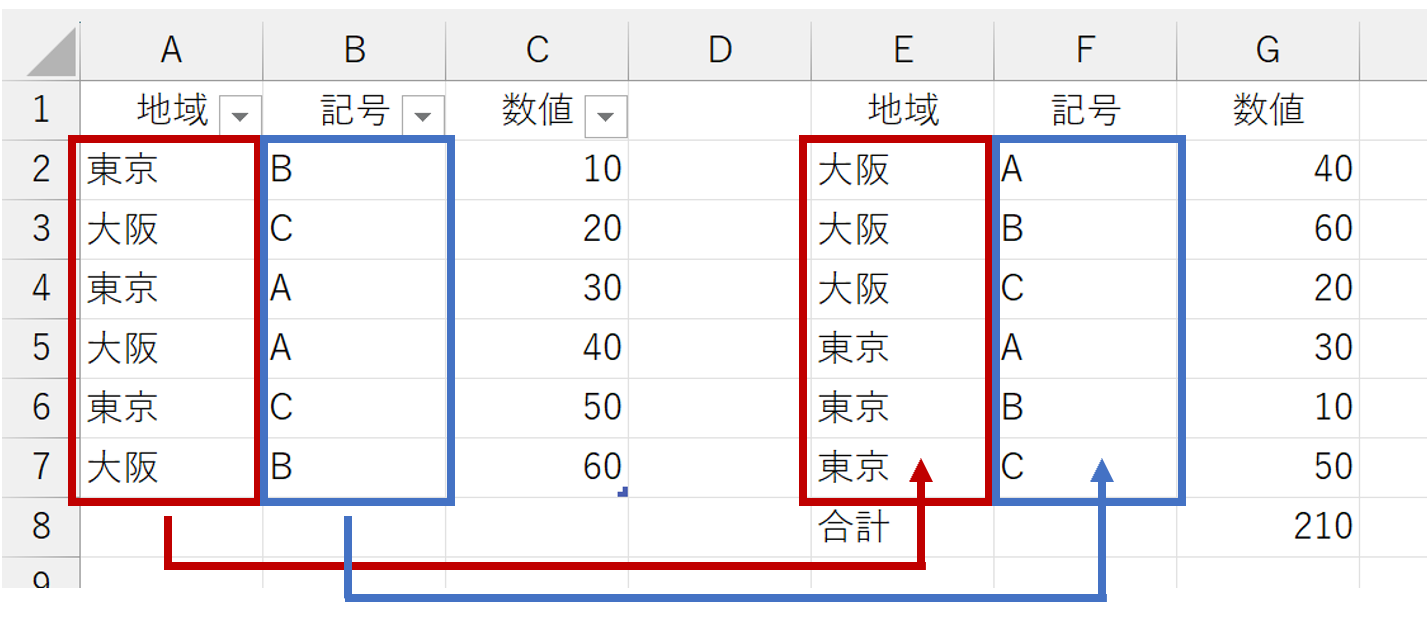
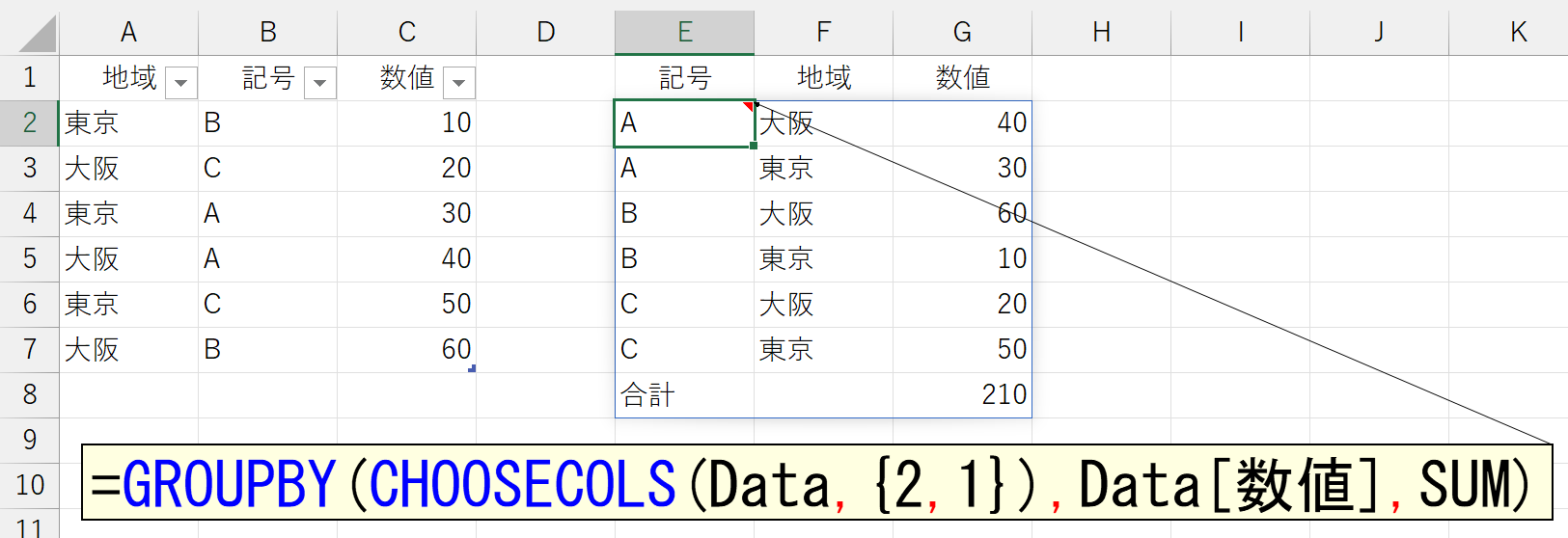
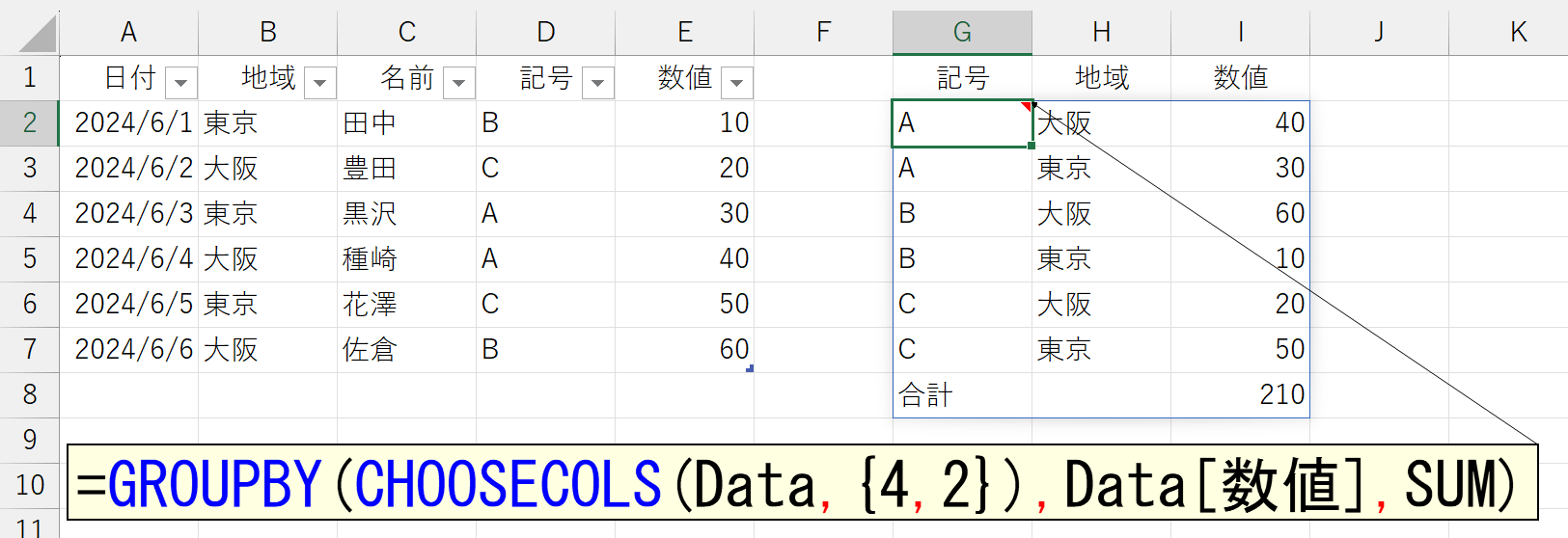
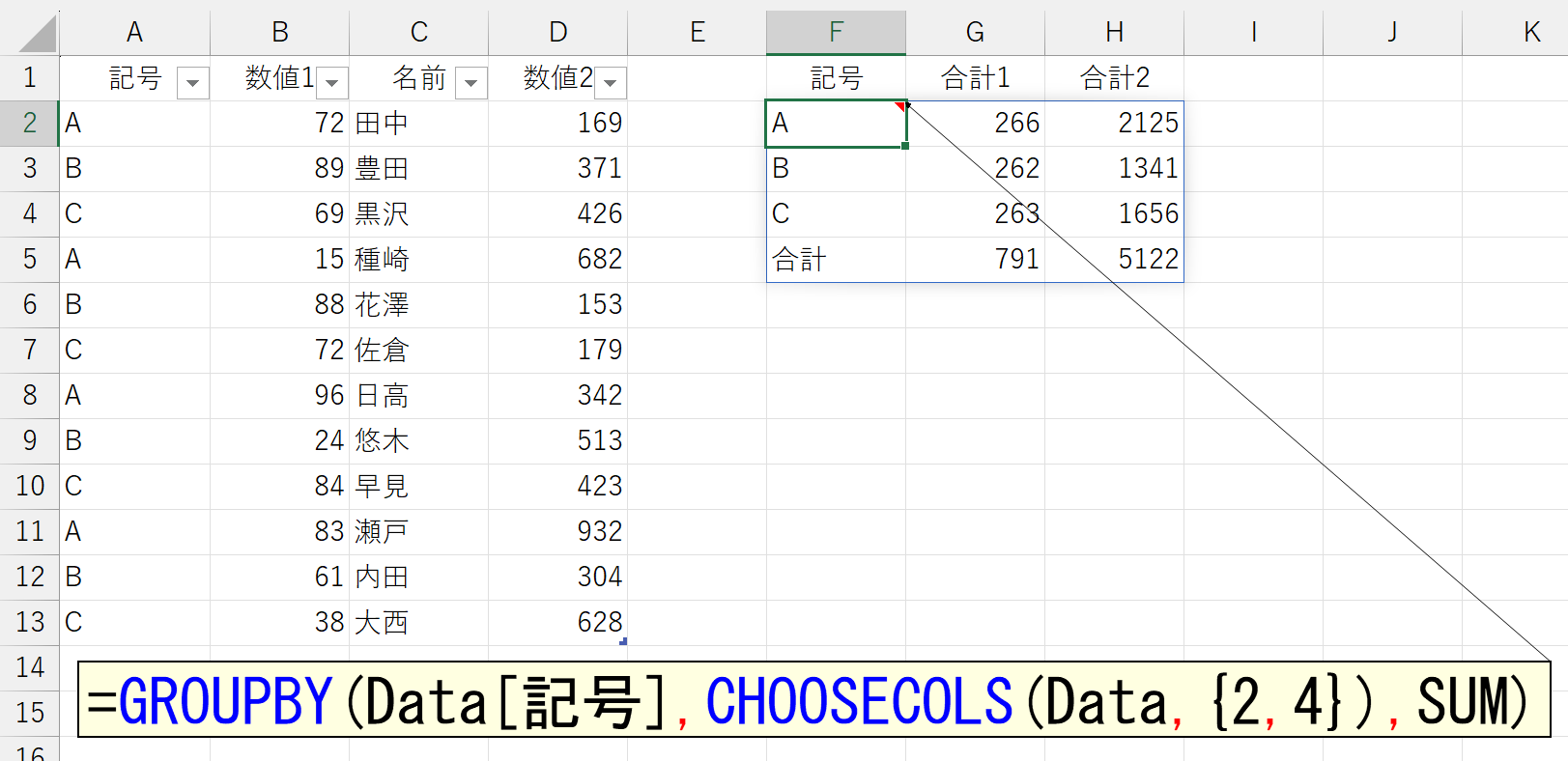
この順番を逆、というか、任意の順番で結果に反映させるには、ちょっと工夫が必要です。元データが[地域]-[記号]だったら集計結果も[地域]-[記号]になります。これが原則です。だから、集計結果を[記号]-[地域]にしたかったら、元データの並びを[記号]-[地域]とする必要があります。これには、いくつかの方法が考えられます。XLOOKUP関数やTAKE関数を使う手もありますが、ここでは汎用性の高いCHOOSECOLS関数を使ってみましょう。
CHOOSECOLS関数については、下記ページを参照してください。
CHOOSECOLS関数を使えば、次のように非連続(隣り合っていない)の列を「行データ」に指定することも可能です。実務では、よくあるケースですね。
引数「行データ」には、セル範囲だけではなく、何らかの計算結果も指定できます。要するに、配列になってればいいんです。
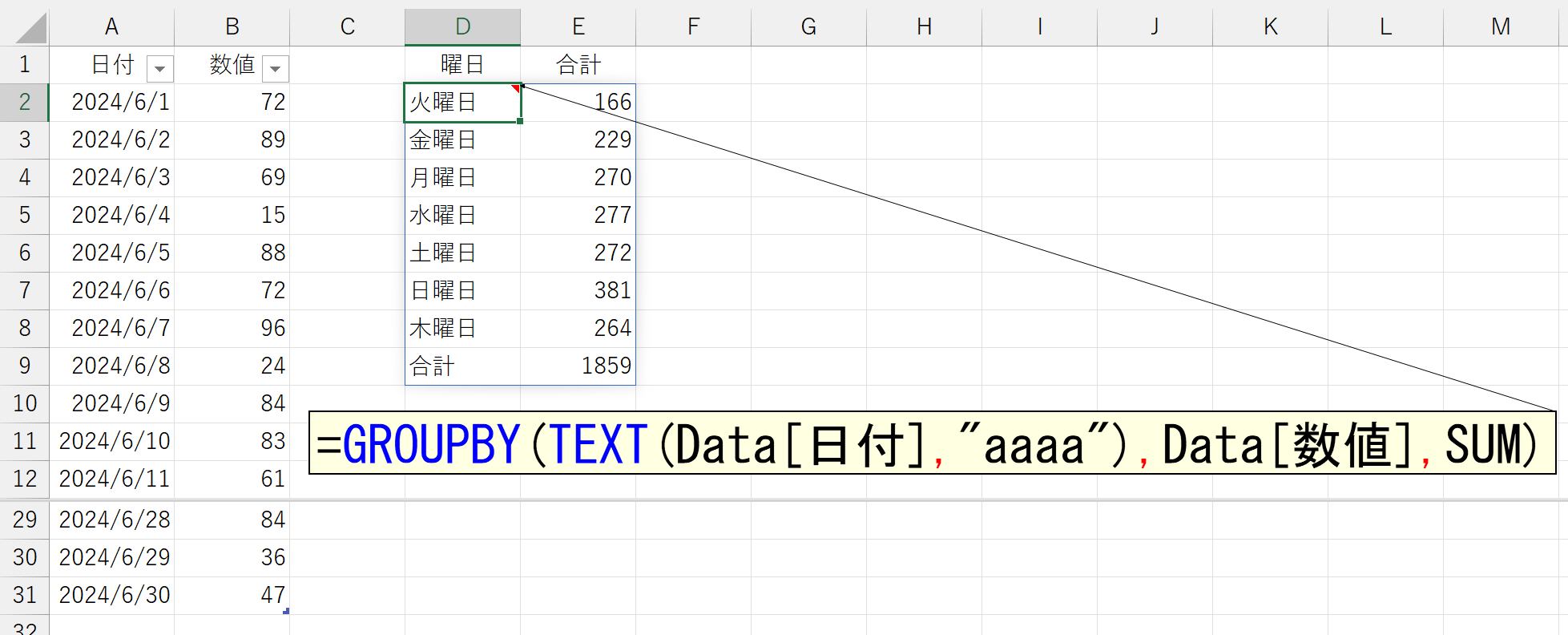
曜日を「月曜日」→「火曜日」→「水曜日」…のように並べ替えることもできます。詳しくは後述します。あるいは、こんなことも可能ですね。
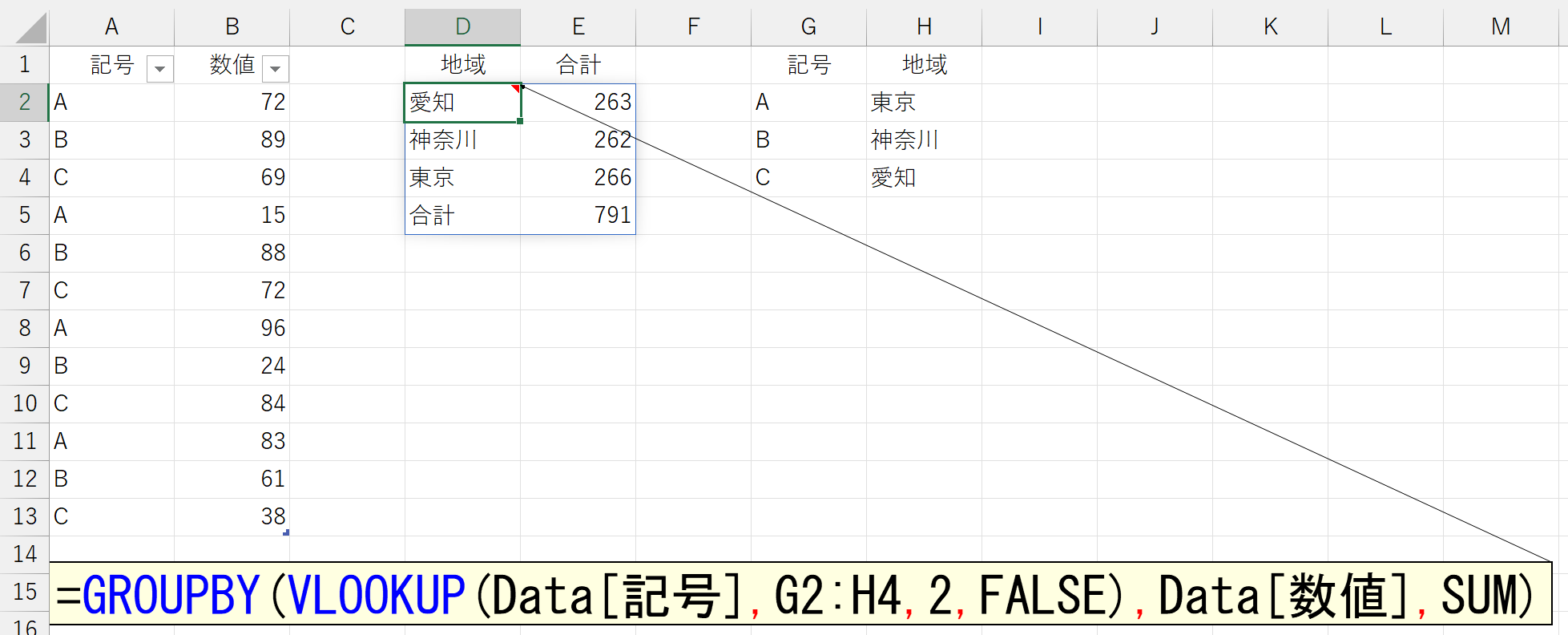
まぁ、発想しだいです。
引数「値(values)」
引数「値」には、計算の元になるセルを指定します。
引数「値」も、複数列を指定できます。
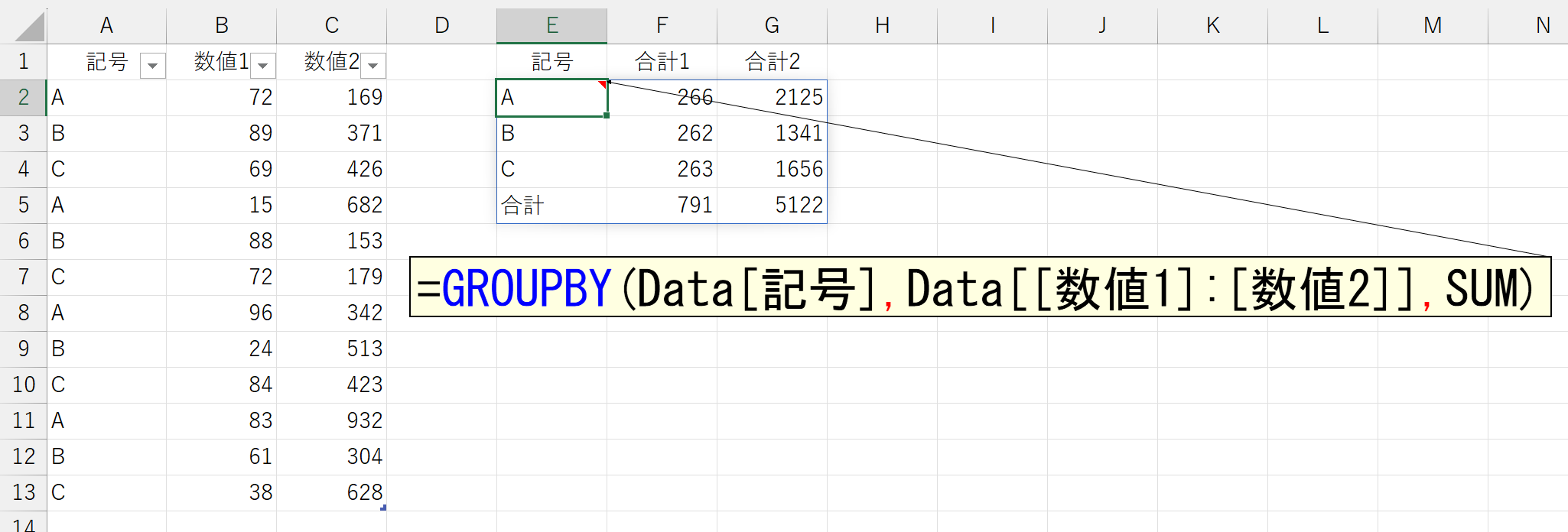
非連続の列を指定したいときは、こちらもCHOOSECOLS関数を使いましょう。
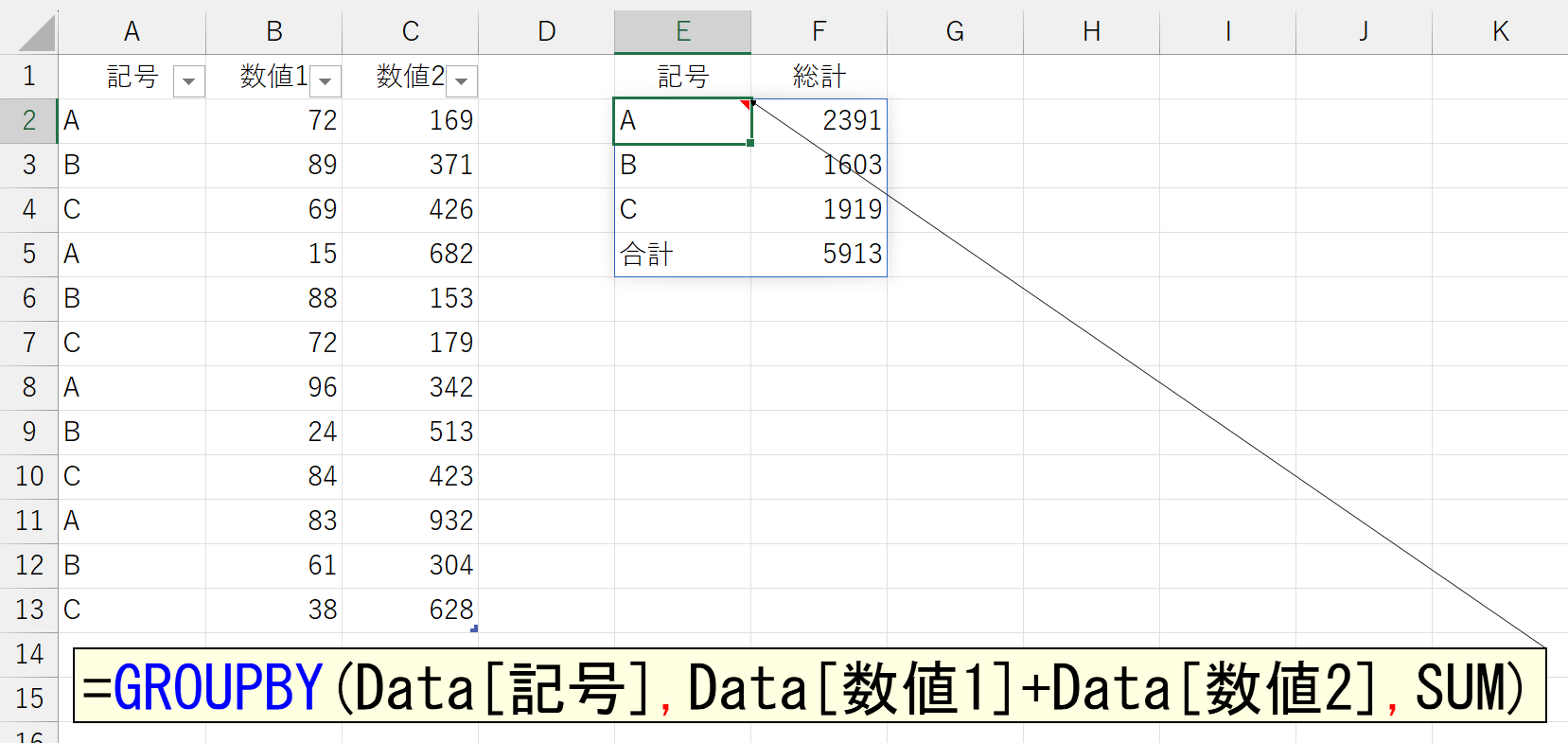
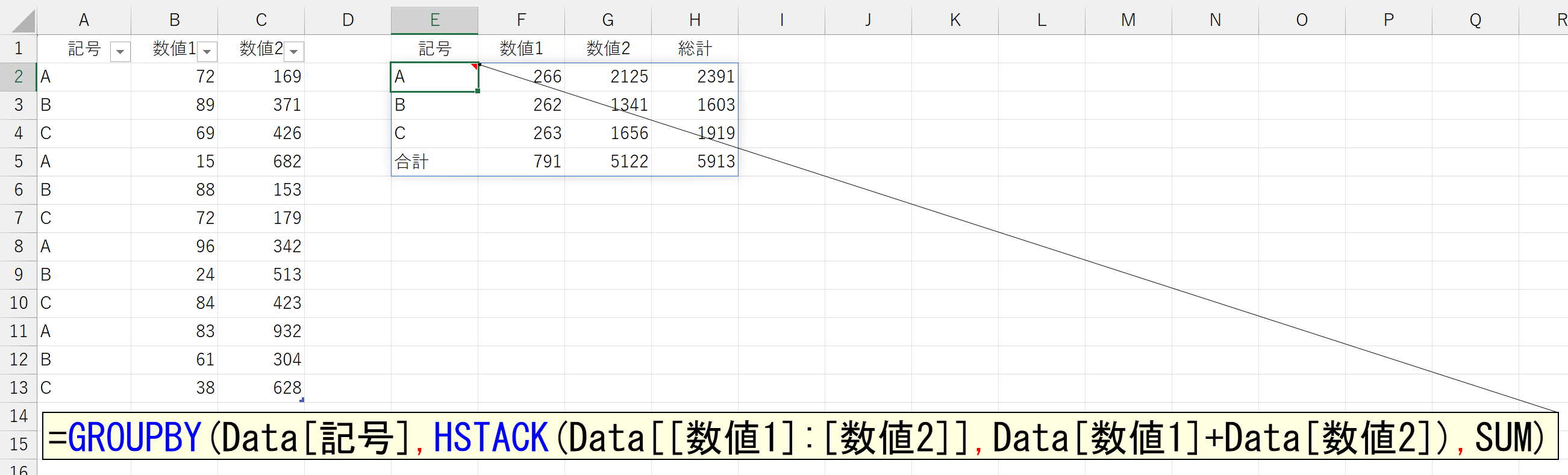
では、セルに入力されている値を、さらに計算したいときはどうしましょう。これは、"どんな計算をするか"によって難易度が変わってきます。ここでは、まずは簡単に「数値1+数値2」という合計を計算してみます。合計の結果だけを表示するのでしたら簡単ですね。
では、「数値1」「数値2」「総計」の3つを表示するには、どうしたらいいでしょう。こうなると、ちょっと面倒くさいです。なぜなら、「数値1」と「数値2」を足した「総計」は、シート内に存在しないからです。
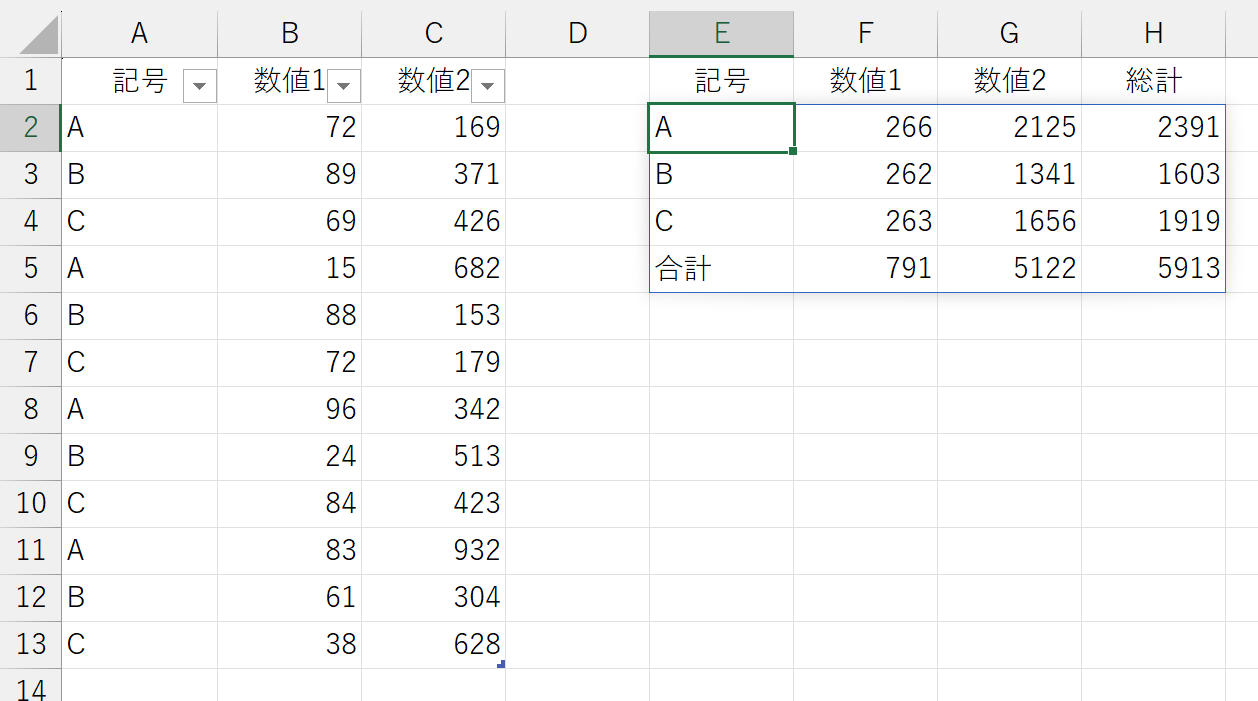
まず「数値1」と「数値2」の2列を指定する方法です。これは悩むこともありませんね、普通に指定すればいいです。
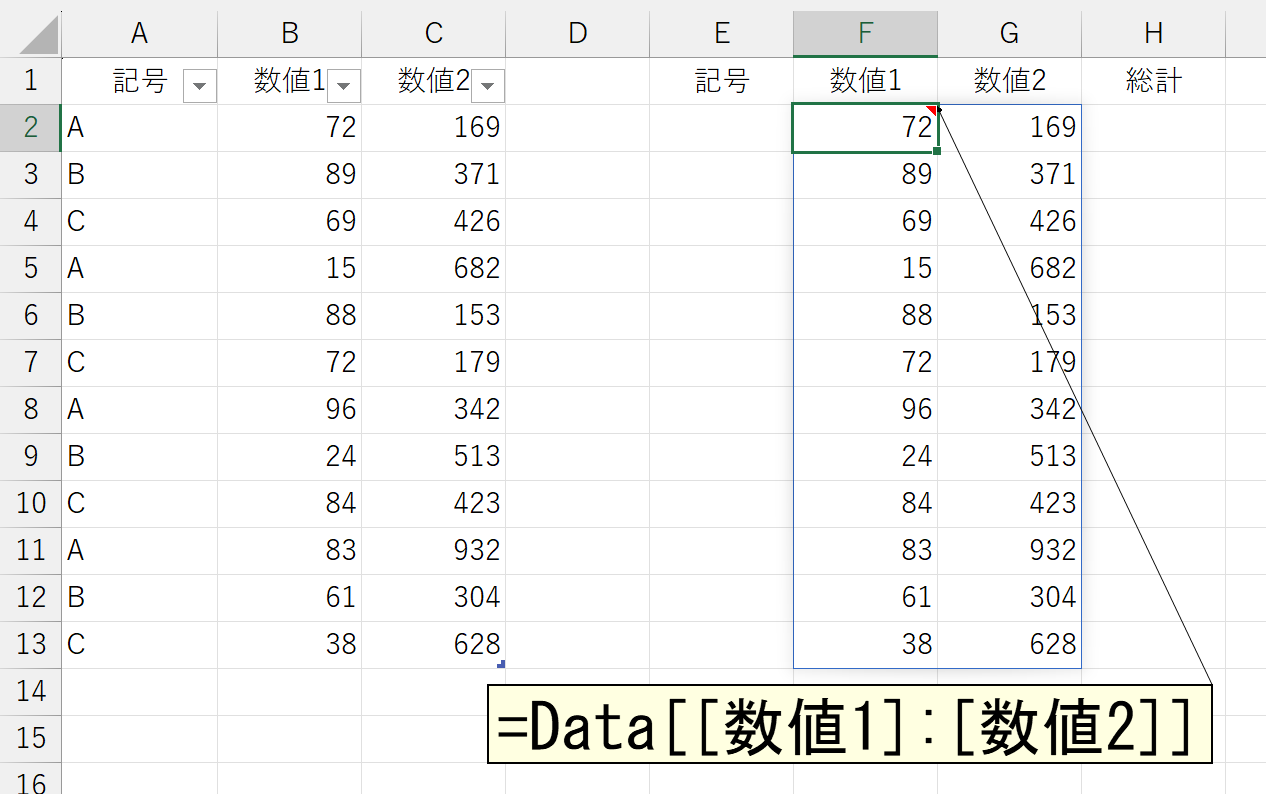
この右側に「数値1」と「数値2」を合計した結果を"配列形式"で結合します。それにはHSTACK関数を使います。
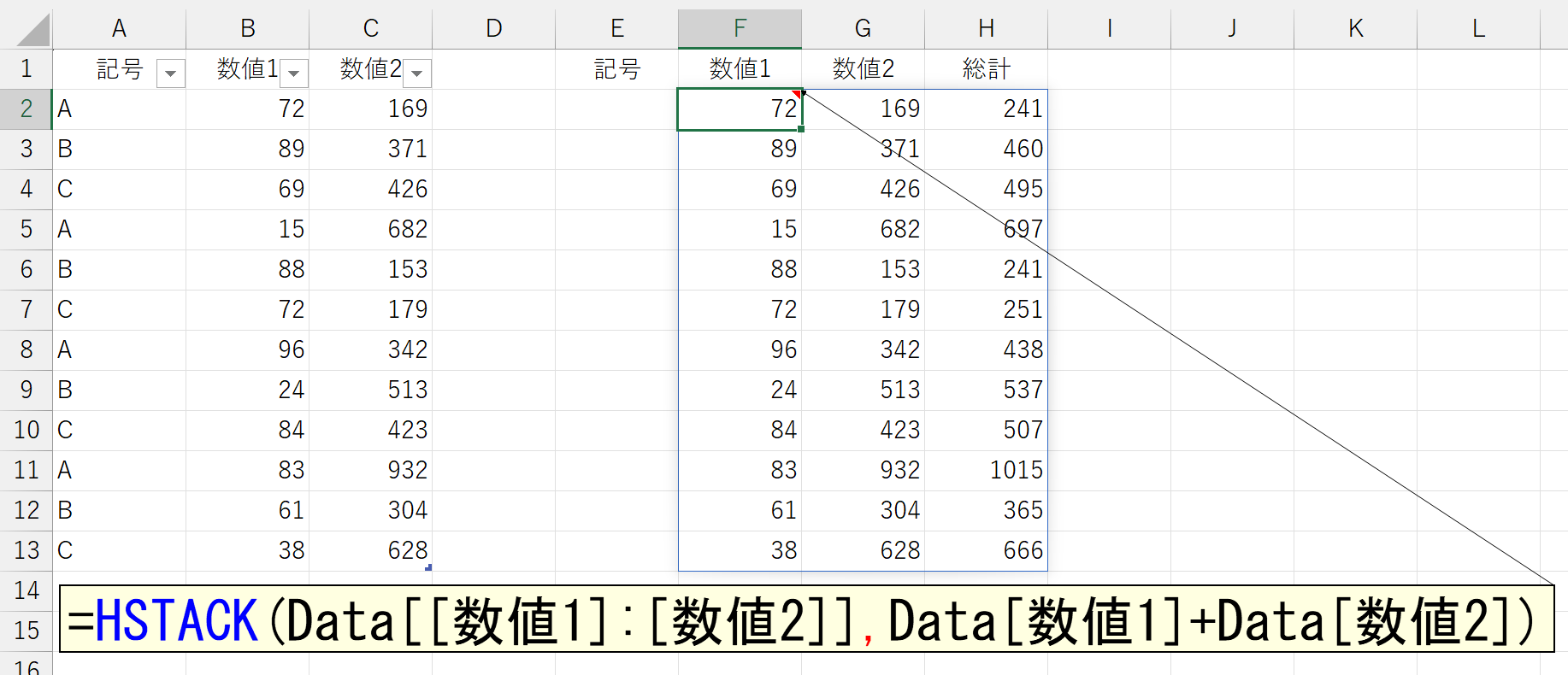
これを、引数「値」に指定します。
HSTACK関数については、下記ページを参照してください。
引数「計算方法(function)」
GROUPBY関数で計算できるのは、項目ごとの合計(SUM)だけではありません。
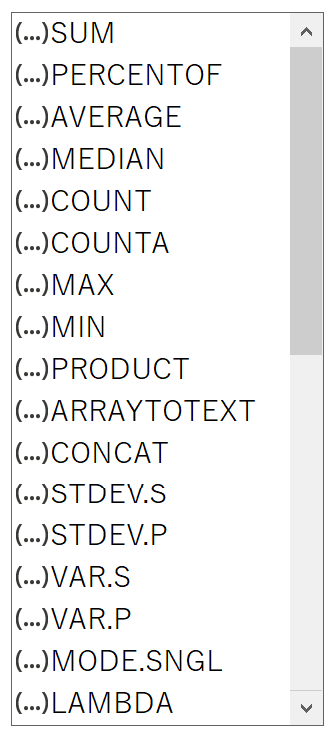
項目ごとの合計を計算するのなら、引数「計算方法」に「SUM」という文字列を指定します。SUBTOTAL関数やAGGREGATE関数のように番号で指定するのではありません。計算の詳細に関しては、それぞれ関数のヘルプなどを調べてください。上から2番目にある「PERCENTOF」は、GROUPBY関数と一緒に追加されたPERCENTOF関数です。割合(パーセント)を返します。
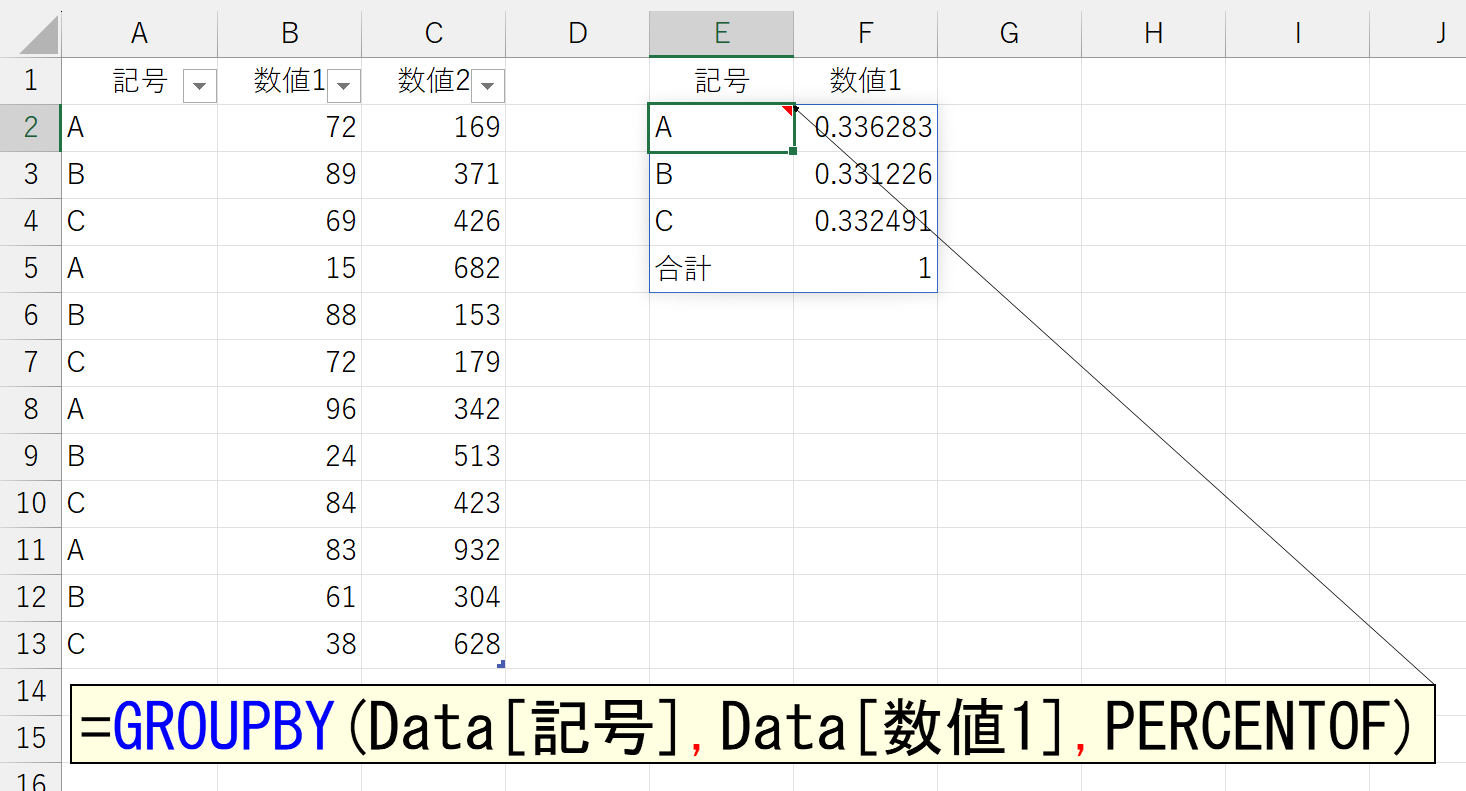
SUBTOTAL関数やAGGREGATE関数と違い、CONCAT関数やARRAYTOTEXT関数といった文字列操作もできる点が珍しいですね。CONCAT関数は指定したセル範囲や配列を、すべて結合する関数です。ここでは、ARRAYTOTEXT関数についてご紹介します。ARRAYTOTEXT関数は、2021年頃にMicrosoftがシレっと追加した関数です。私の記憶では、告知されなかったと思います。あるとき突然、関数オートコンプリートに表示されて驚きました。ちなみに、おそらく同時期にVALUETOTEXT関数、ENCODEURL関数、WEBSERVICE関数、FILTERXML関数なども追加されています。
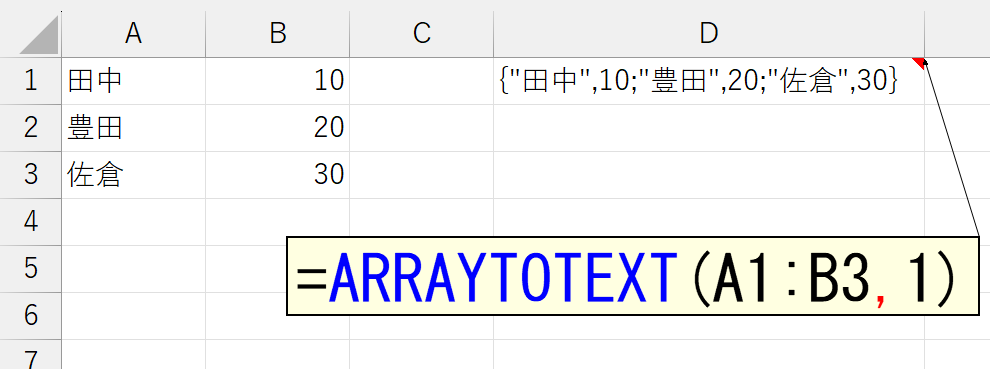
ARRAYTOTEXT関数は、その名のとおり「ARRAY(配列)をテキストに変換」する関数です。まずは、簡単なケースで動作をご覧ください。
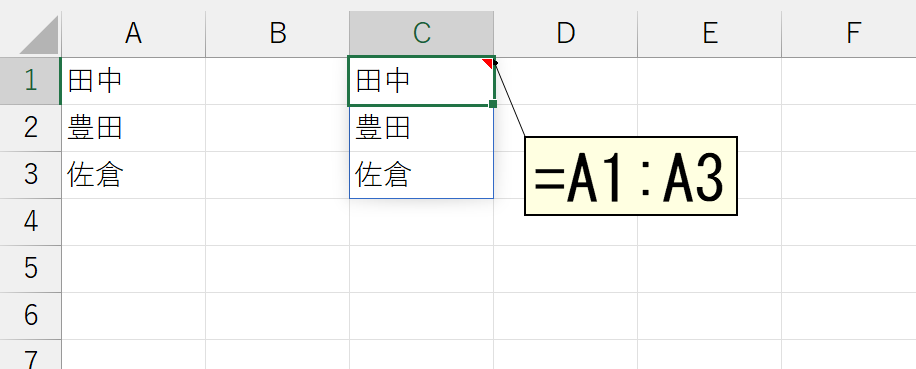
まず大前提として。上図のように、スピった結果は配列になります。上図では、セルC1に入力した「=A1:A3」という動的配列数式がスピって、「田中」「豊田」「佐倉」という3要素を持つ配列(正確には二次元配列)を返しています。こうした配列を、ひとつのテキスト(文字列)に変換するのがARRAYTOTEXT関数です。
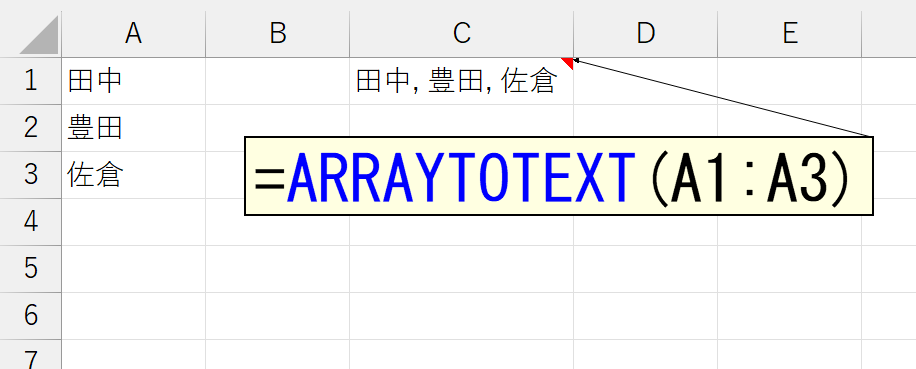
さて、ARRAYTOTEXT関数の引数は、次のとおりです。
ARRAYTOTEXT(配列,書式)
引数「書式」には、どのようなテキストを返すかを表す、0または1を指定します。なお、引数「書式」を省略すると0とみなされます。
| 数値 | 書式 |
|---|---|
| 0 | 要素がカンマ(, )で区切られた書式 |
| 1 | 配列定数の書式 |
上図では、引数「書式」を省略したので、0が指定されたものとみなされて、要素がカンマ(, )で区切られています。では、引数「書式」に1を指定してみましょう。
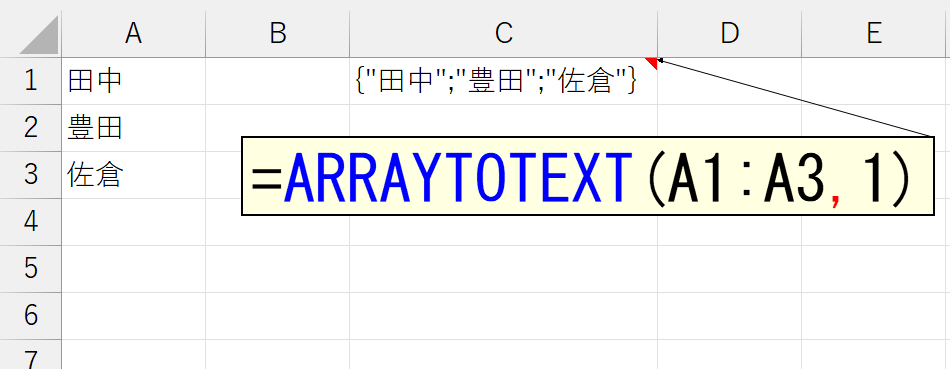
配列定数とは何かを詳しく解説すると長くなるので割愛します。簡単に言えば、プログラミングのコード内で配列を表す書き方、みたいなものです。要素がセミコロン(;)で区切られていますが、このセミコロン(;)は行(下)方向の区切りを表しています。ちなみに列(右)方向の区切りはカンマ(,)です。
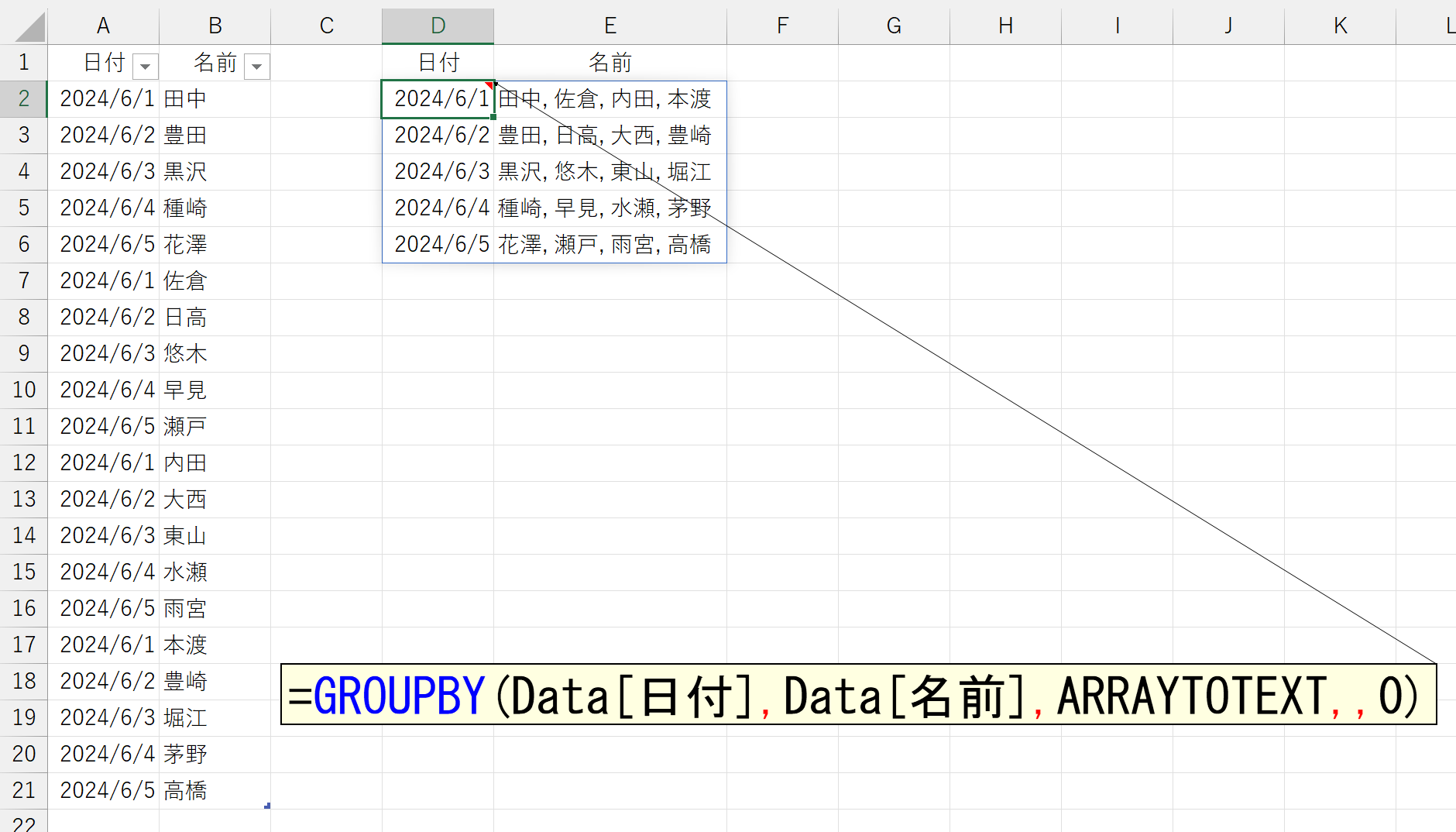
まぁ、一般的には、引数「書式」に0を指定するか省略して、要素をカンマ(, )で区切ることが多いと思います。さて、このARRAYTOTEXT関数をGROUPBY関数で指定すると、次のようなことができます。
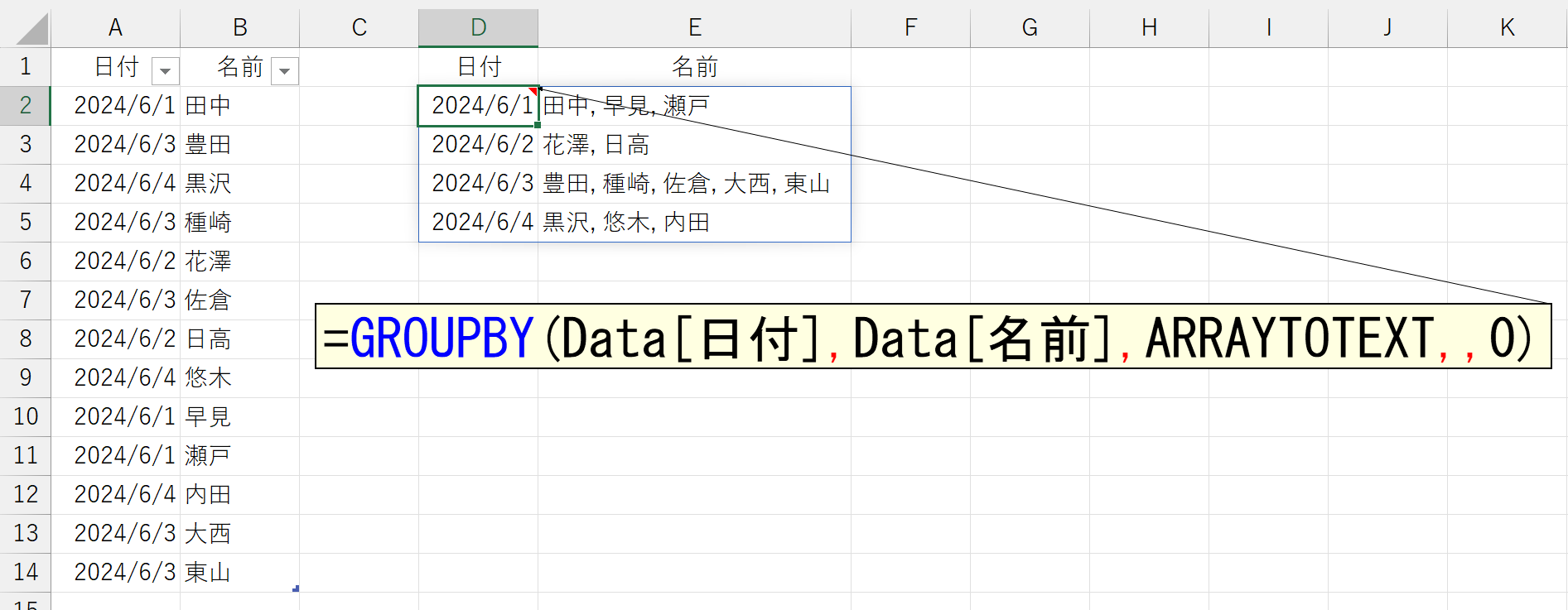
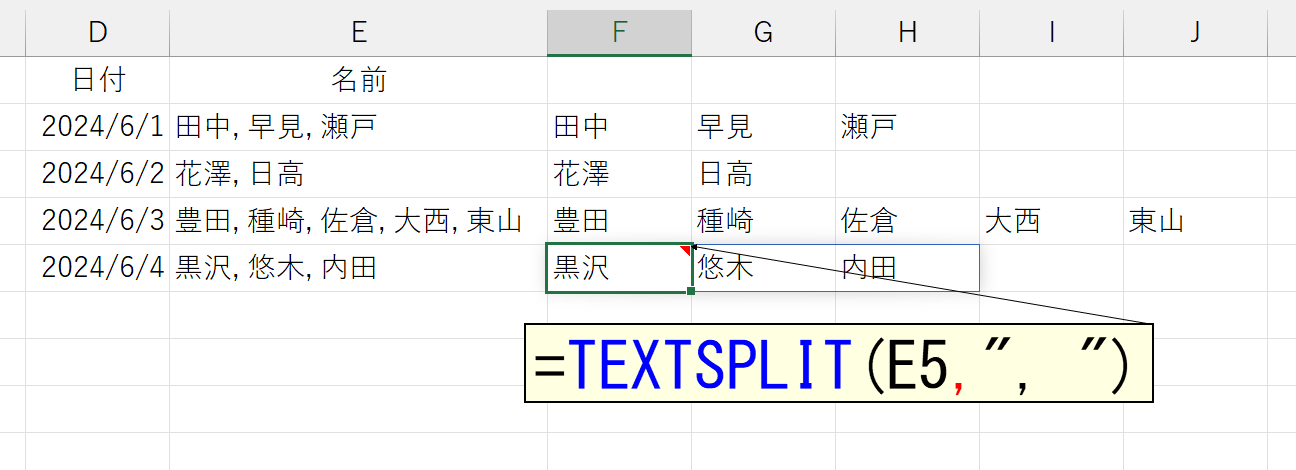
これ、人員のシフトなどを管理している人でしたら、泣いて喜んで庭駆け回る機能なのでは?ちなみに、それぞれの名前を1セルずつ抽出するのでしたら、TEXTSPLIT関数を使うと便利です。ただし、要素の区切りはカンマ(,)だけでなく、半角のスペースも含まれますので注意してください。
余談ですが、似たようなことはFILTER関数でも可能です。
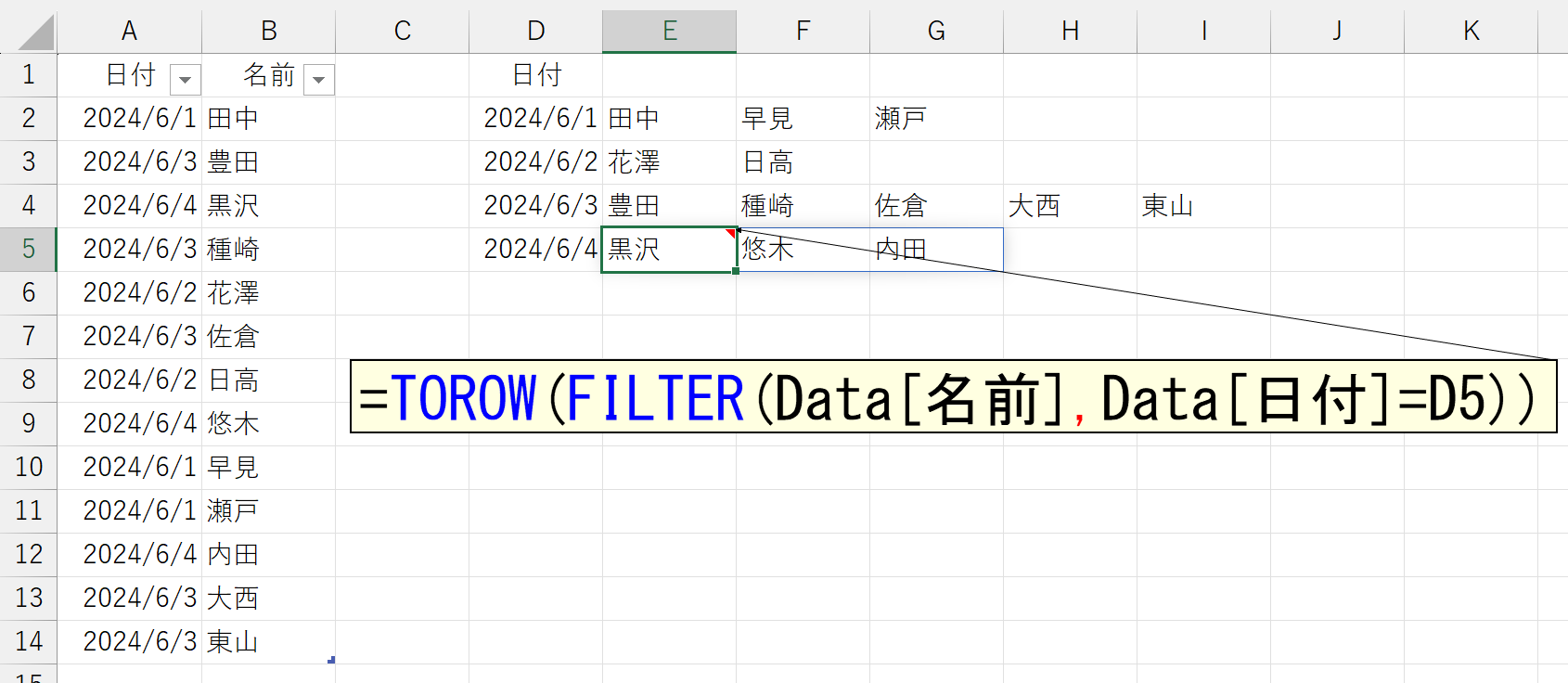
D列には日付(シリアル値)を手入力しています。どちらが良いということではなく、同じ結果を得るにしても、できるだけ多くの方法を思いつけるようにしてください。
引数「ヘッダ(field_headers)」
GROUPBY関数の中で、最も分かりにくい引数が、この「ヘッダ」です。要するに、ヘッダ(タイトル)を表示するかどうかに関するオプションなのですが、意味が分かりません。この引数では、次の選択項目がリスト表示されます。

「はい、表示しません」と「はい、表示します」って何だよw ちなみに、項目を選択すると、右側にヒントがポップアップするのですが、それを読んでも今イチ分かりません。
| 数値 | 項目 | ヒント |
|---|---|---|
| 0 | いいえ | フィールドデータにヘッダーが含まれていないので、フィールドヘッダーを結果に表示することはできません |
| 1 | はい、表示しません | フィールドデータにヘッダーが含まれていますが、結果に表示することはできません |
| 2 | 生成しない | フィールドデータにヘッダーがありませんが、フィールドヘッダーを生成して結果に表示する必要があります |
| 3 | はい、表示します | フィールドデータにヘッダーがあるため、結果に表示する必要があります |
このリスト、英語版Excelでは次のようになっています。

英語版の方が、はるかに分かりやすいですね。日本語版では、「いいえ」が1つ、「はい」が2つ、「どちらでもない(生成しない)」が1つ、となっていますが、英語版では「No」が2つ、「Yes」が2つとシンプルです。このYes/Noとは、引数として指定したセル範囲内に、ヘッダ(タイトル)が含まれている(Yes)か、含まれていない(No)かを表しています。つまり「含まれていますか?」という質問に対する答えです。


「1」は「はい、範囲にヘッダ(タイトル)が含まれています。しかし、集計結果には表示しません」という意味です。
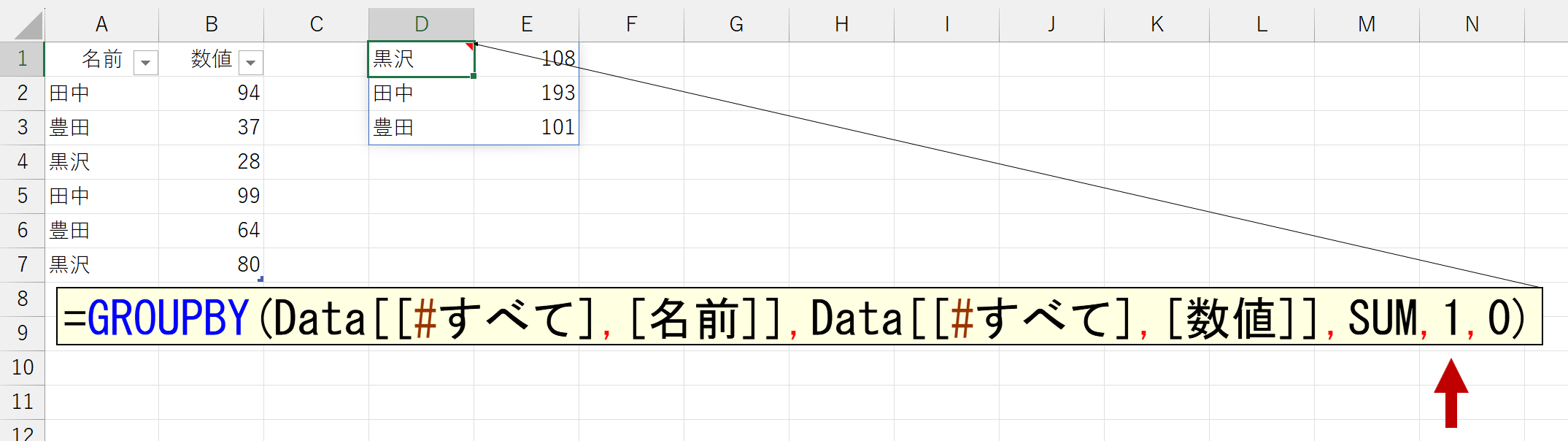
「3」は「はい、範囲にヘッダ(タイトル)が含まれています。だから、集計結果に表示します」です。
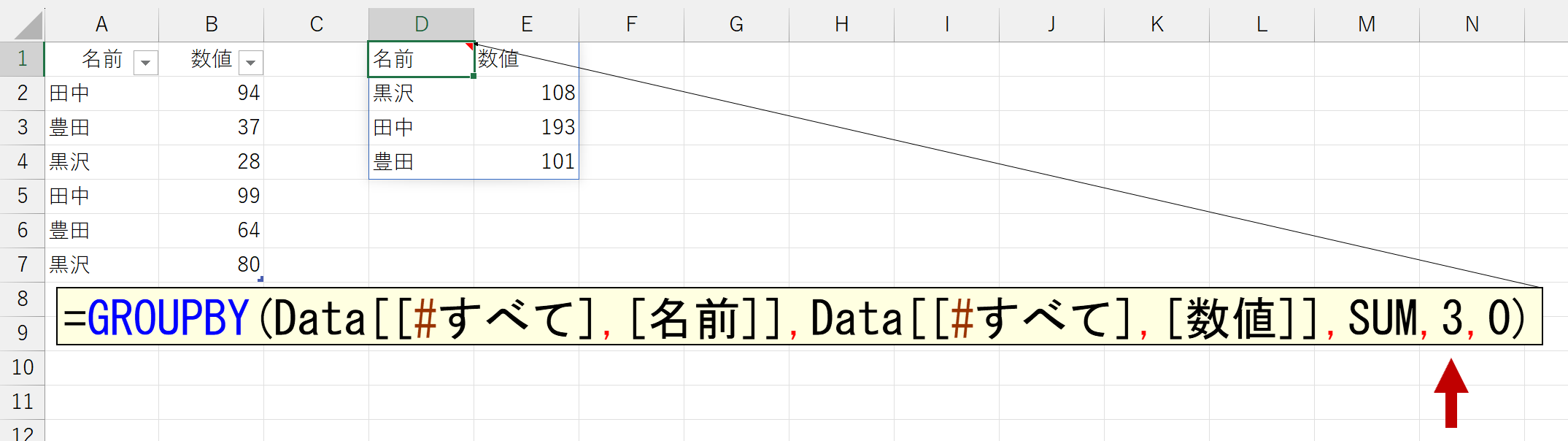
「0」は「いいえ、範囲にヘッダ(タイトル)は含まれていません。(だから、集計結果に表示できません)」となりますね。
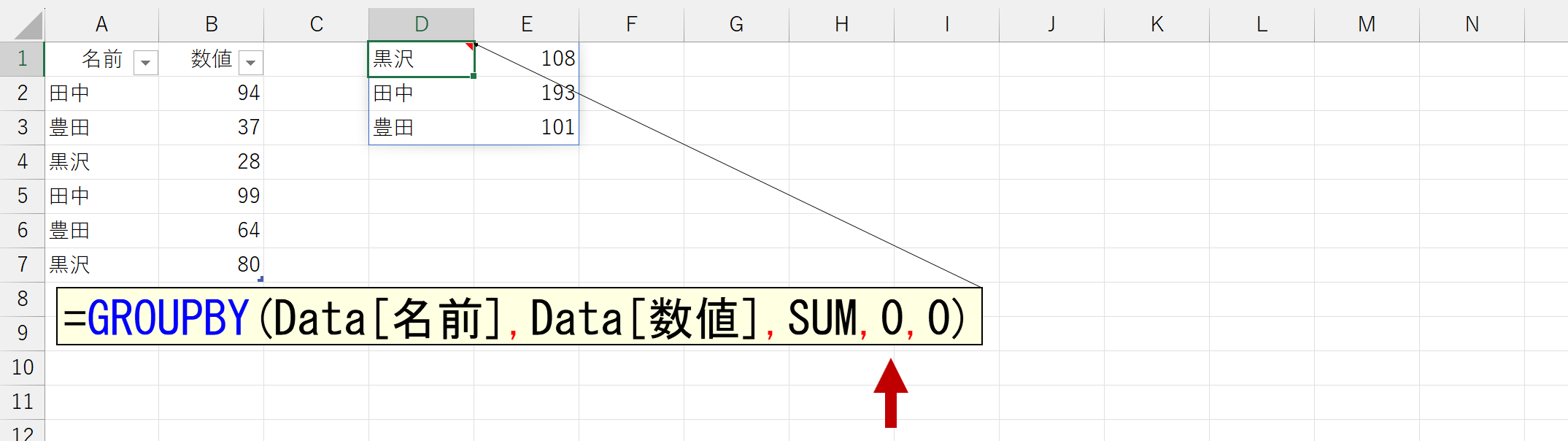
問題は「2」です。これ、英語版を見ると「いいえ、範囲にヘッダ(タイトル)は含まれていません。しかし、(便宜的なヘッダ(タイトル)を)生成します」だと分かります。
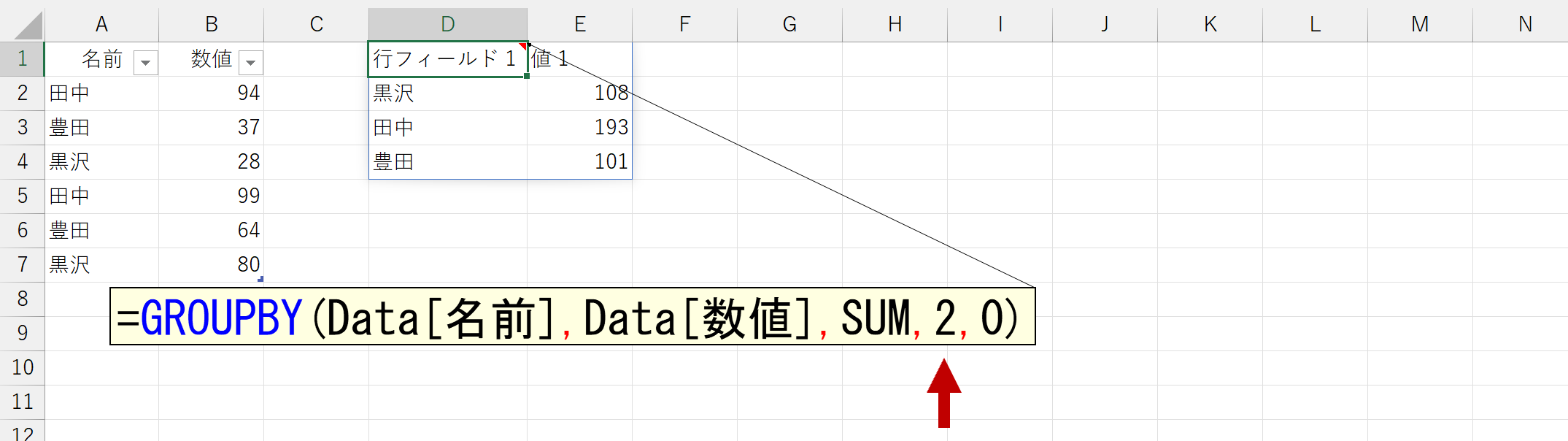
日本語版の「2 - 生成しません」は、明かな誤訳です。反対の意味になっちゃってます。この誤訳が、引数の意味を分かりにくくしている諸悪の根源です。てか、反対の意味を示しているのですから、日本国民を混乱の渦に陥れようとしているかのようです。早急に修正してくれないと、国際問題に発展するかもしれません(知らんけど)。まとめると、こういうことですね。
| 数値 | 項目 | ヒント |
|---|---|---|
| 0 | いいえ、表示できません | フィールドデータにヘッダーが含まれていないので、フィールドヘッダーを結果に表示することはできません |
| 1 | はい、表示しません | フィールドデータにヘッダーが含まれていますが、結果に表示 |
| 2 | いいえ、生成します |
フィールドデータにヘッダーがありませんが、フィールドヘッダーを生成して結果に表示 |
| 3 | はい、表示します | フィールドデータにヘッダーがあるため、結果に表示 |
「する必要がある」なんて言葉、どっから持ってきたんですかね。誰の目線で言っているのか、主格がグチャグチャです。さらに話をややこしくしているのは、この引数を省略すると、上記「0~3」のいずれでもなく、ヘッダ(タイトル)が含まれているかどうかを自動的に判定するそうです。ここまでくると、もうね、面倒くさくて検証する気もおきません。一応「先頭行がテキスト(文字列)で、次の行が数値などの場合、先頭行をヘッダ(タイトル)とみなす」らしいです。私の経験では、キレイな(ちゃんとした)リストに対して、ヘッダ(タイトル)を含めずに指定すると、引数「ヘッダ」を省略しても、たいていはうまくいくようです。
引数「総計(total_depth)」
集計結果の中に、「小計」や「合計」を表示するかどうかを決める引数です。数値の値を足し算した結果が「合計」と表示されるので、区別する意味で引数名は「総計」としました。深い意味はありません。まぁ、何でもいいです。
指定できるのは次のとおりです。

ありゃ、こっちには「総計」って表示されるのか。もう、いいや。適当に脳内変換して理解してください。動作は分かりやすいです。
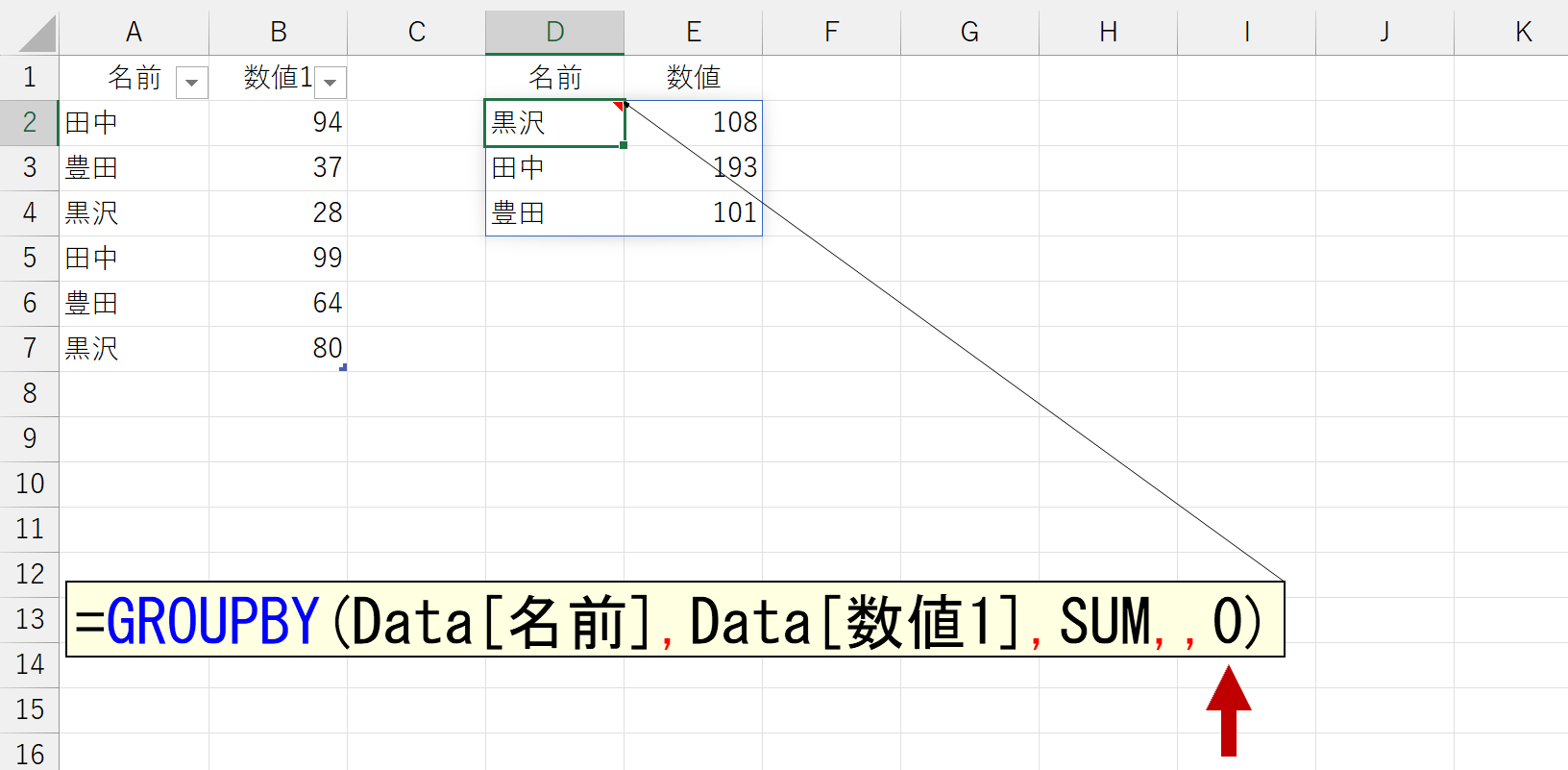
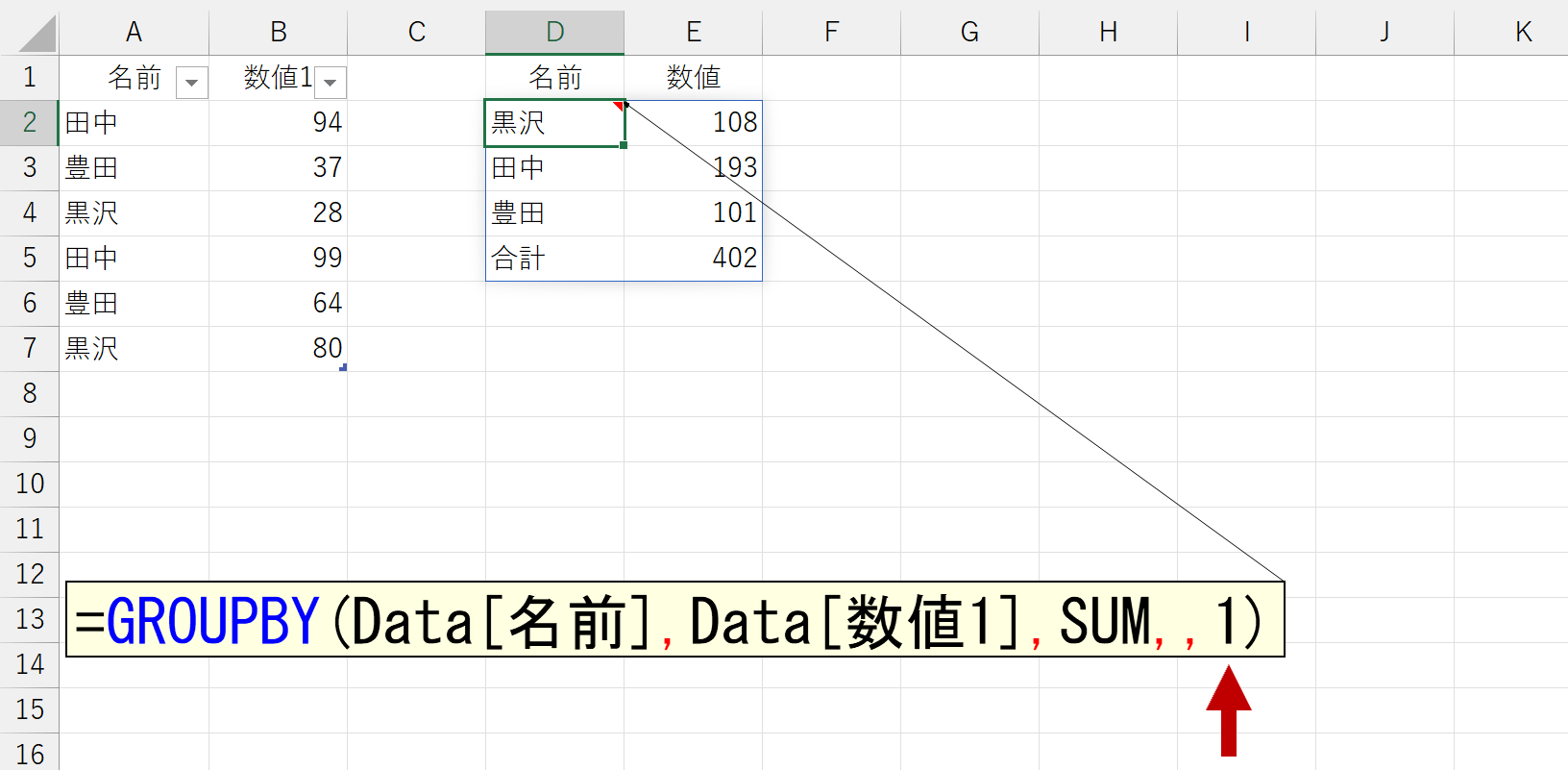
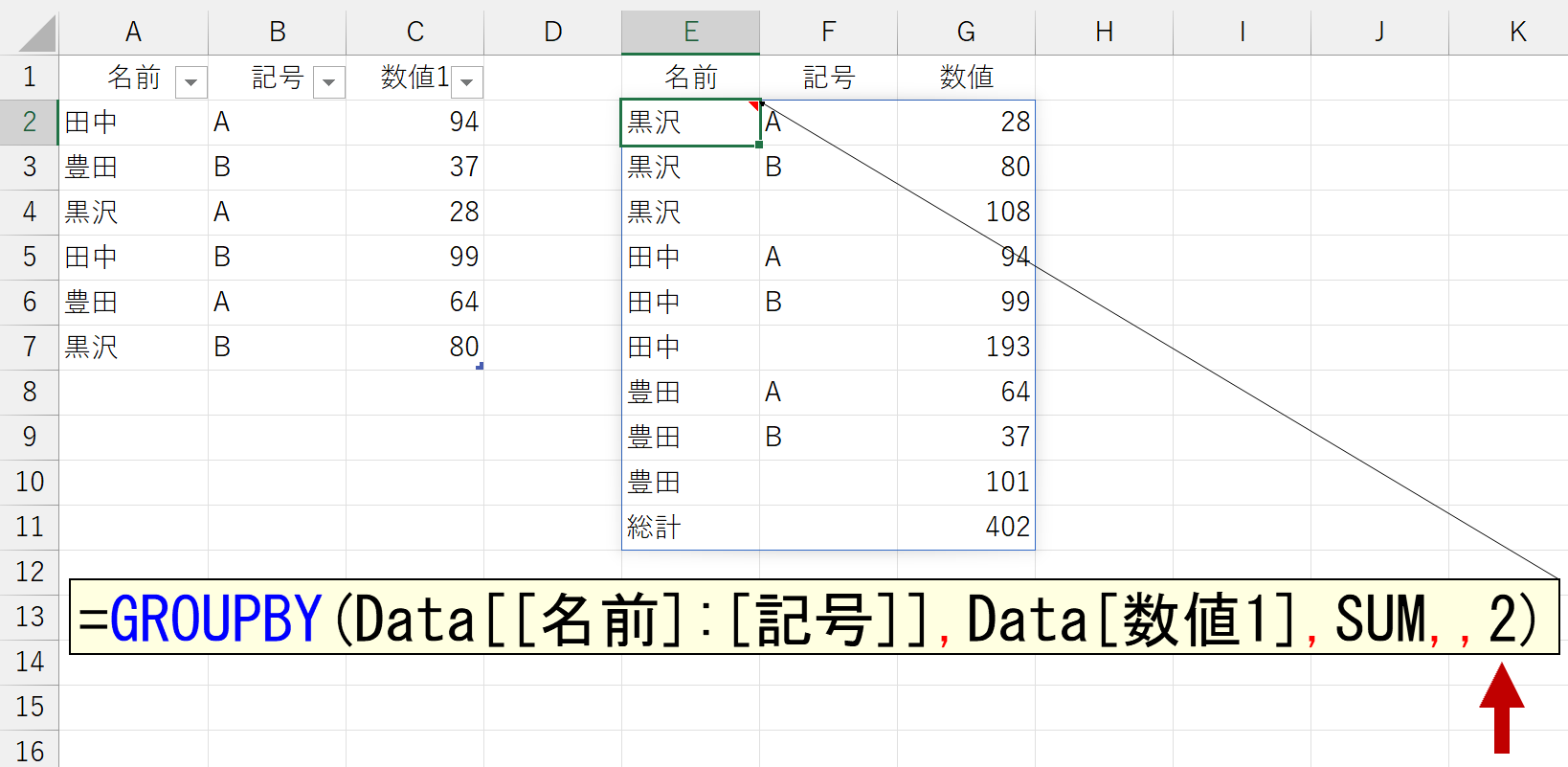
「小計」は、引数「行データ」に複数の項目を指定したときに表示されます。引数「行データ」に1つの項目しか指定していないとエラーになります。
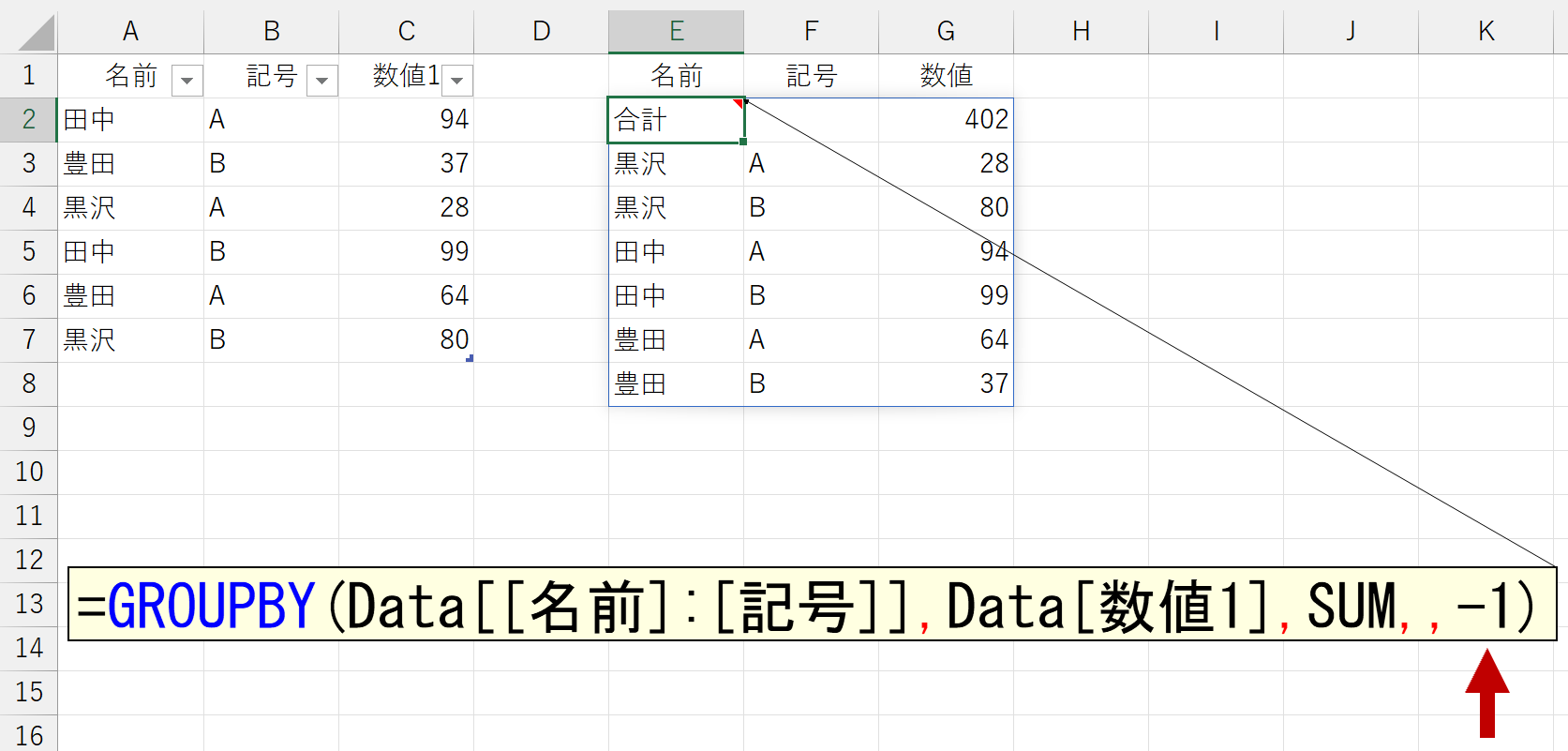
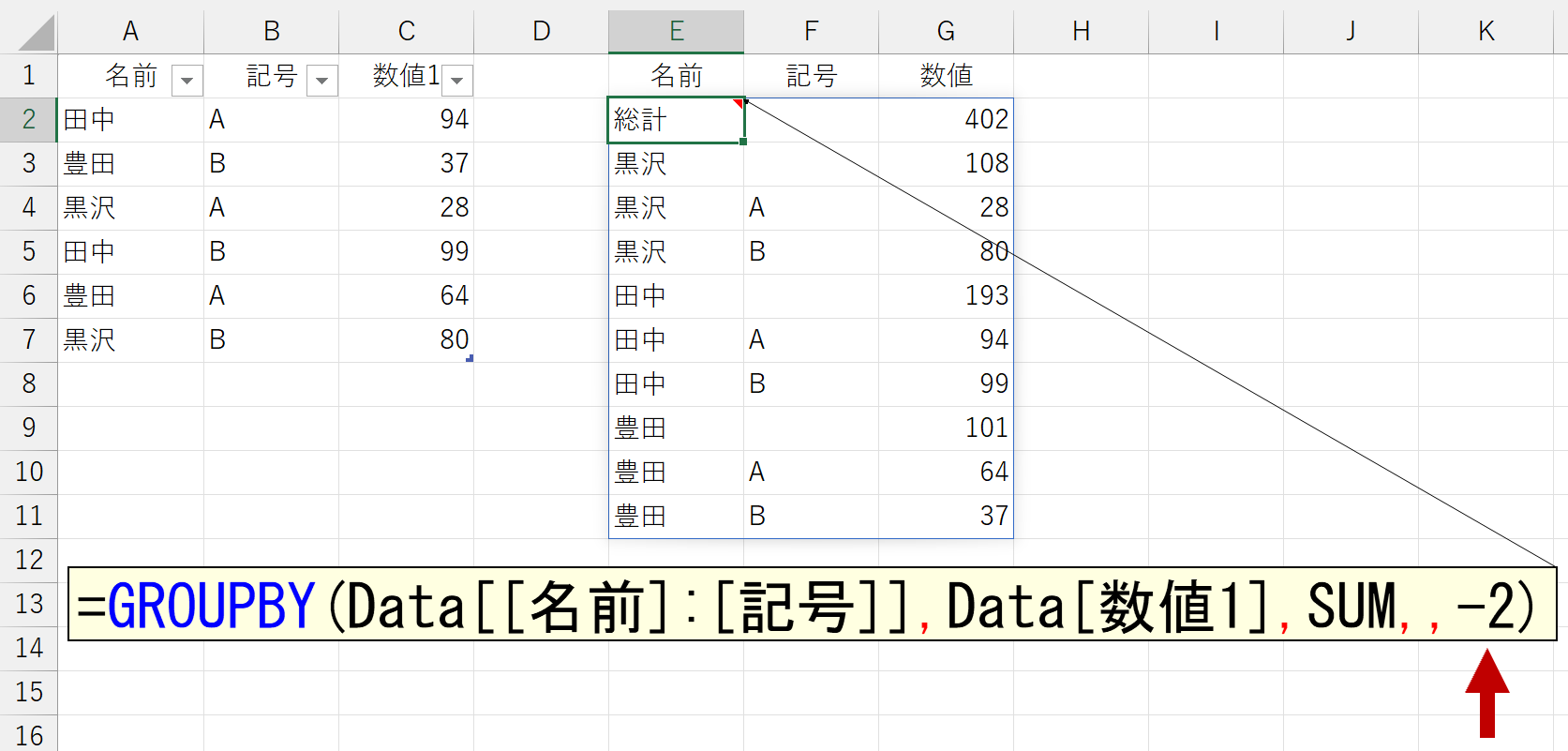
引数「総計」を省略すると「1」を指定したとみなされます。お好みでどうぞ。
引数「並べ替え(sort_order)」
この引数も分かりにくいです。まずは、簡単なケースで確認してみましょう。
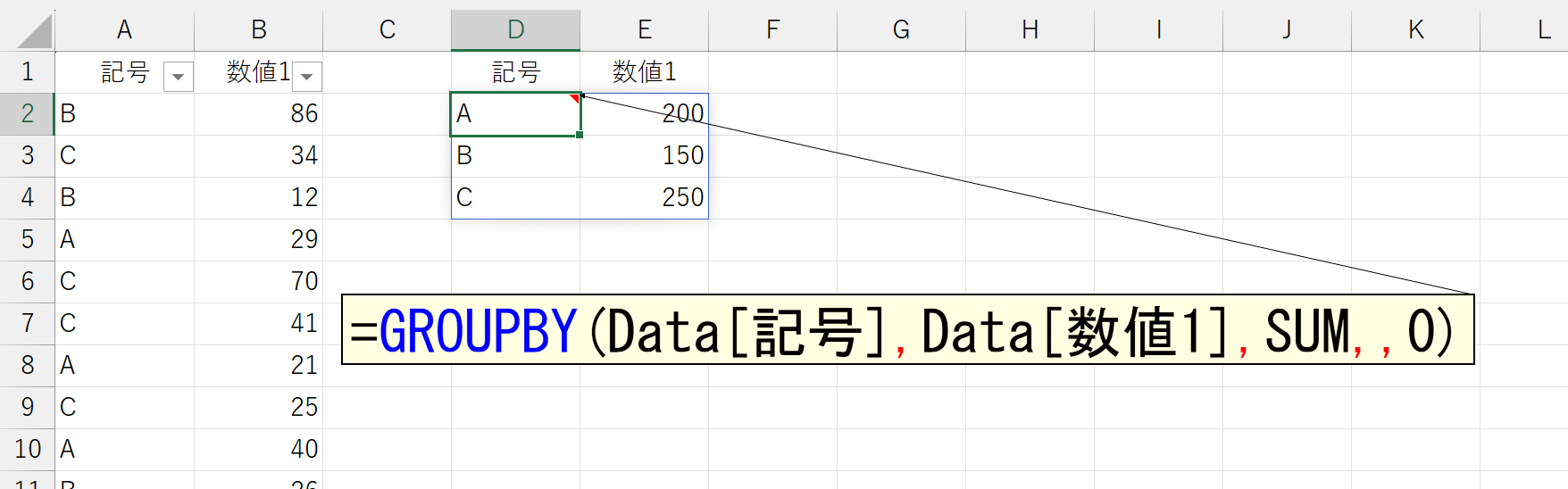
引数「並べ替え」には、並べ替える位置を表す数値を指定します。左端列が「1」です。また、この列位置を表す数値をプラスで指定すると"昇順"で並べ替わり、マイナス(-1など)で指定すると"降順"で並べ替えます。上図は引数「並べ替え」を省略したので、1列目を"昇順"で並べ替えています。
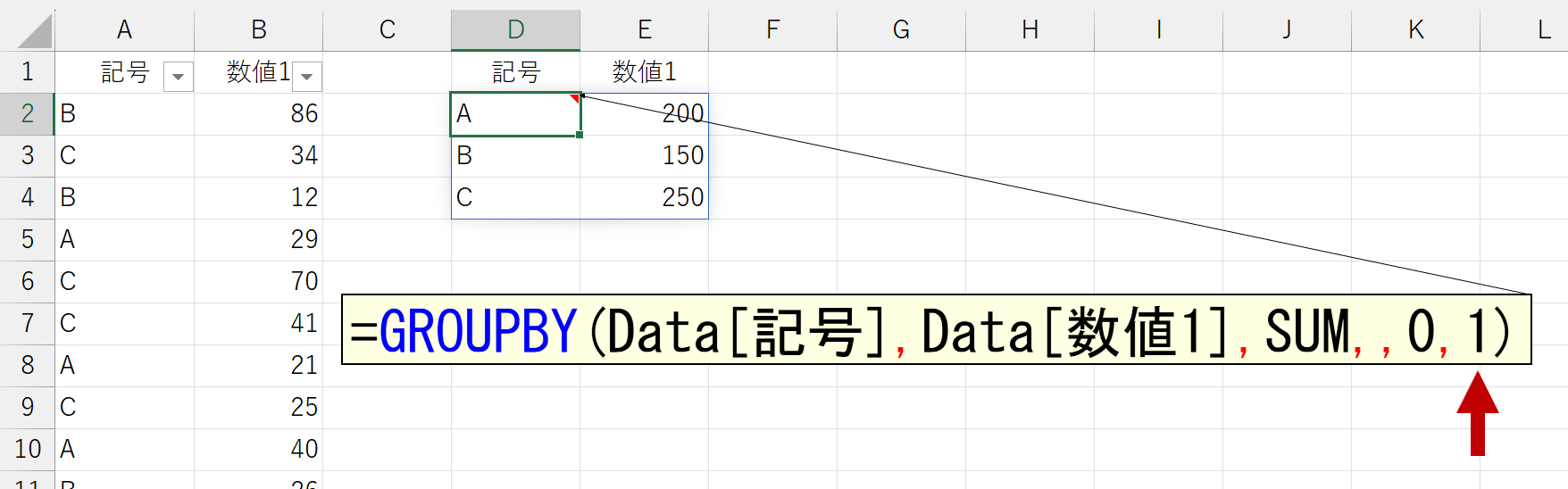
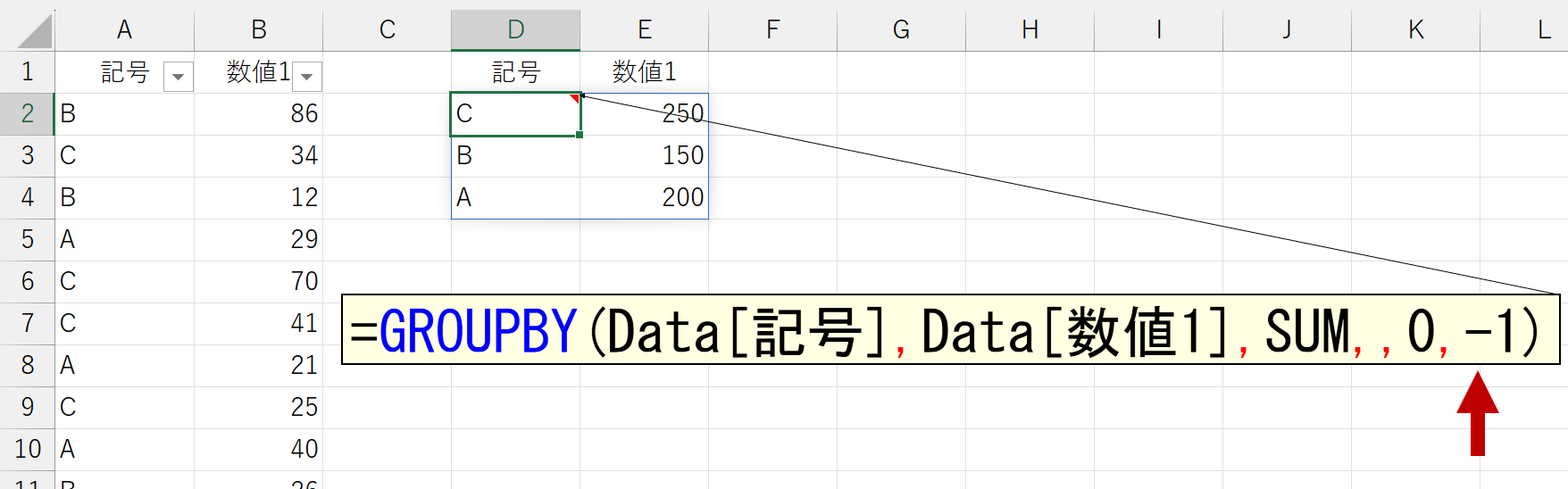
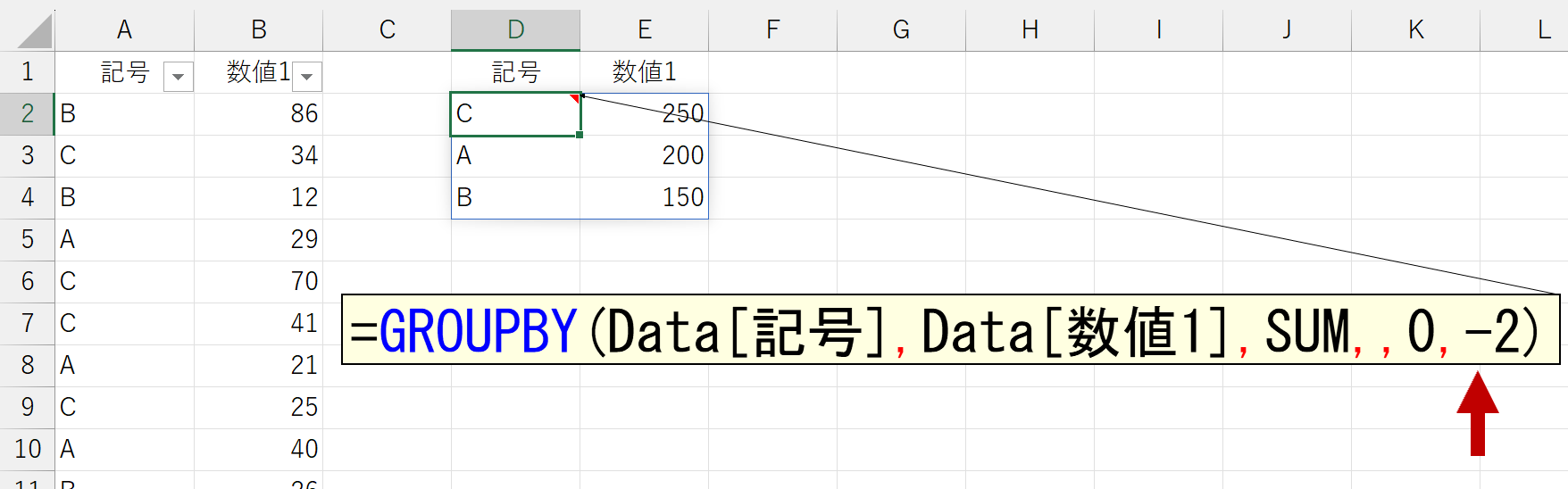
これだけならシンプルなのですが、引数「行データ」に複数列(複数項目)を指定すると悩みます。
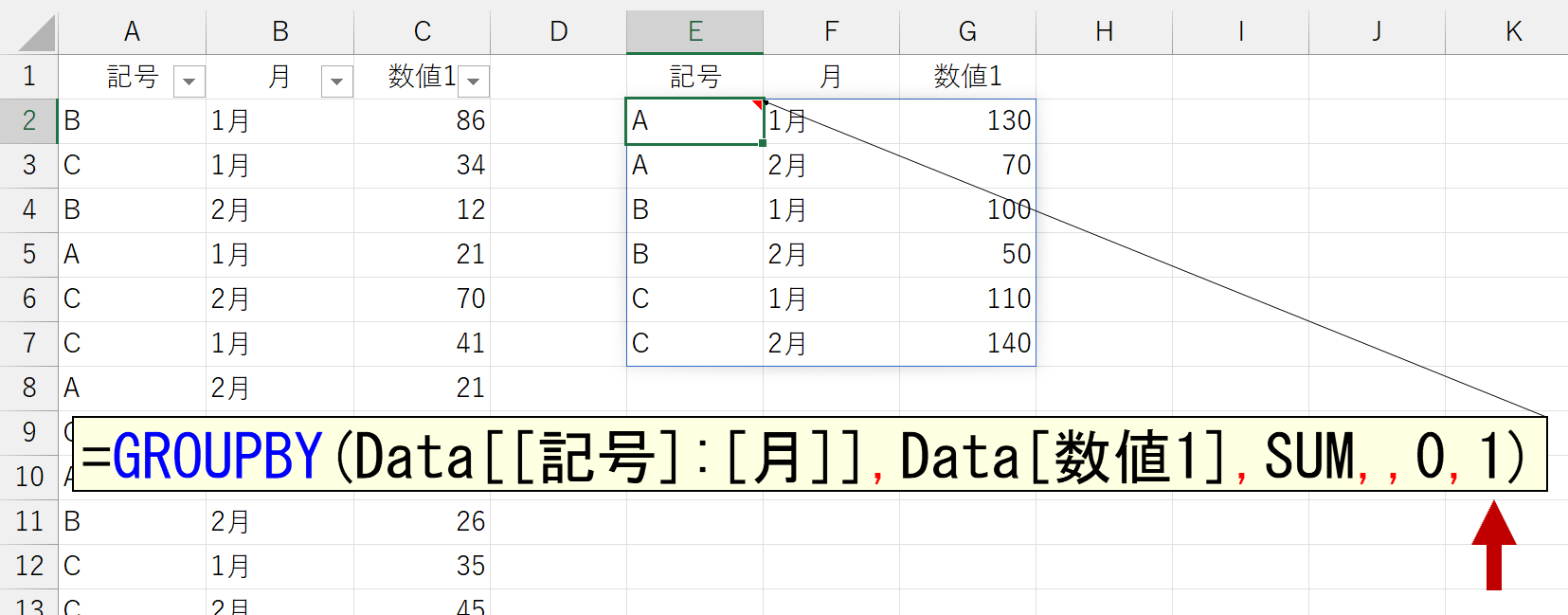
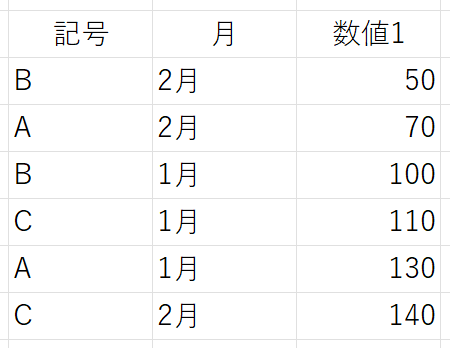
列「月」には、文字列で「1月」と「2月」を入力しています。上図は、1列目を"昇順"で並べ替えています。ちなみに、引数「並べ替え」を省略すると、この状態になります。さて、では2列目の「月」を"昇順"で並べ替えてみましょう。望む結果は下図のとおりです。
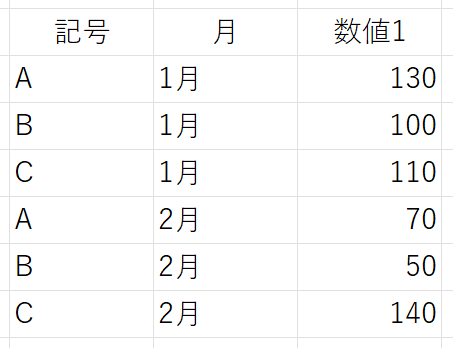
ところが、GROUPBY関数の実行結果はこうなります。
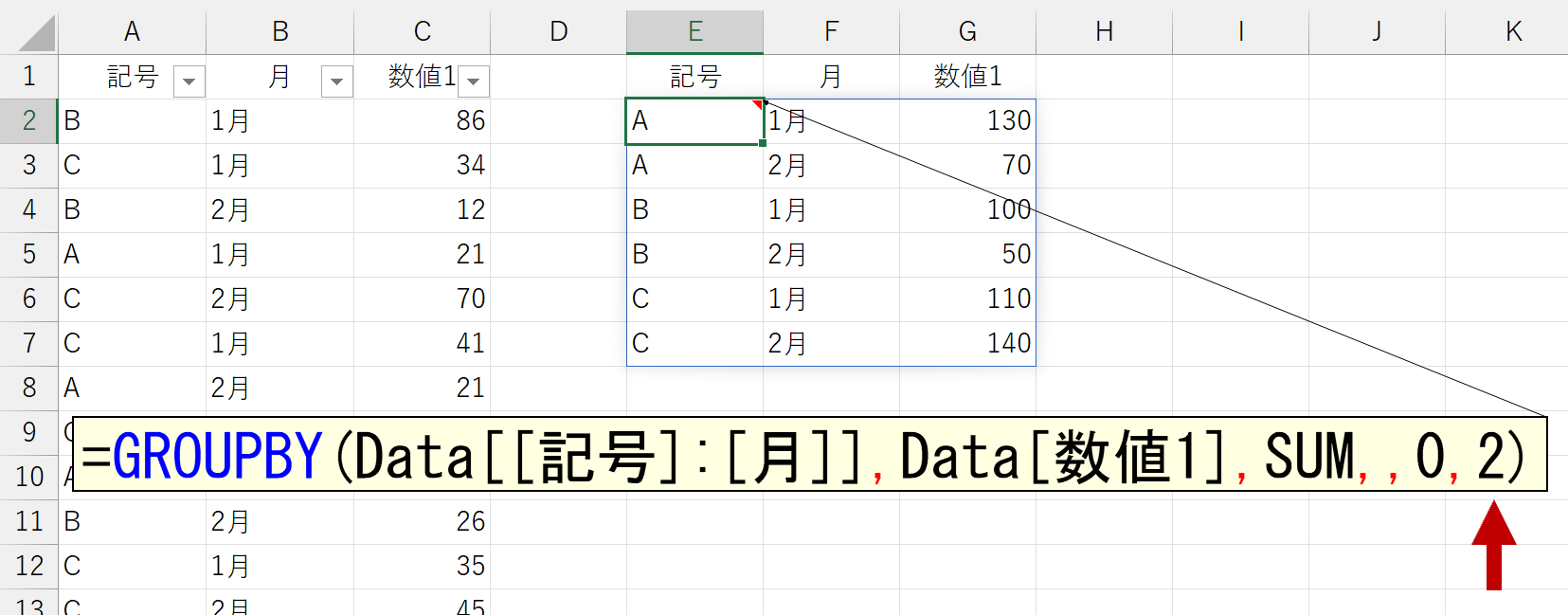
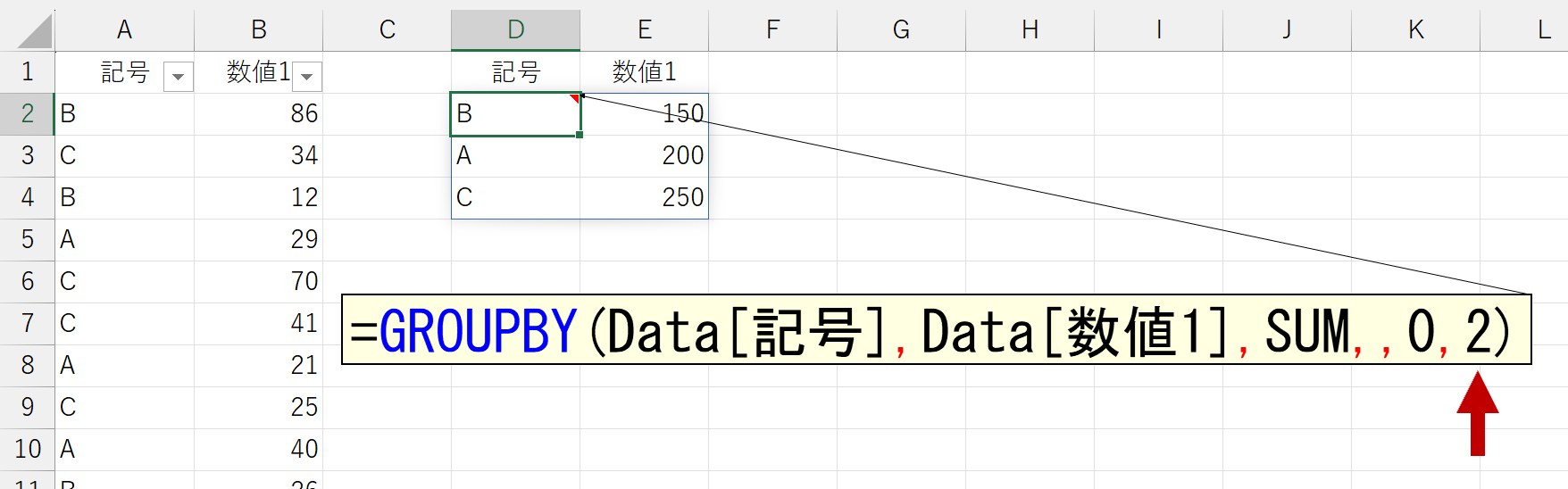
あれれ~おかしいぞぉ~。2列目で並べ替えられてない。じゃ、3列目を指定してみましょう。
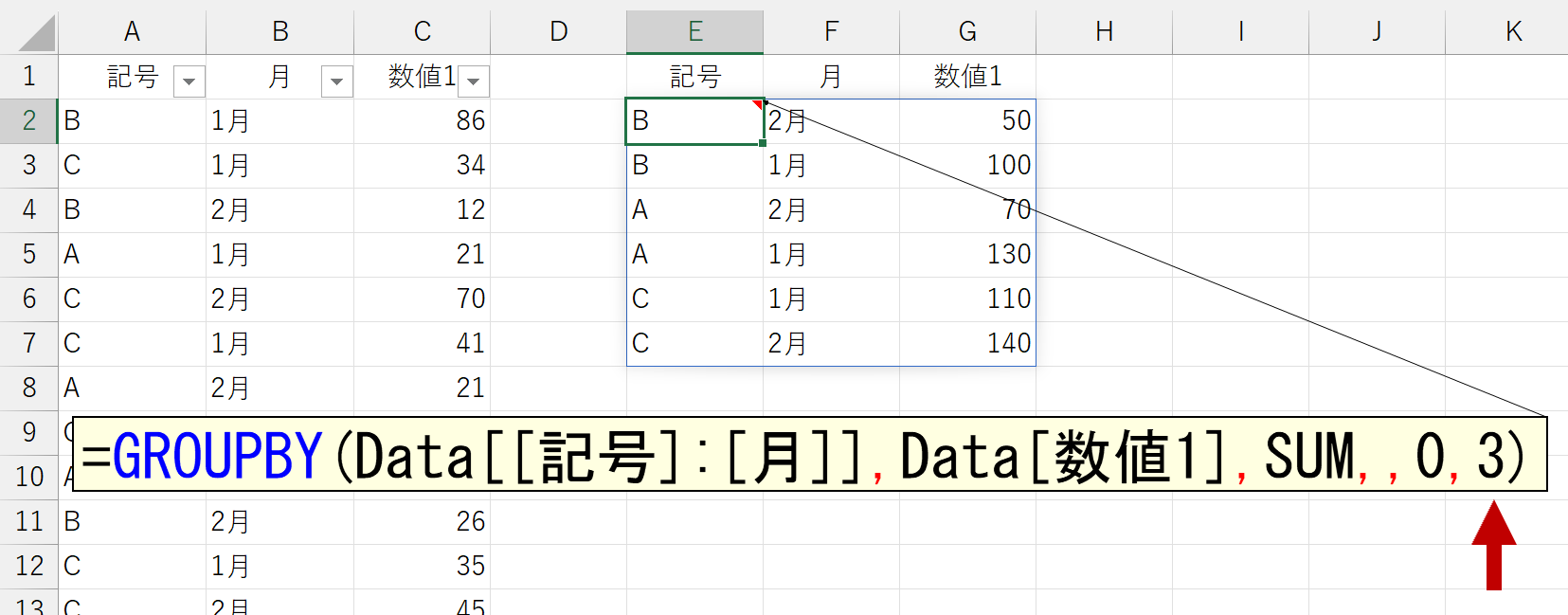
こちらも、下図のような結果をイメージしたのですが。
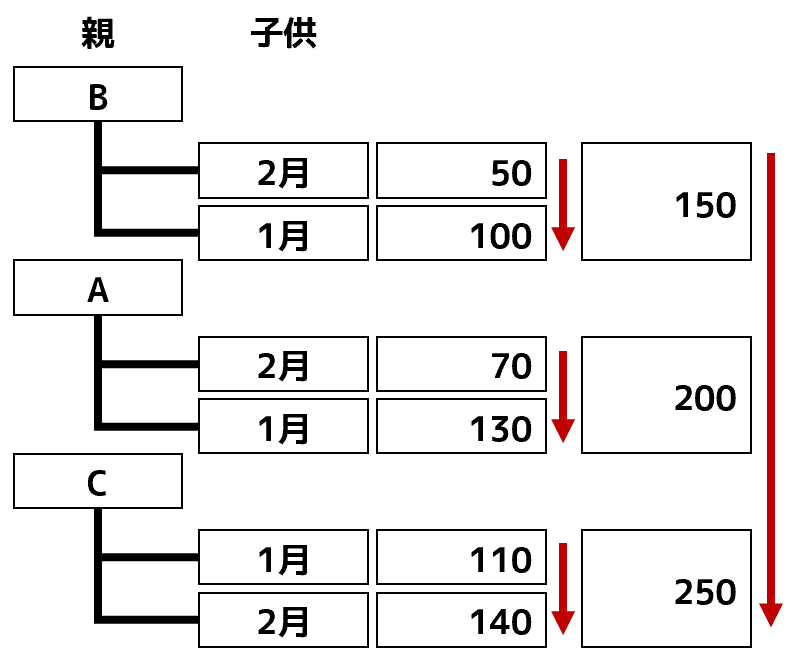
これ、原因は「記号」と「月」の関係性にあります。
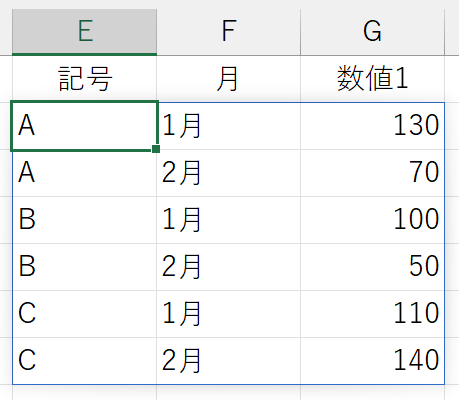
上図の集計結果って、「A」や「B」など記号の下に「1月」や「2月」が仕分けられています。いわば「記号」が"親"で、「月」が"子供"です。次のようなイメージでしょうか。
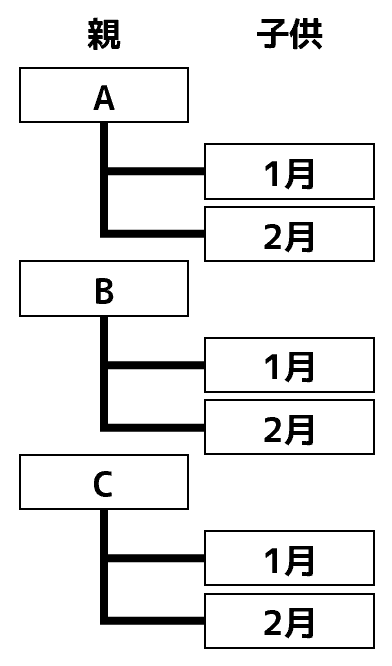
こういう関係性があるとき、"子供"を基準に並べ替えを行うと、"親"が分割されてしまいます。それはいかんと。並べ替えた後でも、"親"は常にひとかたまりにしたいと。そういう仕様なのでしょう。3列目を"昇順"で並べ替えたときも同じです。この結果は、次のようにイメージすると納得できます。
ということで、引数「並べ替え」に関しては、そういう仕様なのですが。それでも、何とか下図みたいに並べ替えることはできないのでしょうか。
これを実現するのが、最後の引数「リレーション(field_relationship)」です。
最後の引数「リレーション(field_relationship)」は、GROUPBY関数がInsider(ベータ版)に初登場したときには存在しませんでした。その後、多くの意見などを反映し、仕様の変更などを検討した結果、製品版にて追加された引数なのでしょう。だからでしょうか、Microsoftの公式ヘルプには、この引数「リレーション(field_relationship)」に関する解説がありません。この引数には、次の項目を指定できます。

| 数値 | 項目 | ヒント |
|---|---|---|
| 0 | 階層(既定) | フィールドは階層の一部です。小計が表示される場合があります。 |
| 1 | テーブル | フィールドは階層の一部ではありません。小計を表示できません。 |
field_relationship(フィールドの関係性)という名称と、ヒントから察するに、おそらく前述の"親子関係"を無効にする設定でしょう。試しに「1 - テーブル」を指定してみます。
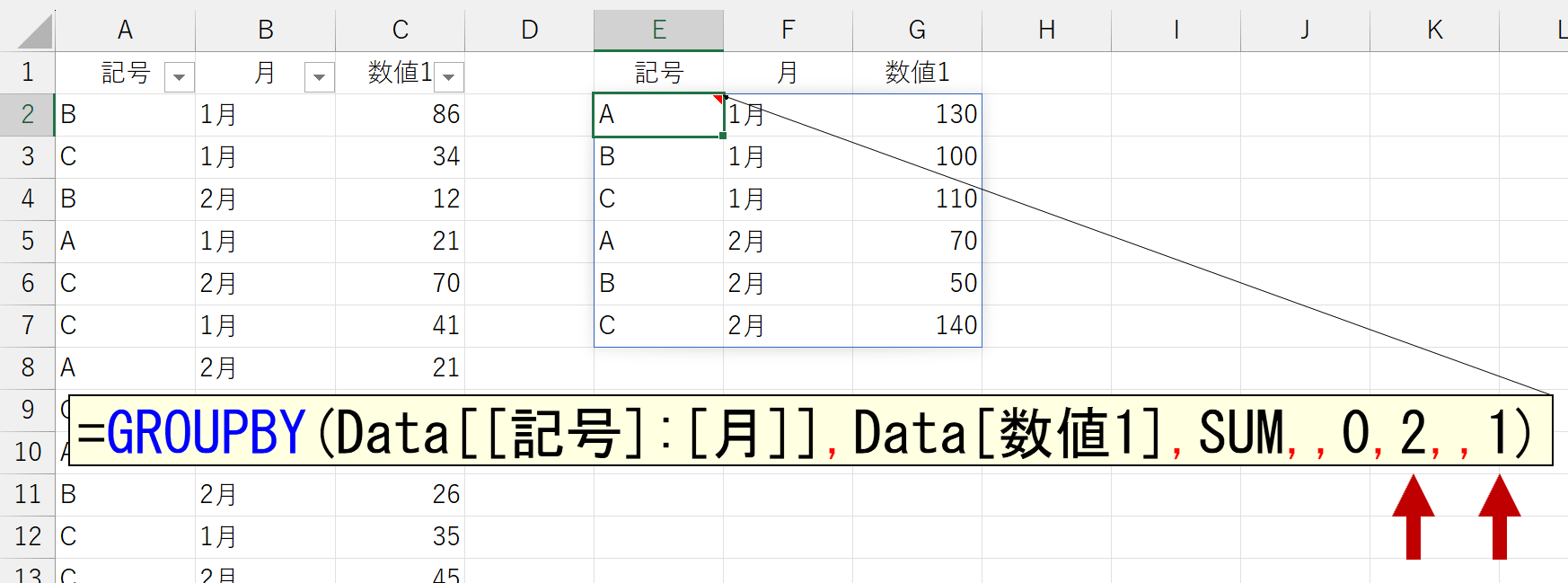
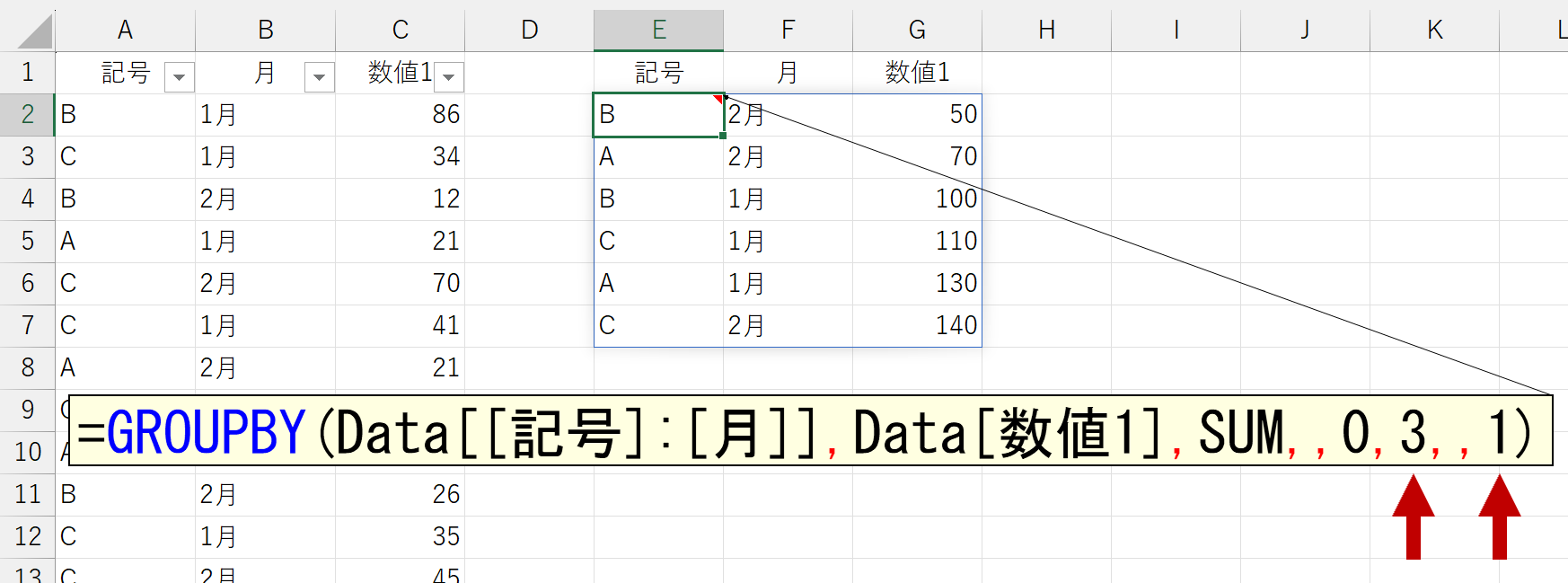
ヒントにも記載されているように、この設定は小計の自動作成にも影響があるようです。
さて、上記の引数「行データ(row_fields)」でも紹介したケースですが。
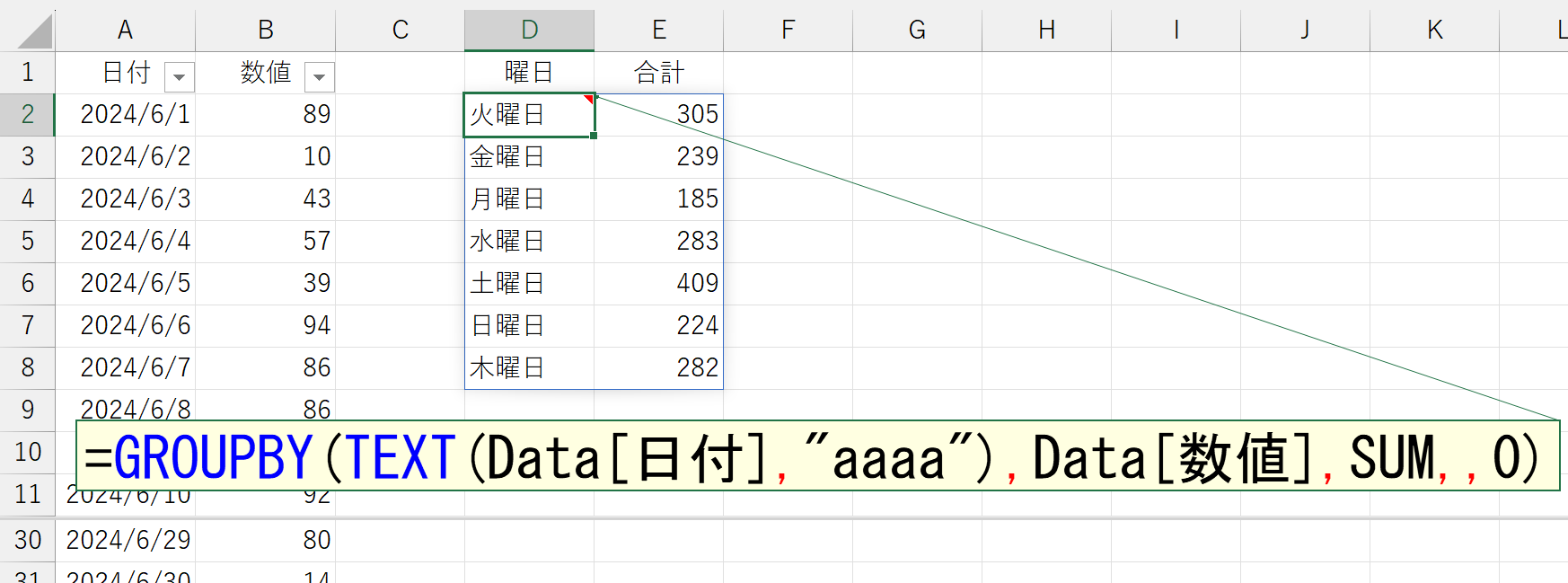
これを「月曜日」→「火曜日」→「水曜日」…の順番で並べてみましょう。それほど難しくはありません。まずは大前提として。漢字データを並べ替えるとき、フリガナは考慮されないということです。Excelの一般機能である「並べ替え」は、並べ替えるデータが漢字だったとき、標準ではフリガナ(漢字に変換する前の読み)を元に並べ替えを行っています。しかし、それは一般機能の「並べ替え」に限った仕組みです。SORT関数や、今回のような並べ替え機能では、フリガナが一切無視されます。したがって、確実な並べ替えを行うには「1・2・3…」や「A・B・C…」など、英数字によるデータが必要です。そして、もうひとつの大前提。特に何も指定しなければ、引数「行データ」に指定した左端列(つまり最上位の項目)が"昇順"で並べられます。以上のことから、もし元データが下図のようになっていたら、「月曜日」→「火曜日」→「水曜日」…の順番で並べ替えられるわけです。
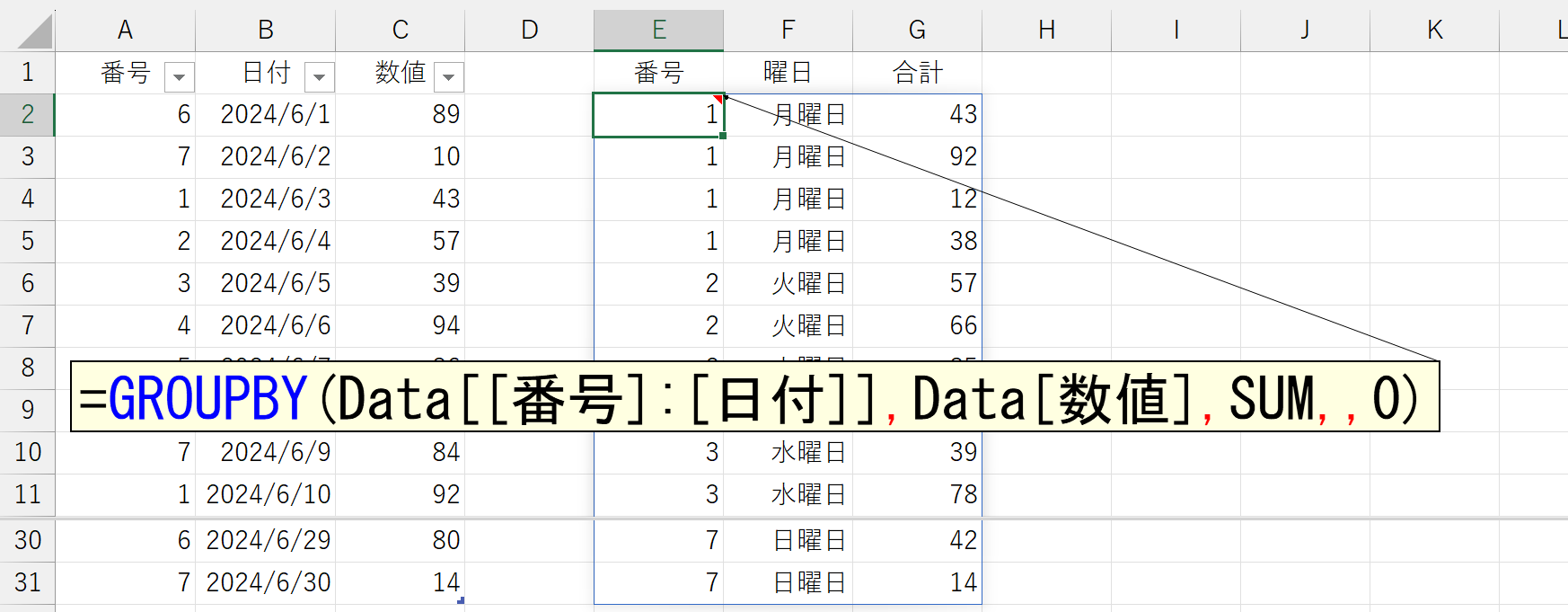
上図の「番号」とは、各曜日に対応する数値です。月曜日が1、火曜日が2、水曜日が3…としています。こうした演算を行うのがWEEKDAY関数です。もし、ご存じない方はヘルプなどで調べてください。もちろん、このWEEKDAY関数をあらかじめA列などに仕込んでおく…という不毛なことはしません。引数「値(values)」でも解説したように、計算によって得られた結果(配列)をHSTACK関数で結合すればいいです。
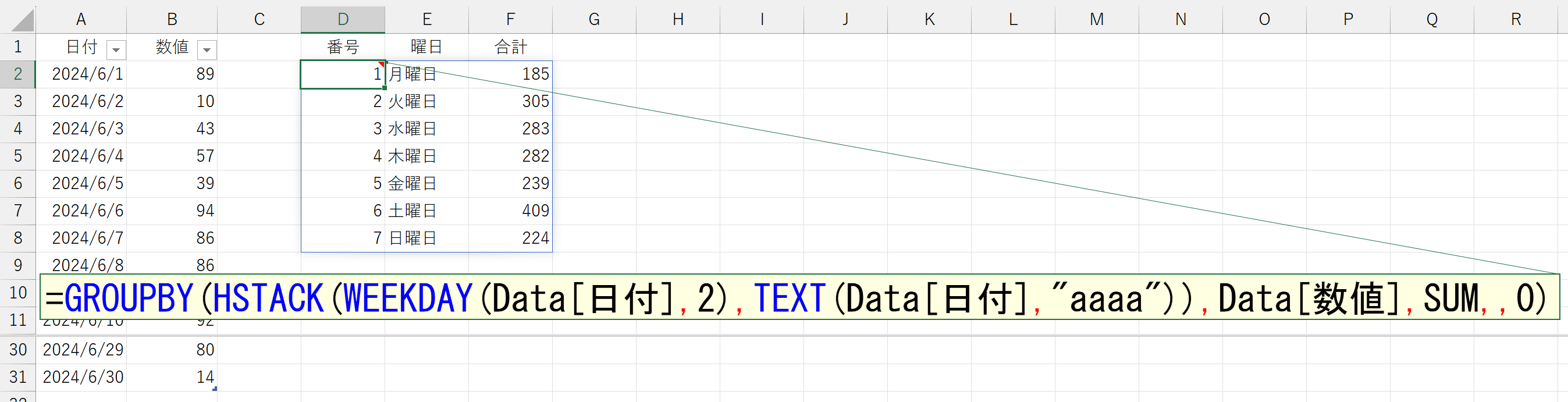
これで望みどおり並べ替えられました。並べ替えができたのですから、左端の「番号」列はもう不要です。DROP関数で除外しましょう。
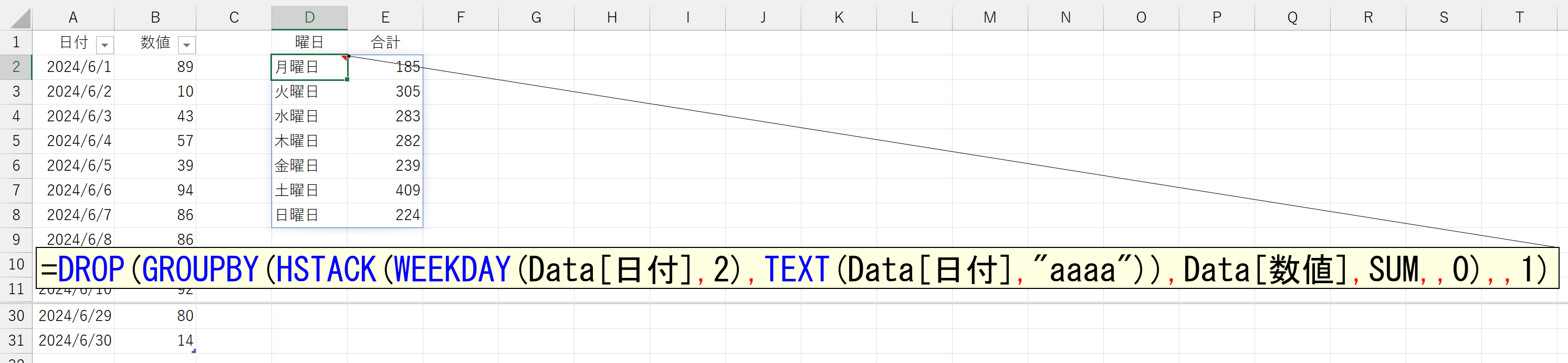
ね、意外と簡単でしょ。
DROP関数については、下記ページを参照してください。
この引数に関する解説は以上です。特に触れませんでしたが、引数「並べ替え(sort_order)」を使わずに、SORT関数で並べ替えを行えば、いろいろと柔軟な並べ替えも可能です。
引数「フィルタ(filter_array)」
指定した条件でフィルタした行だけを集計します。これは、動作の例を見れば一目瞭然でしょう。
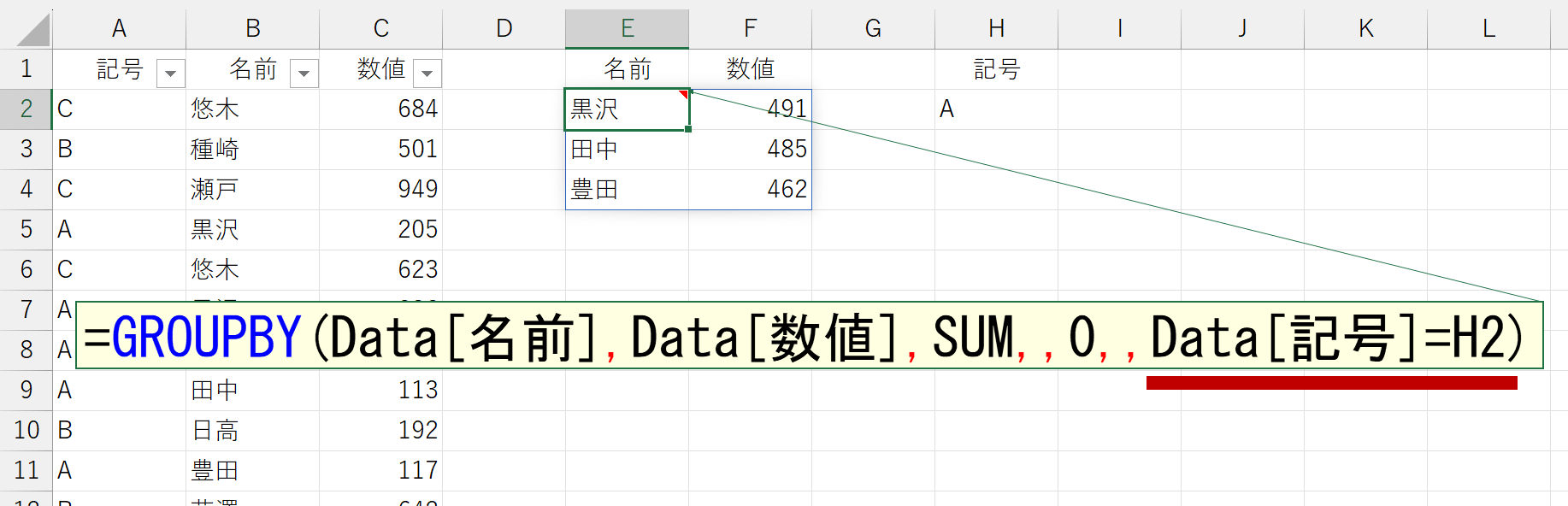
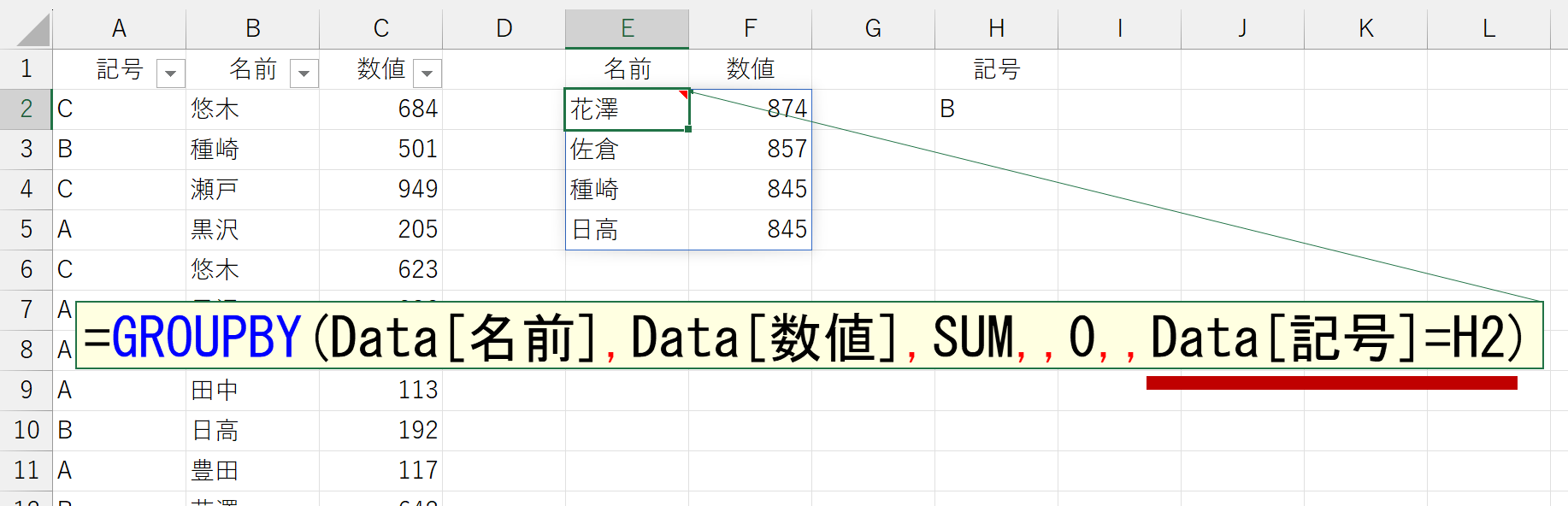
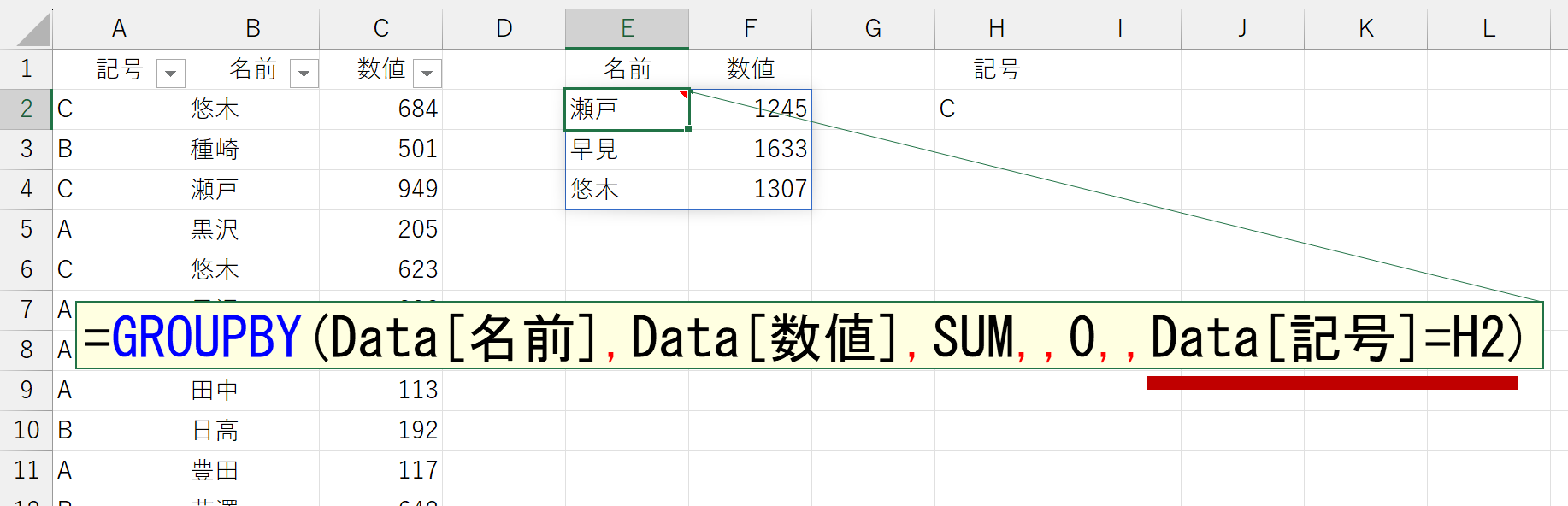
フィルタ条件の書き方は、FILTER関数と同じです。FILTER関数については、下記ページを参照してください。
引数「リレーション(field_relationship)」
引数「並べ替え(sort_order)」の解説をご覧ください。
まとめ
本稿の冒頭で、GROUPBY関数のことを『簡単にザックリ言うと「SUMIFやCOUNTIFを、ワンタッチで計算」してくれるヤツです』と言いましたが、これは、あまりにも表面的すぎましたね。SUMIF関数やCOUNTIF関数では不可能なことも、GROUPBY関数でしたら実現可能です。決して、SUMIF関数やCOUNTIF関数の上位互換版ではありません。まったく別の、Excelの可能性をさらに広げてくれる、新しいワークシート関数です。上記では(少しだけ)あれこれと文句も書きましたがw そういうところも含めて、とてもよく考えられて作られた関数だと感じます。応用範囲も実に広い。ARRAYTOTEXT関数を使った文字列操作の集計というのも斬新ですし、ちょっと試してみましたが、正規表現系の関数と組み合わせると、驚くような処理もできました。私の中では、かなり評価は高いです。気に入りました。みなさんも、ぜひ使ってみてくださいな。