[作って]数式担当さんと仲良くなりたい
【2025年9月】
AIにマクロを作ってもらうと、かなり高品質なコードを提示してくれます。ときどき間違えたり、方向性が変わったりしますが、作ってくれる毎回のコードは信頼できます。また、操作の手順を聞くと、ちょっと言葉足らずなところはあるものの、全体の流れは的確です。"AIの中の人"のうち「VBA担当さん」と「機能担当さん」とは、かなり良好な関係が築けているのではないかと。さて、問題は「数式担当さん」です。「こういう数式を作って」と依頼しても、どうにもこちらの意図をくんでくれません。いや、実力はあると思いますよ。だって「数式の説明」や「エラーの修正」などでは、すばらしい回答を提示してくれるのですから。信頼は、しています。ただ、きっと、こちらの言い方が悪いのでしょう。伝え方(プロンプト)が適切じゃないから、こちらの望んだ数式を作ってくれないのだと思います。なので今回は、どのように依頼したら、どういう数式を作ってくれるのか。どういうワードが必要なのかを、細かく検証してみたいと思います。
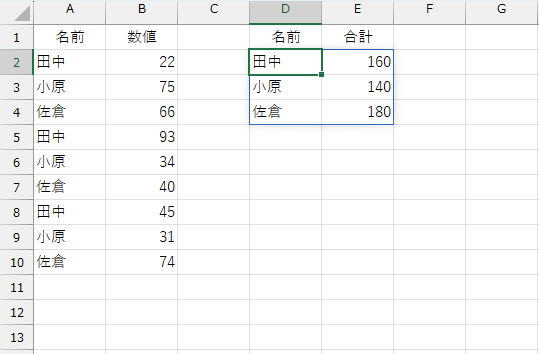
最初のテーマは、上図です。A列に名前、B列に数値が入っています。ここから、D列とE列に「名前別の合計」を作りたいんです。これ、私だったら2つのやり方が思いつきます。
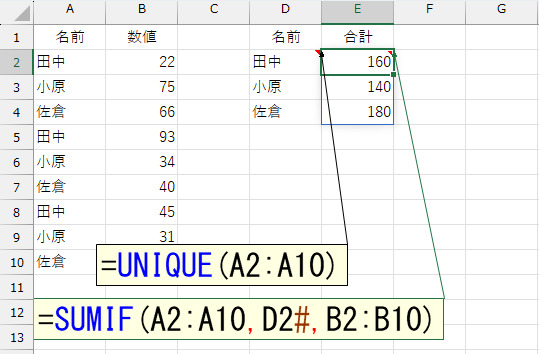
セルD2にUNIQUE関数を入れて、その結果をセルE2のSUMIF関数で集計します。あるいは、1つの数式でやるなら、
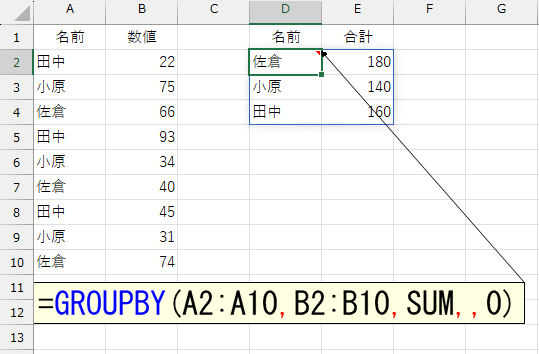
GROUPBY関数で一発です。まずは、このへんから作ってもらいましょう。ちなみに、元データは、あえてテーブルにしていません。最終的には、データの件数が増えても対応してもらいたいです。まずは、雑に頼んでみます。
A列とB列のデータから、名前別の合計をD列とE列に計算する数式を作ってください。
'Sheet2' の A1:B10 を調べ、列 C、D で確認および挿入 2 数式列を次に示します。 1. 名前2 「名前」列の値をそのままコピーして、データの確認や他の列との比較をしやすくしています。 =$A2 2. 合計 同じ「名前」ごとに「数値」を合計し、各人の合計値を表示します。これにより、 表内で個人ごとの総計が簡単に把握できます。 =SUM(FILTER($B$2:$B$10,$A$2:$A$10=$A2))
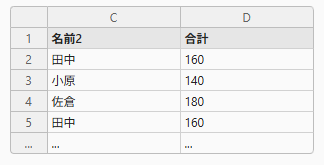
これ、数式担当さんの特徴です。AIはまず、表の中に数式を作ろうとします。プロンプトに「D列とE列に」と書きましたが、そこは伝わっていません。この程度は想定内です。AIへの指示では「どのセルに入力する数式」なのかを明示しなければなりません。
セルD1に入力する数式を作ってください。A列とB列のデータから、名前別の合計をD列とE列に計算する数式を作ってください。
結果は、まったく同じだったので省略します。こんなことで落胆していては始まりません。今回の指示で「名前別の合計をD列とE列に計算する」部分を理解してくれませんでした。なので、そこをもっと詳細に伝えてみます。
セルD1に入力する数式を作ってください。A列とB列のデータから、D列に重複しない名前のリストを作り、E列にはD列に表示されている名前ごとの合計を求めてください。
D1セルに入力する数式は以下の通りです。 D列に重複しない名前リスト、E列に各名前ごとの合計を表示します。 D2セル(重複しない名前リスト): =UNIQUE(A2:A10) E2セル(各名前ごとの合計): =SUMIF(A2:A10, D2#, B2:B10) D2セルに上記の数式、E2セルに上記の数式を入力してください。
私が想定した数式です。つまり「名前別の合計をD列とE列に計算する」ではなく、D列にはどういう結果で、E列ではどんな計算をするのか、具体的に伝えなければいけないということですね。でも、まだ「セルD1に入力する数式」が伝わっていません。次のようにリクエストしてみます。
A列とB列のデータから、D列に重複しない名前のリストを作り、E列にはD列に表示されている名前ごとの合計を求めるような、セルD1に1つだけ入力する数式を作ってください。
重複しない名前リスト : 田中,小原,佐倉
'Sheet2' の A1:B10 を調べ、1 つの数式を確認して 選択したセル に挿入します:
=TEXTJOIN(",",TRUE,UNIQUE($A$2:$A$10))
名前の列から重複を除いた一覧をまとめて表示します。
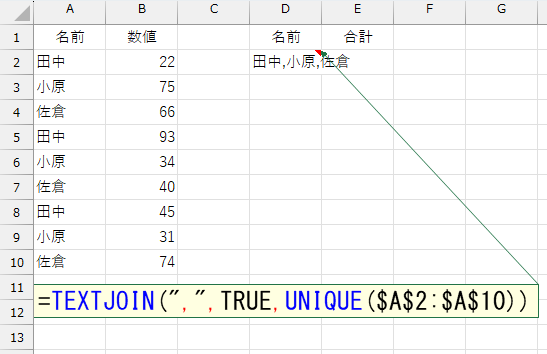
これなんですよ、数式担当さんの困るとこは。プロンプトでの指示は、それほど変わっていないのに「数値を合計」部分がスッポリ抜けています。さっきはできたのに…って。AIのチャットは、基本的に直前の回答を覚えていません。このへん難しいのですが、直前の回答に対して「提示された数式では~」みたく質問すると参考にしてくれることもあるのですが、「○○して」のように新しい質問では考慮してくれません。ちなみにこれは、マクロの作成でも同様です。GeminiとかChatGPTをブラウザで使っていると、彼らはチャット内のやり取りを覚えています。Geminiとのやり取りで「さっき言ったように」みたいに回答されたこともあります。Excel内のAIチャットも、基本的には同じだと思いますが、新規の質問では"参考にしない傾向"が強いと感じます。試しに、ブックを開きなおして、ひとつ前のプロンプトからやってみます。
A列とB列のデータから、D列に重複しない名前のリストを作り、E列にはD列に表示されている名前ごとの合計を求めるような、セルD1に1つだけ入力する数式を作ってください。
重複しない名前リスト(改行区切り) : 田中 小原 佐倉 レビューと挿入対象の数式が 1 つあります。 =TEXTJOIN(CHAR(10),TRUE,UNIQUE($A$2:$A$10)) 名前の重複を除き、すべての異なる名前を改行で区切って一覧表示します。

同じプロンプトを送ったんですよ、これ。数式担当さんと意思疎通ができていないという、私の感覚が分かりますか。ちなみに、セルD1の"折り返して全体を表示する"をオンにすると、こうなります。
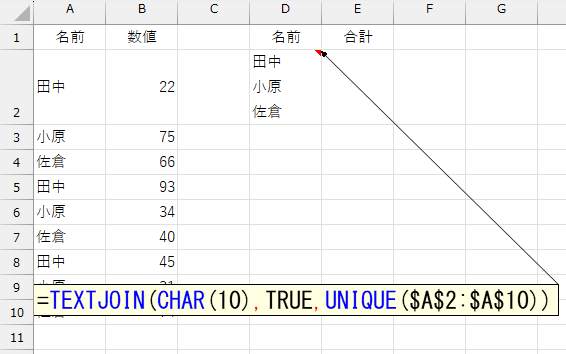
どこから"セル内改行"なんて発想になったのでしょう。もう一度ブックを開きなおして、Excelも起動し直して、ここまでのプロンプトを最初から与えてみます。
A列とB列のデータから、名前別の合計をD列とE列に計算する数式を作ってください。
まったく同じ結果でした。では次。
セルD1に入力する数式を作ってください。A列とB列のデータから、名前別の合計をD列とE列に計算する数式を作ってください。
これも同じです。同じように、表内への数式提案です。前回は、次から変化しました。
セルD1に入力する数式を作ってください。A列とB列のデータから、D列に重複しない名前のリストを作り、E列にはD列に表示されている名前ごとの合計を求めてください。
前回は、ここでUNIQUE関数とSUMIF関数が提示されたのですが、今回は先の2回とまったく同じ"表内への数式"が回答されました。念のため、次に送ったプロンプトで試してみます。
A列とB列のデータから、D列に重複しない名前のリストを作り、E列にはD列に表示されている名前ごとの合計を求めるような、セルD1に1つだけ入力する数式を作ってください。
=LET(
names, UNIQUE(A2:A10),
totals, MAP(names, LAMBDA(n, SUMIF(A2:A10, n, B2:B10))),
VSTACK({"名前","合計"}, HSTACK(names, totals))
)
結果が変わりました。望んでいた1つの数式ですけど、もう訳がわかりません。がんばって整理してみましょう。

同じプロンプトであって、AIの回答は毎回違います。ガチャみたいなもんです。一発でSSRを引けるなんて思わない方がいいです。
個別に作ってもらう
方針を変えます。ここまでは「D列に重複しない名前のリスト」と「E列に名前の合計」の2つの処理をする数式を依頼していました。これらを個別に作ってもらいます。ちなみに、Excelは再起動しました。
重複しない名前のリストを表示するセルD2の数式を作ってください。
=UNIQUE(A2:A10)
元データについては何も書きませんでしたが、AIがアクティブシート内を調べてくれました。セルA1に「名前」というヘッダがあるので、セル範囲A2:A10に入力されているのが"名前"だと理解したようです。
名前ごとの合計を求めるセルE2の数式を作ってください。
=SUMIFS(B2:B10, A2:A10, D2#)
セルD2は空欄セルのままで質問しました。AIは、先の提示を踏まえて「セルD2にUNIQUE関数が入力されている」という前提の回答をしましたね。このへんは、ひとつ前のやり取りを覚えているのでしょう。
セルD2のUNIQUE関数とセルE2のSUMIFS関数を、ひとつにまとめてセルD2に入力する数式を作ってください。
=LET(names, UNIQUE(A2:A10), sums, MAP(names, LAMBDA(n, SUMIFS(B2:B10, A2:A10, n))), HSTACK(names, sums))
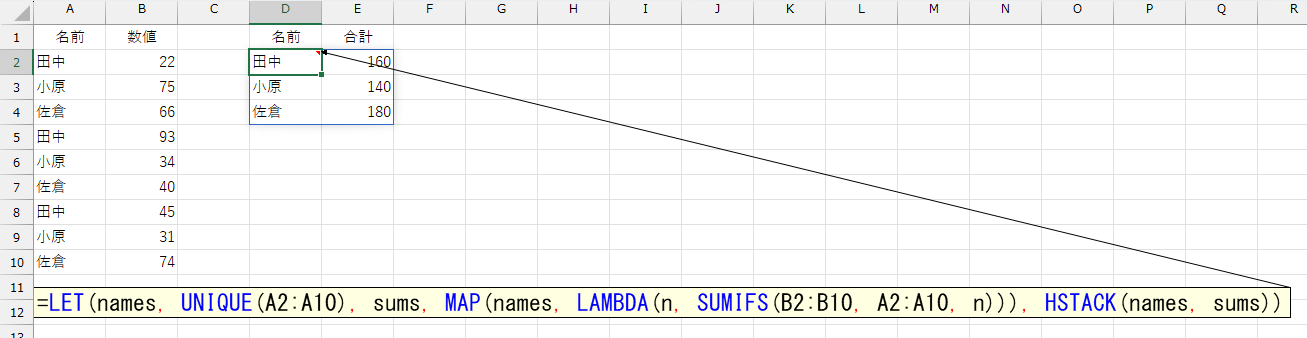
これ、合ってるんですよね。プロンプトの指示どおりです。「UNIQUE関数とSUMIFS関数をまとめて」と言いましたので、それを忠実に表しています。冒頭に書きましたが、同じことはGROUPBY関数でも可能です。何とか、そちらに導いてみましょう。
LAMBDA関数やHSTACK関数を使わないで同じ処理をする数式を作ってください。
'Sheet2' の A1:B10 を調べ、列 C、D、E で確認および挿入 3 数式列を次に示します。 1. 合計値(名前別) 各人の名前ごとに、すべての数値を合計して、その人が持つ合計値を算出します。 =SUMPRODUCT(($A$2:$A$10=$A2)*($B$2:$B$10)) 2. 出現回数(名前別) 各行の「名前」が表内で何回登場しているかをカウントし、同じ名前の出現頻度を把握できます。 =SUMPRODUCT(--($A$2:$A$10=$A2)) 3. 平均値(名前別) 同じ「名前」ごとに「数値」の平均を算出し、各行に表示します。これにより、 表内で個人ごとの傾向やパフォーマンスを簡単に比較できます。 =IFERROR(SUMPRODUCT(($A$2:$A$10=$A2)*($B$2:$B$10))/SUMPRODUCT(--($A$2:$A$10=$A2)),"")
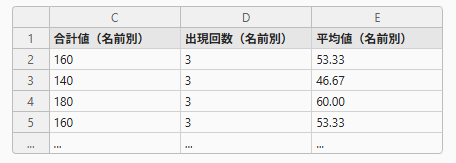
プロンプトに書いた"同じ処理"を「出現回数」や「平均値」と判断したのでしょうか。どうしよ?どうしたらいいの?なんて言ったらいいんだろ?
セルD2に入力した「=LET(names, UNIQUE(A2:A10), sums, MAP(names, LAMBDA(n, SUMIFS(B2:B10, A2:A10, n))), HSTACK(names, sums))」を、LAMBDA関数やHSTACK関数を使わないで同じ処理をする数式を作ってください。
'Sheet2' の A1:B10 を調べ、1 つの数式列を確認して 列 C に挿入します: 合計値 各名前ごとに「数値」を集計し、同じ名前の合計値を算出しています。これにより、 表内で個人ごとの総合的な数値の傾向を把握できます。 =SUM(FILTER($B$2:$B$10,$A$2:$A$10=$A2))
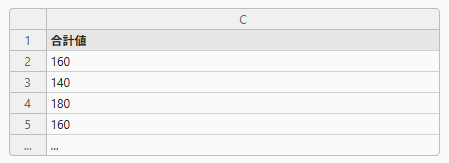
"同じ処理"って表現が悪いのか。変えてみよう。
セルD2に入力した「=LET(names, UNIQUE(A2:A10), sums, MAP(names, LAMBDA(n, SUMIFS(B2:B10, A2:A10, n))), HSTACK(names, sums))」を、LAMBDA関数やHSTACK関数を使わないで名前ごとの合計をD列とE列に表示する数式を作ってください。
以下のように、D2に「名前の一覧」、E2に「合計値」を表示できます。 D2(重複しない名前の一覧): =UNIQUE(A2:A10) E2(各名前ごとの合計値): =SUMIFS(B2:B10, A2:A10, D2#)
「プロンプトの書き方が悪かったので 3マス 戻り、全員に1000ドルずつ払う」なのかな?
よし、ちょっと反則だけど、まずはGROUPBY関数の話題からいってみよう。もちろんExcelは再起動します。
アクティブシートのデータを使って、GROUPBY関数の使用例を教えてください。
GROUPBY関数の使用例として、名前ごとに数値の合計や平均を集計する方法が考えられます。
pandasのgroupbyメソッドを使って、'名前'ごとに'数値'の合計や平均を計算する例を示します。
"=PY(""# Create the pandas DataFrame
Sheet2_A1_B10_df = xl(""""Sheet2!A1:B10"""", headers=True)
# '名前'ごとに'数値'の合計と平均を集計
result = Sheet2_A1_B10_df.groupby('名前')['数値'].agg(['sum', 'mean'])
result"",1)"
GROUPBY関数(pandasのgroupbyメソッド)を使うと、名前ごとに数値の合計や平均を簡単に
集計できます。たとえば、佐倉さんは合計180、平均60、小原さんは合計140、平均約46.7、
田中さんは合計160、平均約53.3となります。
このように、データをグループごとにまとめて集計するのにとても便利です。
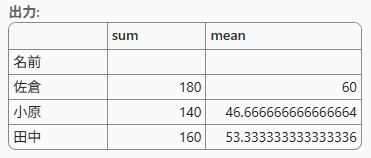
まぁ、GROUPBYって、いろんな言語などで使われてますしね。こんなことじゃ、めげません。
アクティブシートのデータを使って、ExcelのGROUPBY関数を使った使用例を教えてください。
「Sheet2」のA1:B10のデータ(名前・数値)を使い、名前ごとに数値の合計を集計する GROUPBY関数の例です。 =GROUPBY(A2:A10, B2:B10, SUM) この数式を空いているセル(例:D2)に入力すると、「名前」ごとに「数値」の合計が 一覧で表示されます。
なんだろ?今度はいきなりゴールした感覚です。このプロンプトを送るとき、アクティブシートは下図の状態でした。
セルD2が空欄セルで、セルE1には"合計"と入力されていたから、これほど的確なゴールを決めてきたのでしょうか。だったら、セルE1に"平均"と入力してから、同じ質問をしてみます。Excelは再起動します。
以下は、Sheet2のA1:B10のデータを使い、「名前」ごとに「数値」の平均を集計する GROUPBY関数の使用例です。 =GROUPBY(A2:A10, B2:B10, AVERAGE) この数式は、「名前」ごとに「数値」の平均値を計算して一覧表示します。
まとめ
長くなったので、今回はこのへんにします。今回の検証で感じたことを、いくつかまとめます。
まず、これは前から分かっていましたが、プロンプトが明確に書かれていないと、まったく方向違いの回答を返してきます。ただ、実を言うと、これが一番難しいなと思います。私は仕事がら、状況や望みを明確に、具体的に、分かりやすく記述する自信があります。しかし、多くの方にとっては、それが最も難しいのではないかと。根本的なポイントはこれです。
ほかに気づいたのが、AIはワークシートを見ているということ。同じデータで「GROUPBY関数の使用例を」と聞いたところ、セルに"合計"と入っているのか"平均"と入力されているのかによって、使用例を変えてきました。ワークシートの内容を知っている証拠です。
次に感じたのが、AIは既存のリストを分析しようとする特徴です。A列とB列からなるリストを集計して、結果をD列とE列に表示するというテーマで試しましたが、何度も「C列に数式を入れて、リストを拡張する」内容の回答を提示してきました。ときどきPythonの話題を振ってくるのも同じ理由かと。リストの中にさまざまな分析結果を追加する、という方向性で提案を作ろうとしているように感じました。最後に、複数の処理を一気に行う数式は、思いどおりに提案してもらえないということ。数式でやりたいことを細分化して、個別の処理ごとに質問するとゴールに近づけそうです。
あ、あともうひとつ。AIは新しい関数を使いたがらないです。たぶん、関数が"新しい"か"古い"かというよりも、その関数についての"情報が多いかどうか"に、影響されるのではないかと思います。AIは膨大な既存情報を機械学習します。世の中には、GROUPBY関数の情報よりも、VLOOKUP関数に関する情報の方が多いでしょう。歴史が違いますから。何度かの検証で、AIが使ってきた新しい関数は、LET関数、LAMBDA関数、MAP関数、BYROW関数、UNIQUE関数あたりです。これらはすべて"スピルありき"で作られた新しい関数ですけど、どれも有名なものばかりです。解説しているWebサイトも多いはず。別の検証でも、データの件数が不定のとき、列全体に対するCOUNTA関数を使用した数式を提示してきたり、ヘッダを指定して列全体を参照する数式のときに、一発でできるXLOOKUP関数ではなく、古典的なINDEX関数+MATCH関数のやり方を回答しました。今のExcelで、データ件数が不定だったら、TRIMRANGE関数や"トリム参照"を使えば解決します。
今回の検証を一言でまとめると『AIの回答はガチャ』ですかね~