この数式を説明してください
これは、嬉しい人が多いのではないですか?セルに入力されている数式の意味などを説明してくれる機能です。
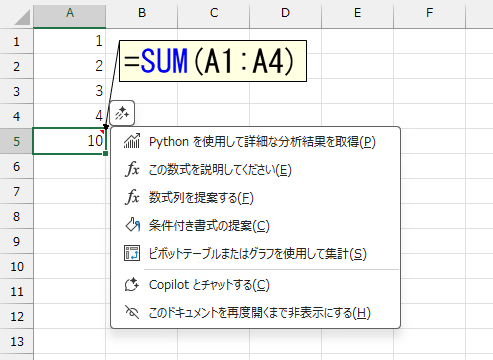
ちなみに、数式がエラーになっているときは「このエラーを説明して修正を提案してください」になります。
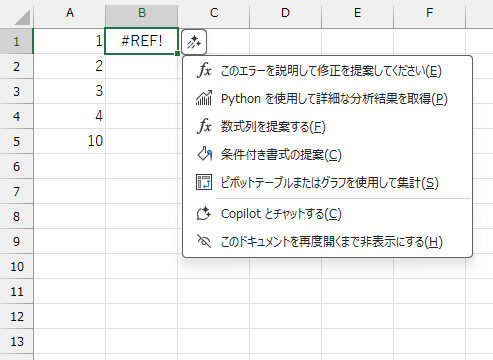
いずれにしても、ブックの自動保存がオンになっていないと使えません。自動保存に関しては、下記のページをご覧ください。
百聞は一見にしかずです。さっそく試してみましょう。
難易度:★
まずは超簡単なケースから。
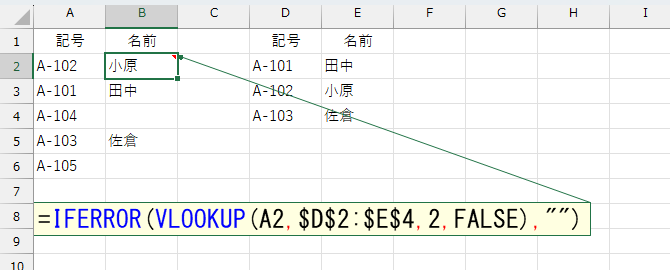
=IFERROR(VLOOKUP(A2,$D$2:$E$4,2,FALSE),"")
結果は、下図のように表示されます。
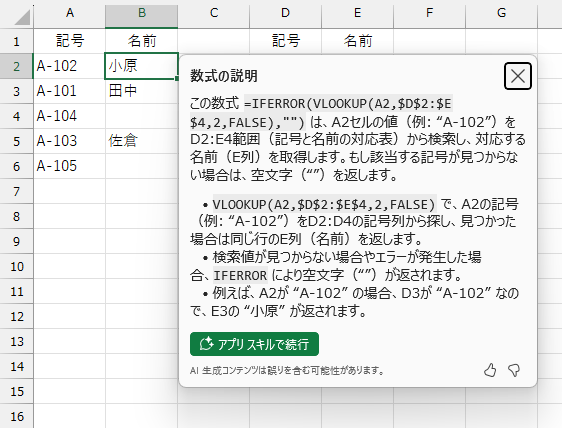
「この数式~」のところは、範囲選択して内容をコピーできます。
この数式 =IFERROR(VLOOKUP(A2,$D$2:$E$4,2,FALSE),"") は、A2セルの値(例: “A-102”)をD2:E4範囲(記号と名前の対応表)から検索し、対応する名前(E列)を取得します。もし該当する記号が見つからない場合は、空文字(“”)を返します。
• VLOOKUP(A2,$D$2:$E$4,2,FALSE) で、A2の記号(例: “A-102”)をD2:D4の記号列から探し、見つかった場合は同じ行のE列(名前)を返します。
• 検索値が見つからない場合やエラーが発生した場合、IFERROR により空文字(“”)が返されます。
• 例えば、A2が “A-102” の場合、D3が “A-102” なので、E3の “小原” が返されます。
うむ、的確な説明ですね。特に「(例: “A-102”)」のように、実際のセル内容を示してくれるのは助かります。では、ちょっと変えてみましょう。「記号と名前の対応表」部分をテーブルにします。名前は「Data」としましょうか。さらに、検索しているA列部分をスピらせます。
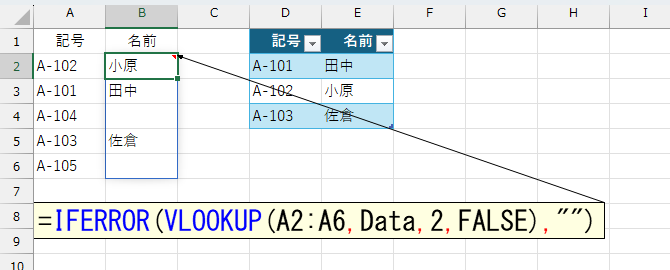
=IFERROR(VLOOKUP(A2:A6,Data,2,FALSE),"")
この数式 =IFERROR(VLOOKUP(A2:A6,Data,2,FALSE),"") は、範囲 A2:A6 の各「記号」について、テーブル「Data」から対応する「名前」を検索し、見つからない場合は空文字(“”)を返します。
• 範囲 A2:A6(例: “A-102”, “A-101”, “A-104”, “A-103”, “A-105”)の各値を順番に処理します。
• VLOOKUP 関数で、各「記号」を「Data」テーブル(D2:E4)から検索し、2列目(「名前」列)の値を取得します。
• 検索結果が見つからない場合(例: 「A-104」や「A-105」など「Data」に存在しない記号)、IFERROR 関数により空文字(“”)を返します。
• 結果として、A2:A6 の各「記号」に対応する「名前」が B2:B6 に表示され、該当がなければ空欄になります。
この説明が理解できるかどうかは、その人のExcelスキルによります。たとえば「各値を順番に処理します」というのがスピルを表しているのですが、そもそもスピルとは何か?どんな仕組みなのか?を理解していなかったら、ここで悩むでしょう。また、説明文には「空文字」「範囲」「値」「取得します」「返します」など、Excelの正式な用語が使われます。当たり前ですね。日頃から「これを引っ張ってくる」とか「あれを持ってくる」みたいに考えている人には、こうした正式用語って、堅苦しく感じるのではないでしょうか。まぁ、日頃の行いを反省して、がんばるしかないですね。
さて、さらに変えてみます。
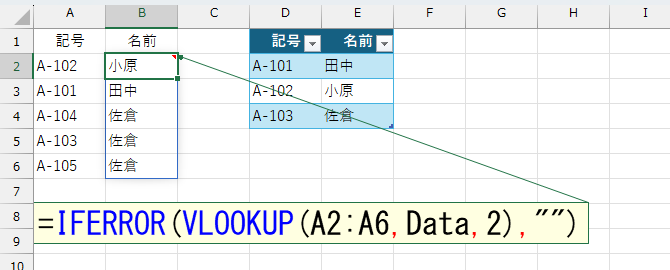
=IFERROR(VLOOKUP(A2:A6,Data,2),"")
セルB2の数式は、エラーにはなっていません。しかし、結果がおかしいです。理由はVLOOKUP関数の第4引数に"FALSE"を指定しなかったため、近似一致による検索が行われたからです。これの意味が分からない方は、下記のページをご覧ください。
さて、そこんところを、ちゃんと説明してくれるのでしょうか。
この数式 =IFERROR(VLOOKUP(A2:A6,Data,2),"") は、範囲A2:A6の各「記号」について、テーブル「Data」から対応する「名前」を検索し、見つからない場合は空欄を返します。
• VLOOKUP(A2:A6,Data,2) は、A2:A6の各セルの値(例: “A-102”, “A-101” など)を「Data」テーブルの1列目(記号列)で探し、見つかった場合は2列目(名前列)の値(例: “小原”, “田中” など)を返します。
• 検索値が「Data」テーブルに存在しない場合、VLOOKUPはエラーになります。
• IFERROR(...,"") により、エラーが発生した場合は空文字(“”)を返します。
この数式により、A列の記号に対応する名前がB列に自動で表示され、該当がなければ空欄になります。
エラーになっていないから、この数式は「正常に機能している」と判断したんですかね。人間だったら「何をやりたいのか」「どうなれば良いのか」を判断して、結果の誤りに気づくでしょうけど、今のAIには、まだそこまでは無理なのでしょう。上記のケース("FALSE"を忘れた)に対して「"FALSE"が抜けているのではありませんか?」って指摘してくれたら、さらにAIが人間に近づいた証拠ですね。いずれ、そんな時代が来ることを願っています。
難易度:★★
最近追加された新しい関数を試してみましょう。
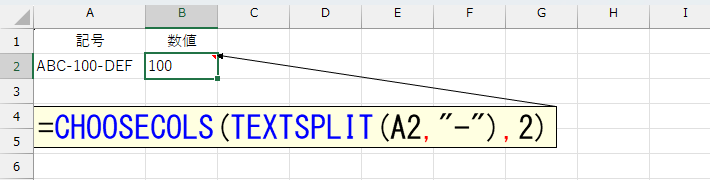
=CHOOSECOLS(TEXTSPLIT(A2,"-"),2)
この数式 =CHOOSECOLS(TEXTSPLIT(A2,"-"),2) は、セルA2の文字列「ABC-100-DEF」から「-」で区切った2番目の要素(「100」)を抽出しています。
• TEXTSPLIT(A2,"-") で、A2の値「ABC-100-DEF」を「-」で分割し、{“ABC”,“100”,“DEF”} という配列を作成します。
• CHOOSECOLS(...,2) で、その配列の2列目(2番目の要素)だけを取り出します。
• 結果として、B2には「100」が表示されます。
じゃ、もうちょっと複雑に。
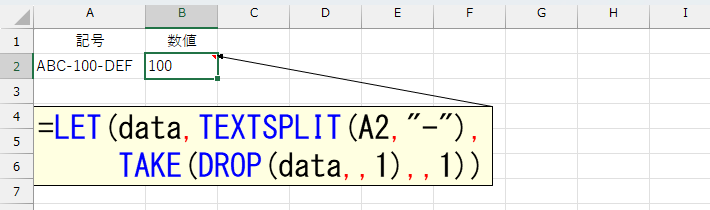
=LET(data,TEXTSPLIT(A2,"-"),
TAKE(DROP(data,,1),,1))
この数式 =LET(data,TEXTSPLIT(A2,"-"), TAKE(DROP(data,,1),,1)) は、セルA2の「ABC-100-DEF」から「100」という数値部分だけを抽出しています。
• TEXTSPLIT(A2,"-") で、A2の値「ABC-100-DEF」を「-」で分割し、{“ABC”,“100”,“DEF”} という配列を作成します。
• DROP(data,,1) で、配列の先頭1つ(“ABC”)を削除し、{“100”,“DEF”} になります。
• TAKE(...,,1) で、残った配列の先頭1つ(“100”)だけを取得します。
• 結果として、B2には「100」が表示されます。
この数式は、記号の中央にある数値部分だけを簡単に取り出すためのものです。
いいですね~ まぁ、これくらいは誰でも簡単に分かりますよね。なんか楽しくなってきたw
難易度:★★★
古典的な「FIND列挙」いってみよう。
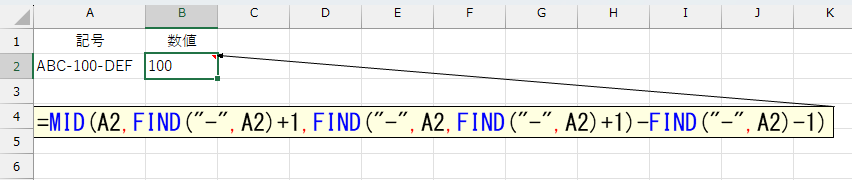
=MID(A2,FIND("-",A2)+1,FIND("-",A2,FIND("-",A2)+1)-FIND("-",A2)-1)
この数式 =MID(A2,FIND("-",A2)+1,FIND("-",A2,FIND("-",A2)+1)-FIND("-",A2)-1) は、セルA2(値: “ABC-100-DEF”)の文字列から、最初の「-」と2番目の「-」の間にある文字(この場合「100」)を抽出します。なかなかやるな…。「最初の「-」と2番目の「-」の間にある文字」ってのが的確。
• FIND("-",A2):A2内で最初に「-」が現れる位置(4文字目)を取得します。
• FIND("-",A2)+1:最初の「-」の次の文字(5文字目)から抽出を開始します。
• FIND("-",A2,FIND("-",A2)+1):A2内で2番目の「-」が現れる位置(8文字目)を取得します。
• FIND("-",A2,FIND("-",A2)+1)-FIND("-",A2)-1:2つの「-」の間の文字数(8-4-1=3)を計算します。
• MID(A2,開始位置,文字数):A2の5文字目から3文字分(「100」)を抽出します。
つまり、「ABC-100-DEF」の「-」で囲まれた「100」だけを取り出す数式です。
難易度:★★★★
スピルが実装されるより、はるか昔に作った配列数式です。文字列と文字列の間に挟まれた数値部分を抜き出します。
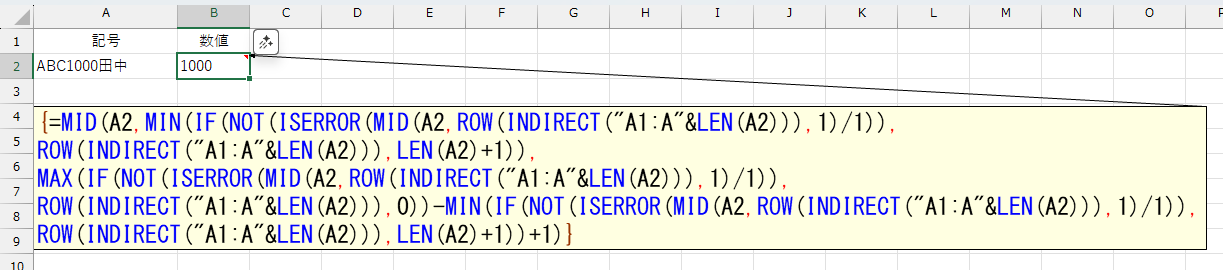
入力するときは、Ctrl + Shift + Enterしてください。
=MID(A2,MIN(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),ROW(INDIRECT("A1:A"&LEN(A2))),LEN(A2)+1)),MAX(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),ROW(INDIRECT("A1:A"&LEN(A2))),0))-MIN(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),ROW(INDIRECT("A1:A"&LEN(A2))),LEN(A2)+1))+1)
この配列数式 {=MID(A2,MIN(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),
ROW(INDIRECT("A1:A"&LEN(A2))),LEN(A2)+1)),
MAX(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),
ROW(INDIRECT("A1:A"&LEN(A2))),0))-MIN(IF(NOT(ISERROR(MID(A2,ROW(INDIRECT("A1:A"&LEN(A2))),1)/1)),
ROW(INDIRECT("A1:A"&LEN(A2))),LEN(A2)+1))+1)} は、セルA2(例:「ABC1000田中」)の中から連続した数字部分(この例では「1000」)だけを抽出します。
主な処理の流れは以下の通りです。
• ROW(INDIRECT("A1:A"&LEN(A2))) でA2の文字数分の連番配列(1,2,3,…)を作成します。
• MID(A2, ..., 1) でA2の各文字を1文字ずつ取り出します。
• MID(...)/1 で各文字を数値変換し、数字ならエラーにならず、数字以外はエラーになります。
• NOT(ISERROR(...)) で数字かどうかを判定します(数字ならTRUE)。
• IF(..., ROW(...), LEN(A2)+1) で数字の位置(行番号)を取得し、数字でなければA2の長さ+1を返します。
• MIN(...) で最初に現れる数字の位置を取得します。
• 同様に MAX(...) で最後に現れる数字の位置を取得します。
• MID(A2, 開始位置, 文字数) で、最初の数字から最後の数字までを抽出します。
この数式は、A2の中で最初から最後まで連続している数字部分を抜き出すために使われます。
ちょこっとだけ補足します。この数式のキモは「ROW(INDIRECT("A1:A"&LEN(A2)))」部分です。セル内の文字を左から1文字ずつ処理したいんです。VBAでやるなら、次のような感じかな。
Dim i As Long
For i = 1 To Len(Range("A2").Value)
Mid(Range("A2").Value, i, 1) ''に対する処理
Next i
もし、セルA2の文字数が9文字だったら、「INDIRECT("A1:A"&LEN(A2))」が「INDIRECT("A1:A9")」になります。このセル範囲の行番号を「ROW(INDIRECT("A1:A9"))」のように調べると、これは配列数式ですから {1,2,3,4,5,6,7,8,9}という配列を返します。これを使ってMID関数で「1文字目から1文字分」「2文字目から1文字分」「3文字目から1文字分」…と抜き出します。元データがセルA2なのに、なぜINDIRECT("A1:A9")なのか分かりますか?ただ配列を作りたいだけなので、INDIRECT関数に指定するセル範囲は、どこでもいいんです。何ならINDIRECT("M101:M109")でもOKです。15年くらい前のVBAセミナーで質問されたので作ったんですけど、いやはや"若気の至り"ですね~良い子は真似しちゃダメだお。
ちなみ、今のExcelだったら、正規表現使って一発です。
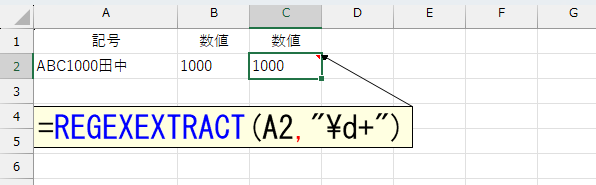
便利な時代になったものです。長生きはするものですね~
難易度:★★★★★
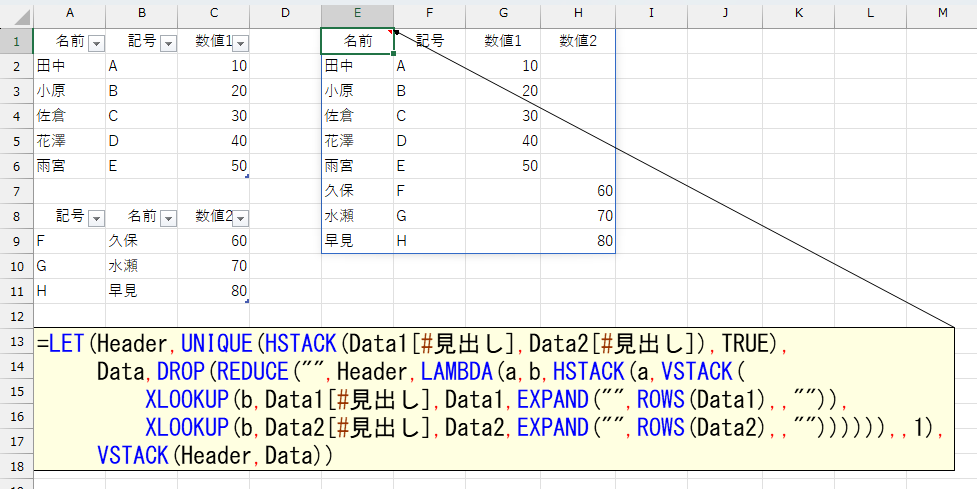
=LET(Header,UNIQUE(HSTACK(Data1[#見出し],Data2[#見出し]),TRUE),
Data,DROP(REDUCE("",Header,LAMBDA(a,b,HSTACK(a,VSTACK(
XLOOKUP(b,Data1[#見出し],Data1,EXPAND("",ROWS(Data1),,"")),
XLOOKUP(b,Data2[#見出し],Data2,EXPAND("",ROWS(Data2),,"")))))),,1),
VSTACK(Header,Data))
この処理に関しては、どんなデータで何をしたいのかについて、下記のページで詳しく解説していますので、そちらをご覧ください。
この数式 =LET(Header,UNIQUE(HSTACK(Data1[#見出し],Data2[#見出し]),TRUE), Data,DROP(REDUCE("",Header,LAMBDA(a,b,HSTACK(a,VSTACK( XLOOKUP(b,Data1[#見出し],Data1,EXPAND("",ROWS(Data1),,"")), XLOOKUP(b,Data2[#見出し],Data2,EXPAND("",R
OWS(Data2),,"")))))),,1), VSTACK(Header,Data)) は、Sheet5の「Data1」と「Data2」テーブルの列見出しを統合し、両テーブルのデータを見出しごとに縦に連結した新しいテーブルを作成します。
主な処理の流れ:
• Header で、両テーブルの列見出し(ヘッダー)を結合し、重複を除去して一意な見出しリストを作成します。
• REDUCE と LAMBDA を使い、各見出しごとに「Data1」と「Data2」から該当列を抽出し、縦方向(VSTACK)に連結します。該当列がない場合は空白で埋めます(EXPAND)。
• HSTACK で各見出しごとのデータを横方向に連結し、DROPで不要な先頭列(空文字列)を削除します。
• 最後に VSTACK でヘッダー行とデータ本体を上下に連結し、1つの新しいテーブルとして出力します。
この数式は、2つのテーブルの列構成が異なっていても、すべての列を網羅した統合テーブルを自動生成するために使われます。
この数式のポイントは、ヘッダが見つからないとき空白セルを表示する「EXPAND("",ROWS(Data1),,"")」です。これは、よくあるEXPAND関数の一般的な使い方ではないので、何をやっているのか意味が分かりにくいと思います。それをAIは「該当列がない場合は空白で埋めます(EXPAND)」と説明したのは見事ですね。
変な数式
最後に「どう考えても、それって変でしょ」という数式の説明をしてもらいましょう。そんな変な数式を作る自信がないので、以前Schooの授業で、受講生から提示された数式を使います。
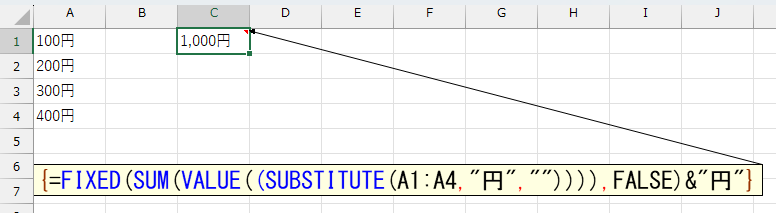
何でも「こういうことをしたいです」とネットの掲示板で質問したら、この数式を提示されたらしいです。ツッコミどころ満載ですw 授業の時期は覚えていませんが、スピルが実装される前ではなかったはず。それなのに配列数式を提示してきたのも謎ですね。
入力するときは、Ctrl + Shift + Enterしてください。
=FIXED(SUM(VALUE((SUBSTITUTE(A1:A4,"円","")))),FALSE)&"円"
この配列数式 {=FIXED(SUM(VALUE((SUBSTITUTE(A1:A4,"円","")))),FALSE)&"円"} は、範囲A1:A4に入力された「100円」「200円」などの金額から「円」を取り除いて数値化し、合計を「1,000円」のような書式で表示します。
• SUBSTITUTE(A1:A4,"円","") で、A1:A4の各セルから「円」を削除します(例: “100円” → “100”)。
• VALUE(...) で、文字列になった数字を数値に変換します。
• SUM(...) で、A1:A4の数値を合計します(例: 100+200+300+400=1000)。
• FIXED(...,FALSE) で、合計値をカンマ区切りの文字列(小数点なし)に変換します(例: 1000 → “1,000”)。
• &"円" で、最後に「円」を付けて「1,000円」と表示します。
この数式は、A1:A4の合計金額を「円」付きで見やすく表示するためのものです。
まぁ「こうなります」という説明としては正しいです。正しいですけど、それでいいんですかね?先の、VLOOKUP関数で"FALSE"を忘れたケースのように、エラーにはなっていなくても、数式を修正すべき(修正したらどうか)という提案は、現在のところ示されないのですね。AIのクオリティというよりも、これがExcelにとってどんな機能なのかという"設計思想"的なことなのかもしれません。なお、この変な数式のツッコミどころについては、下記のページで詳しく解説していますので、興味のある方はご覧ください。
注意(というほどでもないけど)
ここでご紹介した数式以外にも、いままで個人的に難解な数式を大量に説明してもらっています。最近は、難しい数式を作ったときは必ずチェックするようにしていますけど、今まで間違った説明に出会ったことがありません。現状で、かなりの高精度だと思います。とはいえ、数式は複雑です。かなり極端なケースですが、下図をご覧ください。
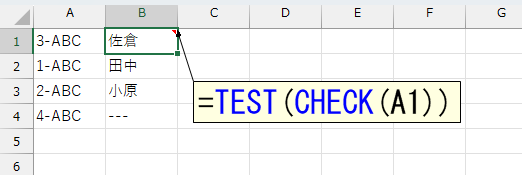
この数式 =TEST(CHECK(A1)) は、セルA1の値「3-ABC」を使って、まず CHECK 関数を実行し、その結果を TEST 関数に渡して処理しています。
• CHECK(A1) は、A1の値「3-ABC」を何らかの方法でチェックまたは変換するユーザー定義関数と思われます。
• TEST(...) は、CHECK の結果をさらに検証・変換・判定するユーザー定義関数と思われます。
• この数式は、A1の内容に基づいて2段階の処理を行い、最終的な結果をB1に表示します。
※ CHECK や TEST はExcel標準の関数ではないため、具体的な処理内容は定義によります。
この説明は正しいです。Excelには、TEST関数もCHECK関数も存在しません。両者はExcelに組み込まれている標準関数ではないので(AIはそれを知っているので)、おそらくそれらは"ユーザー定義関数"ではないかと。半分正解です。では、まずCHECK関数から種明かしをします。これは指摘とおり"ユーザー定義関数"です。ユーザー定義関数というのは、VBAで作ったFunctionプロシージャのことで、これをセルの中で、あたかも一般のワークシート関数のように使えるという仕組みです。

このFunctionは、引数に文字列を受け取り、Left関数で左1文字を抽出し、それを数値化します。CHECK関数の実体は判明しましたが、VBEのどこを探してもTESTというFunctionプロシージャは見当たりません。実は、TESTはユーザー定義関数ではなく"名前定義"です。Excelには、セルに好きな名前を定義する機能があります。でも、実は名前定義機能を使って、数値や文字列、果ては任意の数式にも好きな名前を定義できるんです。名前定義に関して、もっと詳しく知りたいかたは、下記のページをご覧ください。ちなみにメッチャ詳しく書いたので、超長文です。
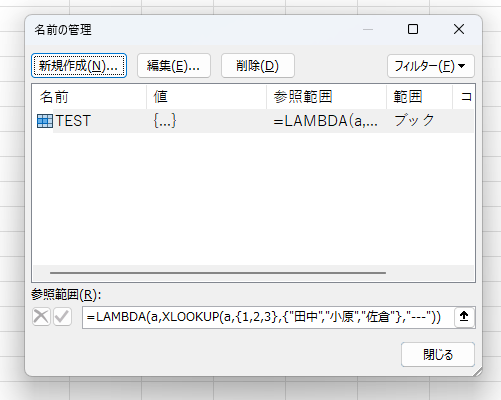
ここに定義されています。定義されている数式は「=LAMBDA(a,XLOOKUP(a,{1,2,3},{"田中","小原","佐倉"},"---"))」です。この数式は、LAMBDA関数を使って、引数として受け取った数値によって「1→"田中"」「2→"小原"」「3→"佐倉"」「それ以外→"---"」を返します。
まぁ、これは極端なケースですけど、それくらい数式作成は奥が深い、というか、いろんなことができます。外部の他ブックを参照したり、関数のバグを利用した動作なども作れます。もちろん実務では、第三者が理解に苦労するような数式や、後任者の手に余るような数式を、使うべきではありません。でも、数式の作成者が、ちゃんとそれを意識しているでしょうか。複雑な処理をネットで検索し、「とりあえずできた(と思っている)」で使っているケースって、きっと多いです。そうして作成された数式やブックの構造などに難解な要素が含まれていることは珍しくありません。現在のAIでは、まだそこまでは面倒見てくれないんですよ、という話です。たとえば上記のケースで、Excelの「名前定義」という機能を知らないビギナーだったら、AIの説明だけでは真相に行き着きません。だって、説明の中に"名前定義"という言葉(ヒント)が書かれていないのですから。さらに、ユーザー定義関数だと判明しても、結局「何をしているのか」を理解するために、今度はVBAの知識が必要になります。
「この数式を説明してください」は、とても有益で高性能な仕組みだと思います。PowerPointやWordなどでもAIを活用できますが、さてExcelでは、どんな使い方があるんだろう?って思ってましたけど、さすがMicrosoftですね、かなり役立つ機能を提供してくれました。Pythonで高度な分析をする、みたいに、ごく一部の人しか必要としていない機能と比べても、この「この数式を説明してください」は多くのExcelユーザーにとって助けとなるでしょうね。