データのクリーニング
[データ]タブ[データツール]グループに追加された「データのクリーニング」は、シート内に存在するデータ(数値や文字列)の"揺れ"や"ゴミ"などを検知して、指摘してくれる機能です。
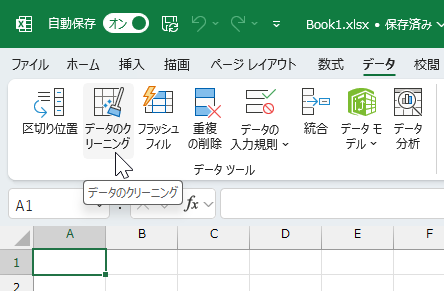
上の画像は、見やすくするため[データツール]グループを[データ]タブの左端に移動していますが、標準状態の[データツール]グループは、もっと右の方にあります。この機能は、喜ぶ人が多いのではないかと。実際にデモなどで紹介したときの反応もよかったです。現在チェックできる項目は、次の3種類です。
- 一貫性のないテキスト
- 一貫性のない数値形式
- 余分なスペース
注意
この機能は、ブックの自動保存がオンになっていないと使えません。

・使える
・使えない
ブックの自動保存をオンにするには、そのブックが、OneDriveまたはMicrosoft 365のShareointに保存されていなければなりません。つまり、パソコン内に保存されているブックや、共有フォルダなどNASに保存されているブックなどでは使えないということです。それだけ聞くと、ちょっと不自由な使いにくさを感じるかもしれませんけど、いずれにしてもCopilotが搭載されているのは、Microsoft 365からインストールしたExcel(ProPlus)です。Excel 20xxなどの永続ライセンス版では使用できないと思います(すみません、確認はしていませんし、今後どうなるか分かりません)。であれば、必ずOneDriveは使用できるはずです。Windows 11だったら、デスクトップフォルダやドキュメントフォルダは、標準でOneDriveに保存されますので、一時的にでも、そこに置けばよろしいかと。さらに言えば、もしパソコン内に保存されたブックをCopilotで扱うのなら、まずそのブックをMicrosoftに送信しなければなりません。これは非現実的でしょう。なので、多少の不便さは許容範囲かなって思います。なお、ブックの自動保存に関しては、下記Microsoftのページに詳しく書かれていますので、ご覧ください。
ブックを開いたとき自動的にチェックされる
この機能の変わっているところは、ブックを開いたとき自動的にチェックされることです。
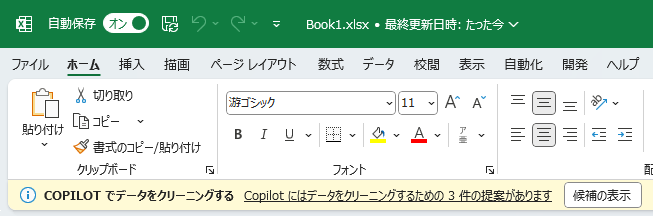
[候補の表示]ボタンをクリックすると、画面の右にサイドペインが開き、どこに問題があるか指摘してくれます。
この「開いたときの自動チェック」は、まずアクティブシートをチェックして、アクティブシートに異常がなかったら次のシートを調べ、最初に異常が見つかったシートを指摘します。
余談ですが、以前の仕様では、開いたときに全シートをチェックしていました。動作確認したところ、本稿執筆時点では、最初に異常が見つかったシートで止まるようです。ちなみに、リボンの[データのクリーニング]ボタンをクリックすると、アクティブシートだけをチェックして、他のシートは調べません。アクティブシートに異常が見つからないと、その旨が表示されます。

個人的な感想ですが。この「開いたときの自動チェック」って、ちょっとウザいと感じました。データの中には、あえて微妙に表記を揺らしているものもあります。そこに意味があるからです。しかし、そうした"あえて"やっている場合でも、毎回「ここがぁ!おかしいですぅ!」と指摘されて、毎回「っせーよ!知ってるつーの!」って舌打ちしました。できるなら、Excelのオプションで「開くときの自動チェックをしない」などの設定を選べればいいのですけどね。探しましたが、今のところそうしたオプションは見当たりませんでした。まぁ、自動チェックのおかげで、意図しないミスに気づくこともあるでしょうから、一概には言えませんけど。
複数の異常パターンが見つかったとき
「データのクリーニング」でチェックされるのは、次の種類です。
- 一貫性のないテキスト
- 一貫性のない数値形式
- 余分なスペース
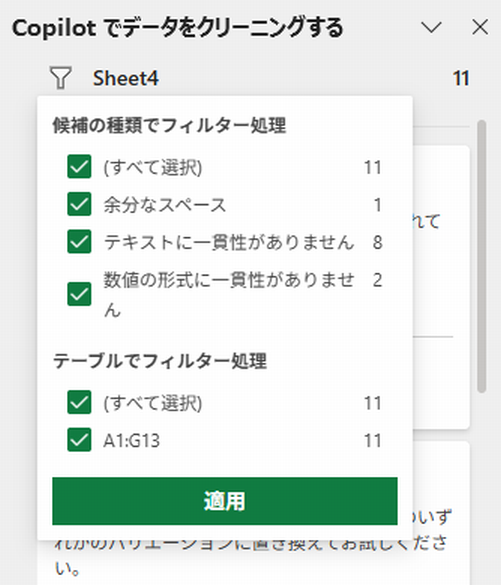
ケースによっては、複数の種類が、しかも大量に見つかるかもしれません。サイドペインの[フィルタ]アイコンをクリックすると、指摘の種類をフィルタリングできます。
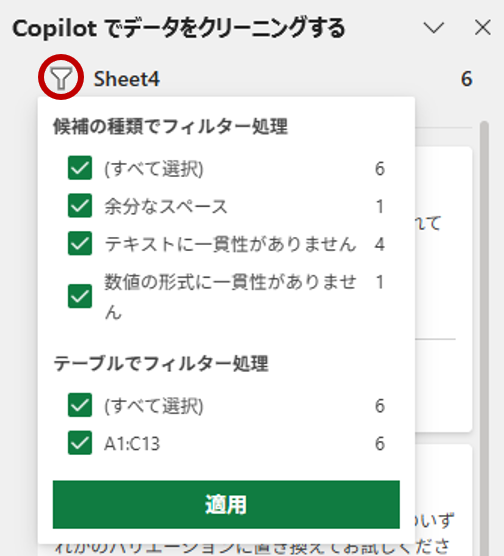
[候補の種類でフィルタ処理]は、分かりやすいです。その下の[テーブルでフィルタ処理]ですが、シート内で見つかった領域を指定するフィルタです。たとえば、下図のようなリストがあったとします。
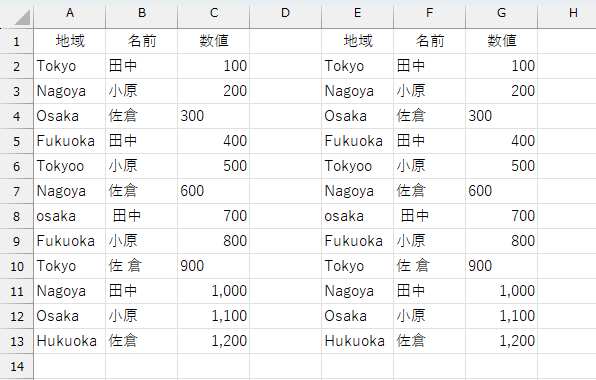
空欄のD列で区切られているから、ここには2つのリストがある…というのは、人間の判断でしょう。それって、あなたの感想ですよね。Excelは、これらを"1つのリスト"として認識します。
この「データのクリーニング」に関するヘルプには、次のように記載されています。
ちょっと分かりにくい日本語ですが、要するに「データはテーブル形式にしといてね!それがいいよ!」ってことです。ちなみに、上図2つのリストがテーブル形式になっていると、次のように表示されます。
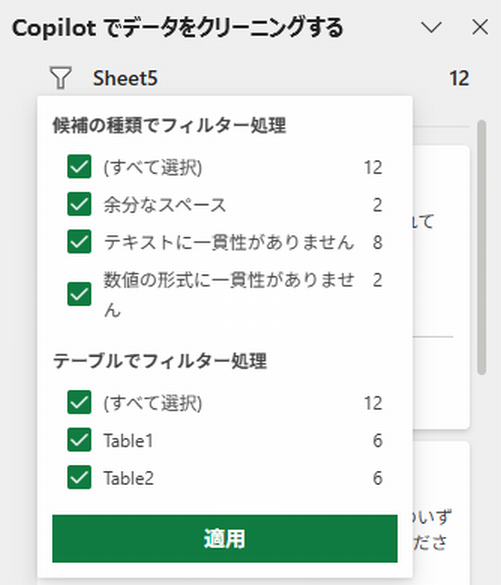
これなら、目的のテーブルを選ぶことで、作業が効率化できます。余談ですが、いつも私はセミナーや講演などで「テーブルを使わない理由がない」と言っていますが、それには複数の意味があります。そのひとつが、これです。Microsoftは新しい便利な機能や関数を追加するとき、「データはテーブル形式になっている」という前提で作っています。もうね、テーブルが当たり前なんです。デフォなんです。実装から18年経った今でも「テーブルって1行おきに色を塗る機能でしょ」って勘違いしてる人や「テーブルって使いにくいし、よく分かんない」って人が多くて驚きますが、もうそんなことを言ってる時代じゃありません。
ちなみにヘルプには、もうひとつ気になる情報が書かれていました。

「最大100列と50,000行」という制限らしいですが、翻訳された「最適です」が"マスト"なのか"ベター"なのかが不明ですね。そんな大量のサンプルを作って動作検証するのも大変なので、やってません。にしても、最近追加された新しい機能で、こうした元データの大きさ制限って珍しいです。もっとがんばれよ>AI って感じますけど、このへんも今後改善されるかもしれませんね。
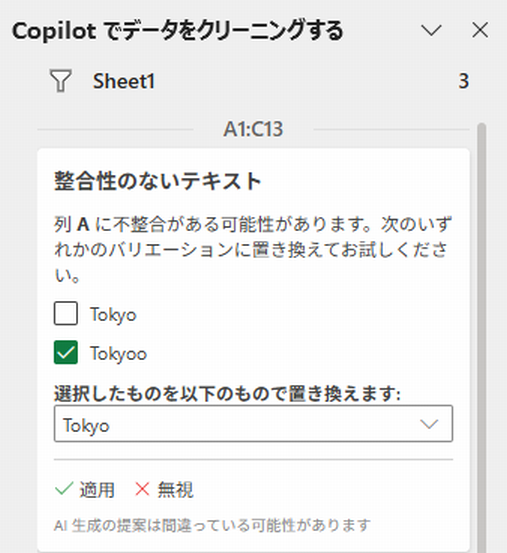
一貫性のないテキスト
では、具体的なチェックについて見ていきましょう。まずは「一貫性のないテキスト」です。A列の文字列に、表記のブレがあります。
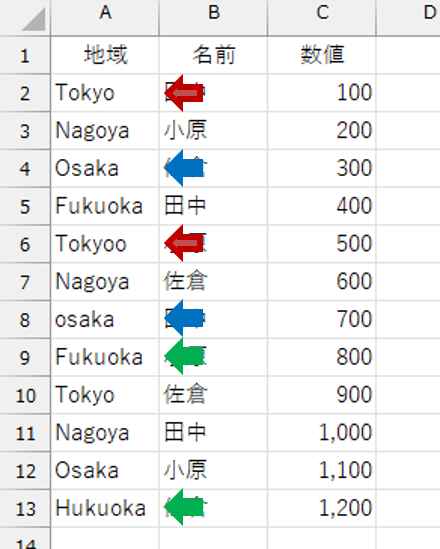
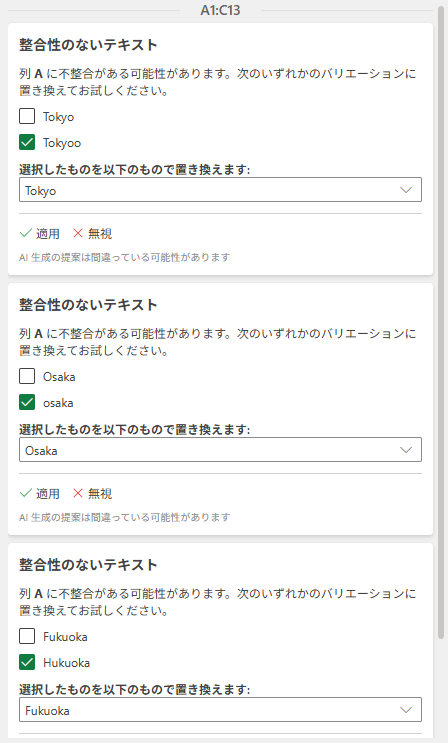
指摘されている枠にマウスポインタを合わせると、該当するセルの色が変わります。
「Tokyoo」のチェックボックスがオンになっているのは、これが異常では?と認識している意味です。この「Tokyoo」を[選択したものを以下のものに置き換えます:]で指定している「Tokyo」に置き換えてはいかがですか?と言っています。その下の[レ適用]をクリックすると「Tokyoo」が「Tokyo」に置換されます。[×無視]は、今回の修正では無視をするということで、今後一切無視されるわけではありません。次回にチェックすると、また指摘してきます。
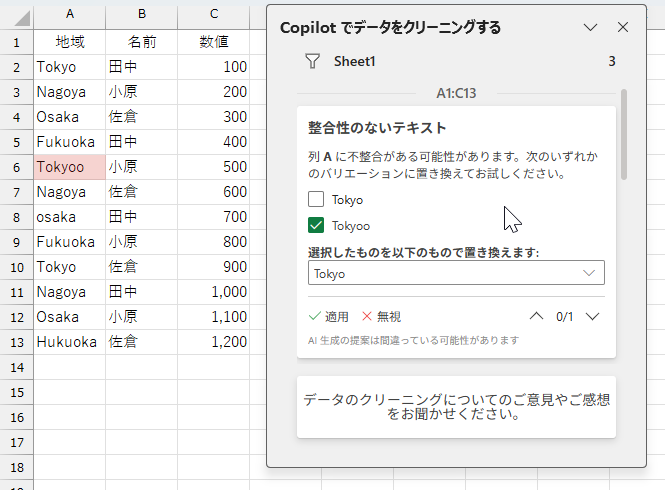
「0/1」というのは、怪しい候補が1つあり、まだひとつも修正していない、ということです。もし、AIが判断した修正候補が複数あると、次のように表示され、「0/2」の両脇にある矢印ボタンで該当セルを切り替えられます。
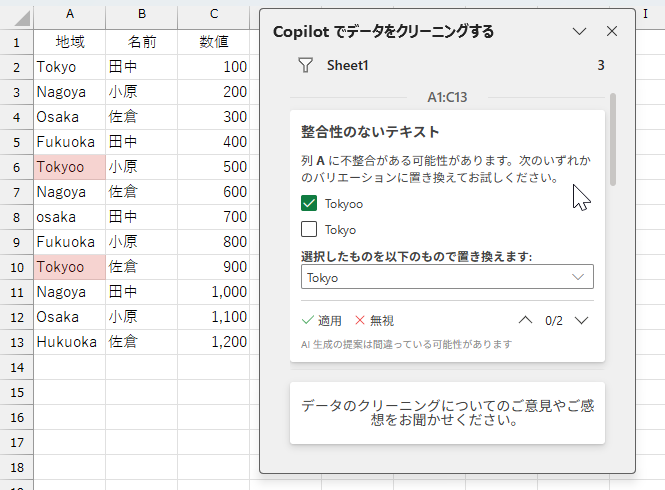
上記動作を検証中に気づいたのですが、「Tokyo」が1個に対して「Tokyoo」が2個あったので、「Tokyoo」の方が正しいと認識されました。これ以外にも「Osaka⇔osaka」「Fukuoka⇔Hukuoka」も検知されました。記号的なのは、どうでしょう。
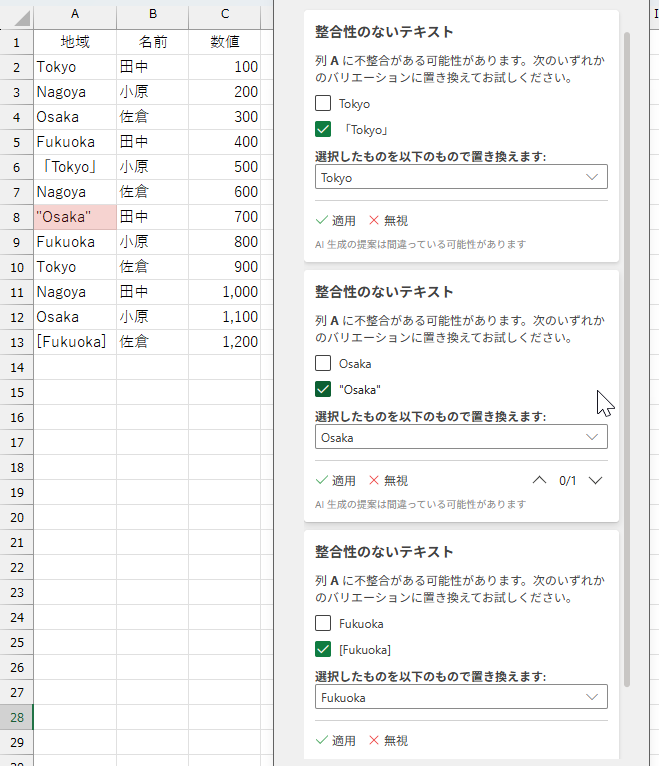
いけますね。ちなみに、サイドペインを開いて、チェックの結果を表示しているときにセルを編集し、検査結果に変化が生じると、次のように教えてくれます。
ヘルプには「現在は英語のみに対応」みたいな表記もありましたが、こうした"揺れ"や"ブレ"で日本語の誤変換をチェックするのは難しいと思います。たとえば「斉藤⇔齋藤」「田辺⇔田邊」「高橋⇔髙橋」「種崎⇔種﨑」「田中⇔田仲」などは、一概に"揺れている"とは言い切れません。正しいかもしれないです。ひらがなとカタカナの混在も同様です。そう考えると、やはり英字や記号などのチェックに有用な仕組みではないかと。
余分なスペース
これも実務では超あるあるですね。文字列に「空白(スペース)が混在している」ケースです。何しろ空白(スペース)は表示されないため、位置によっては判別できないケースも多いです。さて、今回ご用意したのは、次のようなデータです。
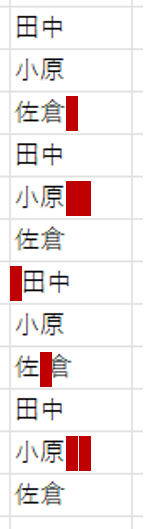
上から3件目の「佐倉 」は後ろに半角スペースが1個あります。5件目の「小原
」は後ろに半角スペースが1個あります。5件目の「小原 」は全角スペースです。7件目の「田中」は前に半角スペース、9件目の「佐倉」は文字の間に半角スペース、そして最後の11件目「小原 」は末尾に半角スペースを2個入れました。さて、検査結果は次のとおり。
」は全角スペースです。7件目の「田中」は前に半角スペース、9件目の「佐倉」は文字の間に半角スペース、そして最後の11件目「小原 」は末尾に半角スペースを2個入れました。さて、検査結果は次のとおり。
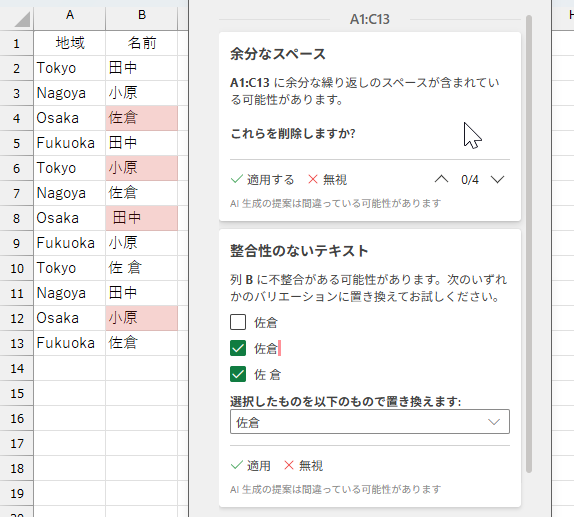
この結果から分かることが3つあります。1つめは「文字の間に挟まれている空白(スペース)は、余分なスペースとは認識されない」ということ。余分なスペースとして認識し修正を促しているのは4つのセルです。「佐倉」は余分なスペースが含まれているのではなく、それはそれで3文字のデータと認識しているらしいです。2つめは「余分なスペース」が混在している場合でも、それが「一貫性のないテキスト」だと認識されるケースがあるということ。3つめは、ちょっと不思議なんですが、「佐倉」「佐倉」「佐倉」の3つは、まとめて同じテキストなのではないかと。そして、それらに一貫性がないのではないかと、そう判断したようですが、でも「小原」「小原 」は、一貫性のない同じテキストとは認識していないようですね。「小原」パターンがないとダメなのでしょうか。なお「余分なスペース」の「レ適用」をクリックすると「佐倉」を除くすべてのスペースが除去されました。
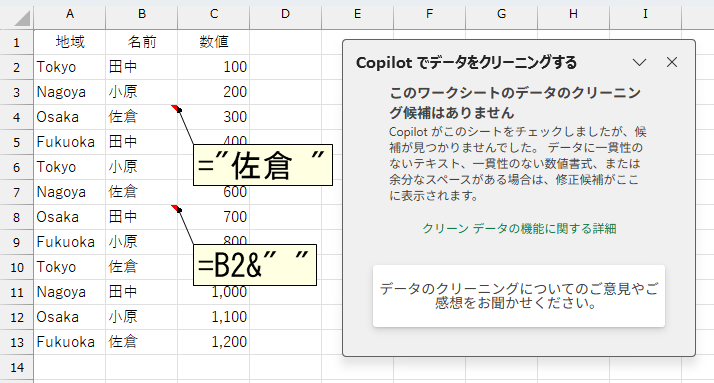
このミスって、意外と多いのではないかと思います。何かチェックする方法はあるのかな?
一貫性のない数値形式
最後は「一貫性のない数値形式」です。これは要するに、同じ列の中に純粋な数値と、文字列形式で入力された数値が混在していないかを調べる機能です。まずは、分かりやすいケースから試してみましょう。
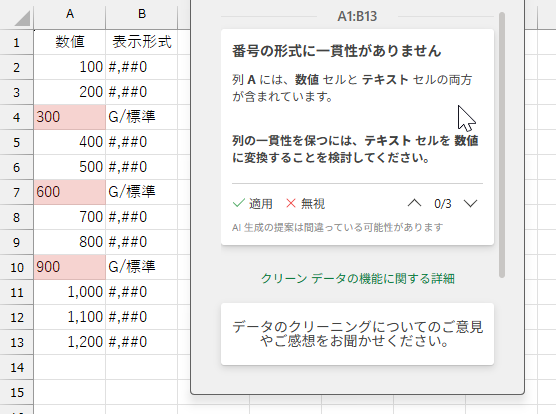
3つはすべて「'300」「'600」「'900」のように、シングルコーテーションをつけて入力しました。B列の「表示形式」とは、A列に設定している表示形式です。別のパターンも試してみましょう。
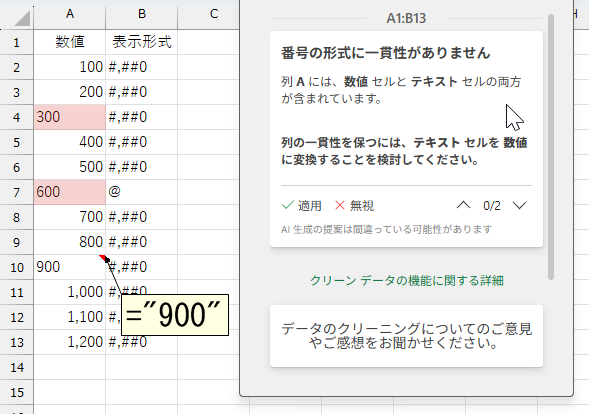
セルA3は変わらず「'300」と入力してありますが、表示形式に他と同じ「#,##0」を設定してみました。正しく「文字列形式である」と検知されていますので、表示形式は考慮されないと分かります。次にセルA7ですが、こちらはまず表示形式で「文字列」を選択し、そこへ普通に「600」と入力しました。シングルコーテーションはつけていません。入力したのは純粋な「600」ですが、表示形式が文字列になっているので検知されたようです。さて、最後のセルA10ですが、ここには数式で「="900"」と入力しました。表示形式は他と同じ「#,##0」です。結果は検知されませんでした。つまり、数式の結果が文字列になっているセルは検知されないということですね。
ということなのですが、この「一貫性のない数値形式」というのは、他の「一貫性のないテキスト」「余分なスペース」に比べて、ちょっと動作に疑問があります。たとえば、下図のように新しいテーブルを作ります。
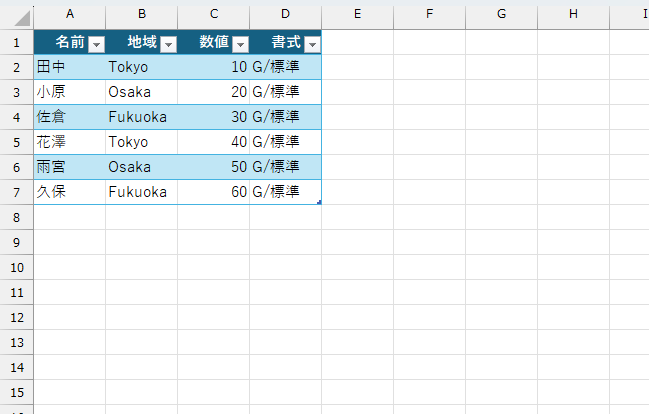
このテーブルには、何も問題がないので「データのクリーニング」を実行しても検知されません。
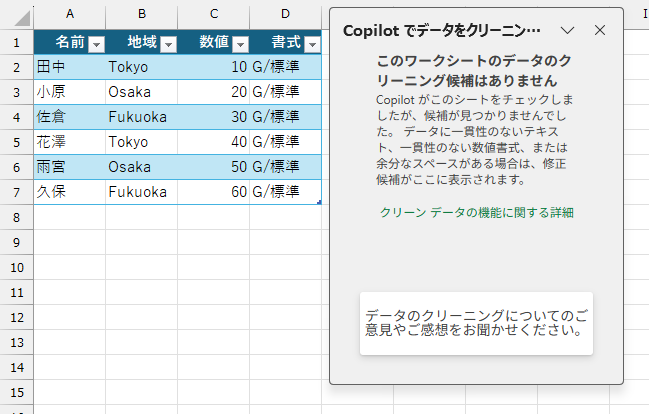
では、いくつかの数値を文字列形式にしてみます。
しばらく待っても、Ctrl + Sで上書き保存しても「更新」されません。一度サイドペインを閉じて、再び「データのクリーニング」を実行しても検知されません。では、このブックを一度閉じて、開きなおしてみます。
状況は同じです。では、表示形式を「文字列」にしていたセルを「標準」に戻し、セルには「'20」のようにシングルコーテーションを付けてみます。
上書き保存したり、開きなおしたり、「データのクリーニング」を手動で実行しても変わりません。まったく検知してくれません。実は、上記の動作解説は「何とか検知してくれる状況」を再現して、苦労して書きました。間違いなく検知してくれる要因は存在するはずですが、しないときもあります。どうもよく分かりません。その要因が何なのかはともかく、今回新しいブックに新しいテーブルを作り、あえて文字列形式の数値を入力したのですから、ここは検知して欲しいところです。変なことは一切していないのですから。現時点では、こういうこともあるようです。
最後の「一貫性のない数値形式」に関しては、ちょっと再現が難しいのですが、他の2つは、かなり実務で役立つはずです。特に「余分なスペース」は視認できないので、チェックしてくれる機能は嬉しいですね。