画像からデータを読み込む
画像データをOCRのように処理して、ワークシート上に読み込む機能です。[データ]タブ[データの取得と変換]グループにありますが、Power Queryとは関係のない機能です。また「ネットに接続していないと使えない」ことや「処理中の画面」からも、AIを使っているのが分かります。
これは数年前、Android版のExcelアプリで実装されました。現在では、iPhone版Excelアプリでも使用可能かもしれません。すみません、確認していません。たとえば出先で、紙に印刷された資料を渡されたと。その紙をスマホで撮影して、Excelにデータとして読み込む、という使い方を想定したのだと思われます。今では、Windows版デスクトップアプリのExcelでも使えます。画像ファイル形式は「jpg」「png」「bmp」「gif」など豊富な種類に対応しています。

なお本稿では、実際に紙を撮影するのは面倒くさいので、パソコンの画面をキャプチャして、画像形式で保存したファイルで試します。まず、簡単なケースでやってみましょう。
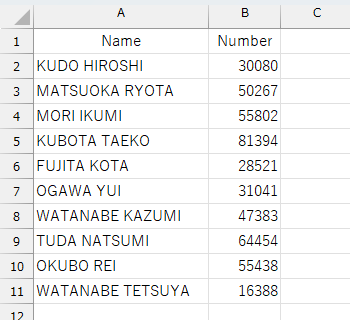
このデータをキャプチャしたのが、こちらになります。
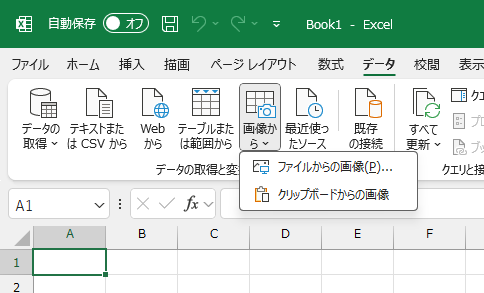
[データ]-[画像から]-[ファイルからの画像]を実行すると、Excel画面の右に、下図のようなサイドペインが表示されます。
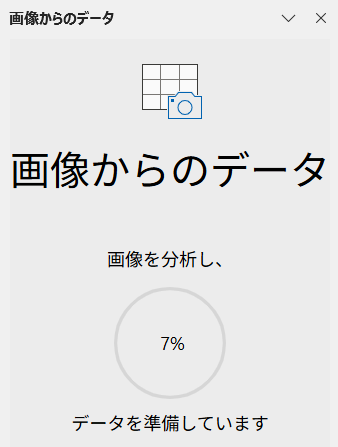
分析が終了すると、次のような画面が表示されます。
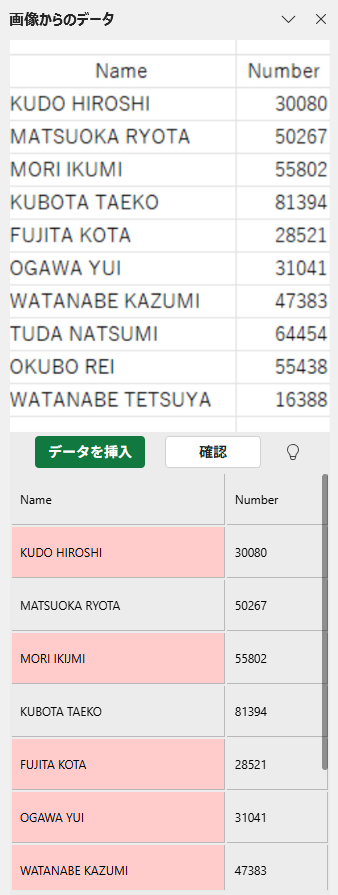
ここで、誤って認識されたデータを編集して修正できます。今回は何も修正せずに[データを挿入]ボタンをクリックします。
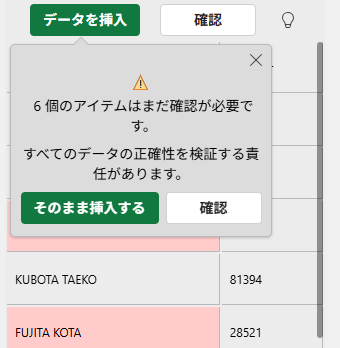
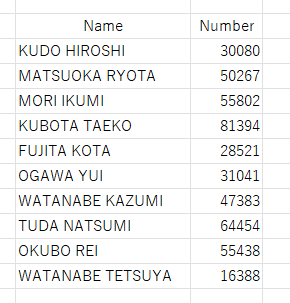
アラートを無視して[そのまま挿入する]を実行します。にしても「正確性を検証する責任があります」とか言われてもねw そりゃ、使っている私たちに責任があるのは承知していますけど。ま、いいや。実行結果は下図のとおりです。1行目のヘッダは、見やすくするため中央揃えにしました。
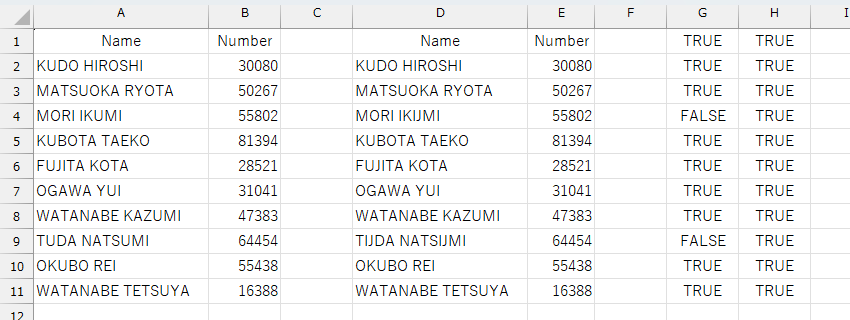
A列とD列が等しいかどうか、そしてB列とE列が等しいかどうかを、G列とH列で比較してみました。数値は問題ありませんが、アルファベットが2カ所異なっているようです。念のため、[Name]列の文字数を比較してみましょう。
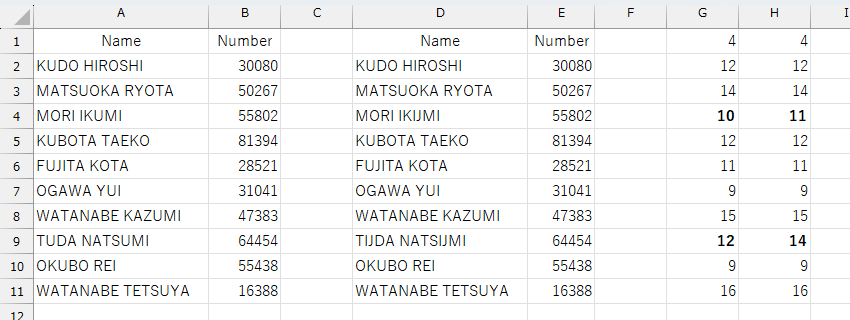
確かに、正しく読み込まれていないようですが、どうです?パッと見て分かりますか?実は、読み込んだデータは次のようになっています。

アルファベットの"U"が、"I"と"J"の2文字と認識されていますね。さて、次は日本語です。
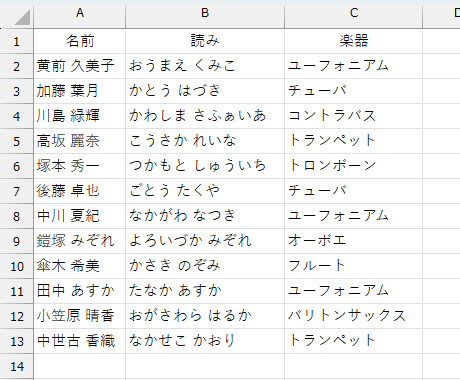
作成した画像は、こちら。
このデータに関してはですね。どこが間違ってる、とかってレベルじゃありません。ありのまま 今起こったことを見せるぜ!
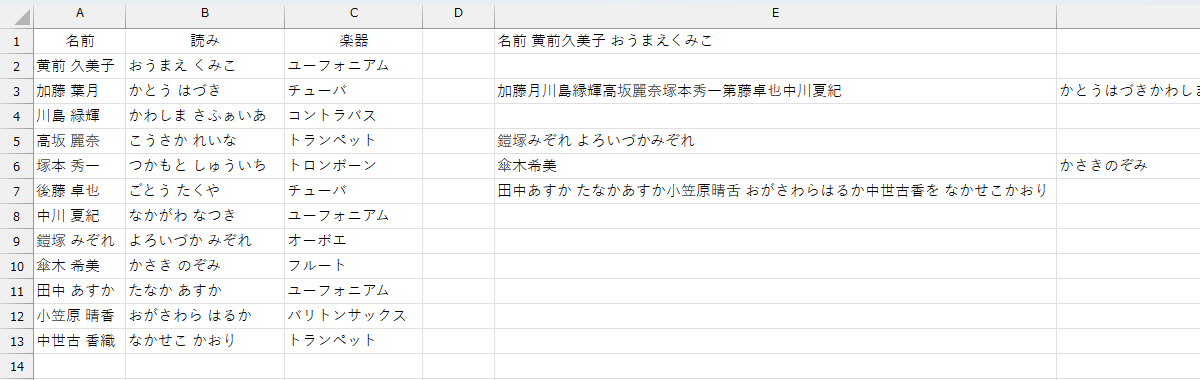
な…何が起こったのか わからねーと思うが、私も何をされたのか分かりません。まるで「ザ・ワールド」です。
漢字やひらがななどの日本語が認識できないという前に、まず列を認識できませんでした。しかも、百歩譲ってヘッダが「名前 読み 楽器」とつながってしまったのなら、まだ分かりますが「名前 黄前久美子 おうまえくみこ」ですからね。これ仮にセルのアドレスでいうなら「セルA1 セルA2 セルB2」です。何度か試してみましたが、列を認識できないって現象は、何度も起こりました。一応、漢字だけの1列だけで試してみましょうか。
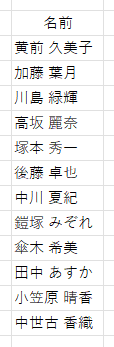
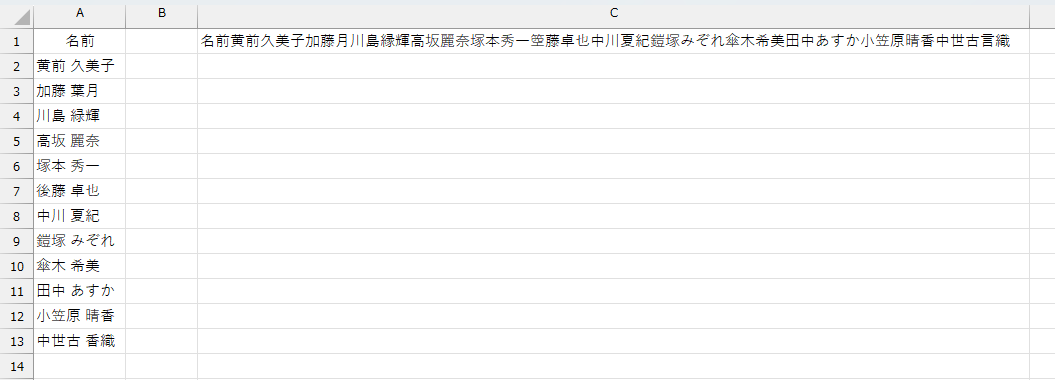
う~む、手強いですね。しかたないので、手で編集してみます。漢字の誤りを見たいので、文字をそのまま区切ります。
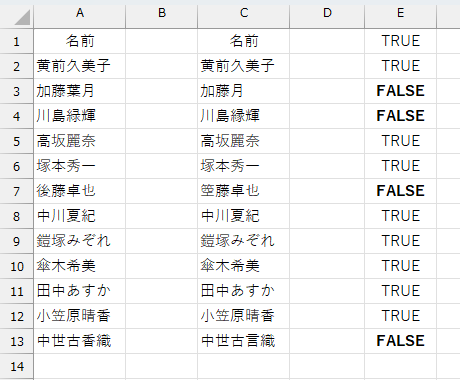
文字の確認をしやすいように、A列の半角スペースは除去しました。
3行目:加藤葉月 → 加藤月
7行目:後藤卓也 → 箜藤卓也
13行目:中世古香織 → 中世古言織
は、分かりやすいですが、4行目のサファイア川島は、何が違うのでしょう。図を拡大してみます。

これでも、よく分からない方のために、1文字ずつ比較してみました。
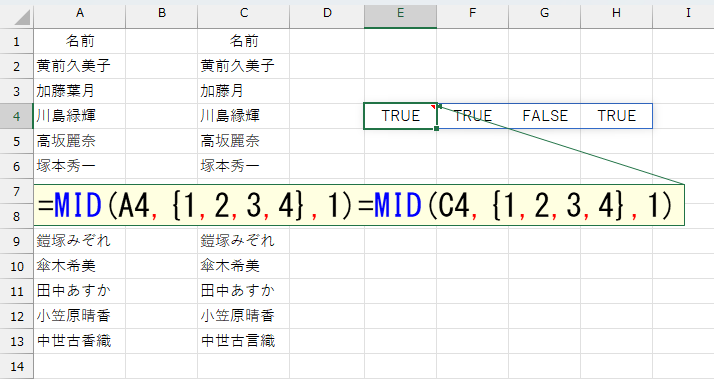
3文字目だけ抜き出します。

「みどり」と「えん」ですね。まぁ、間違えやすい字ですもんね。
以下は想像です。この「画像からデータを読み込む」で、どんなAI的な判断が使われているのかと。もちろん、文字を認識する部分にも使われているでしょうけど、それだけでなく「1つのデータを認識」するところだと思います。Excelでしたら、セルという枠に入っているのが1つのデータです。じゃ、もしセルの枠線がなかったら。上下はともかく、左右の境目って判断するの難しくないですか?

上図のようなデータがあったとき、これって「100」と「田中」という2列のデータですか?それとも「100 田中」という1列のデータですか?どっちも、あり得ますよね。こういうデータの区切り的な判定を、AIでやっているのではないかと思います。何しろ欧米などでは、ほとんど罫線を引きませんからね。特に縦線で区切ったリストって、あまり見たことがありません。先ほど読み込んだ画像では、一応セルの枠線が薄い灰色で引かれています。だから「これはセルだ!囲まれているのがデータだ!」って機械的に判断するのなら、何もAIを使うまでもないのではないかと。なので、枠線の色をもっと濃くハッキリとしてみました。先ほど散々な目にあった北宇治高校吹奏楽部のリストを、もう一度試してみます。
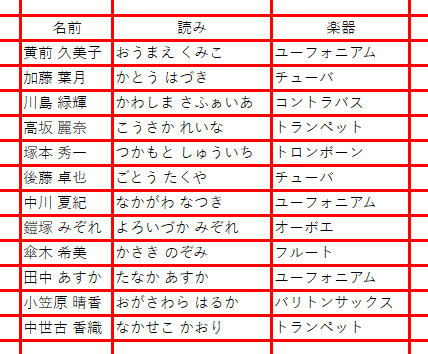
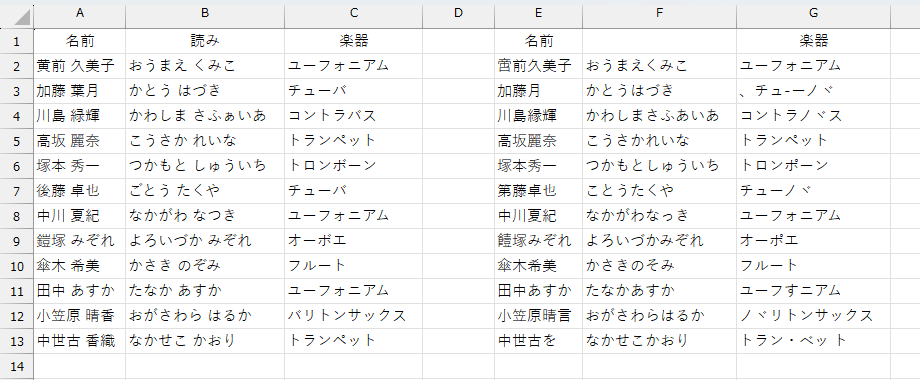
いかがでしょう。まだツッコミどころはありますが、最初のように、すべて1行と認識されちゃうようなヒドイ状態にはなっていません。にしても、カタカナはヒドイですねw このデータに限って言えば、ひらがな>漢字>カタカナ という精度でしょうか。
AIを使っているのは間違いありません。であれば、今後ここで使われているAIが、さらに進化する可能性は大いに考えられます。今後に期待ですね。しばらくしたら、また試してみます。