すべての列が同一なデータ
先日のセミナーで、常連の高橋さんから質問されたやつです。UNIQUE関数を使って「重複しているデータ」を調べられないかと。そのときは「後で解説しますね」と言っておきながら、時間の関係で伝えられなかったので、こちらで解説します。ちなみに、けっこう難しいので覚悟してくださいね。まずは前提としてUNIQUE関数の動作から。
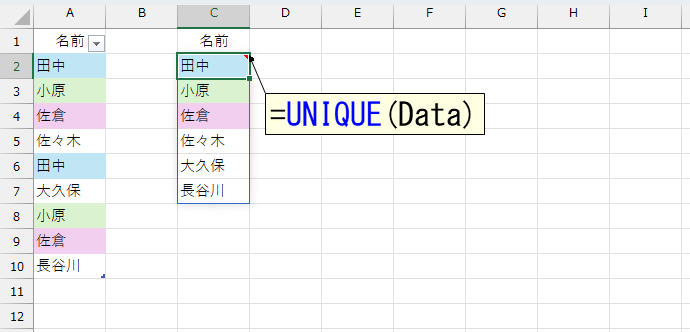
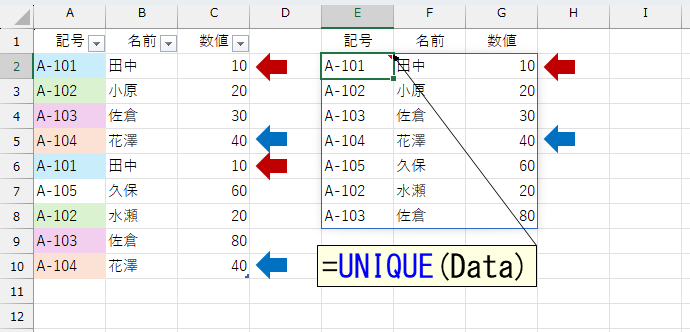
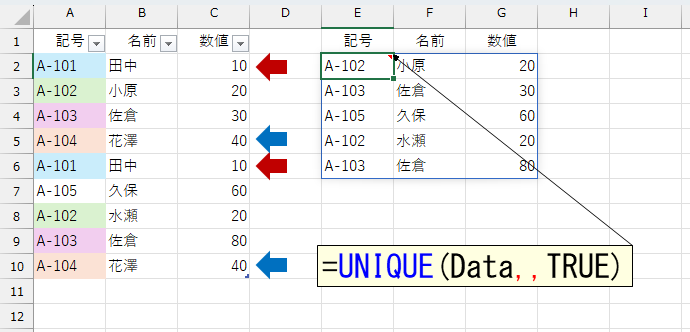
A列の元データは、テーブル「Data」です。上図のように、UNIQUE関数をシンプルに使うと「重複しているデータは"1つとして"」抽出してくれます。なお、UNIQUE関数の第3引数にTRUEを指定すると「純粋に"1回しか登場しない"データ」を抽出します。
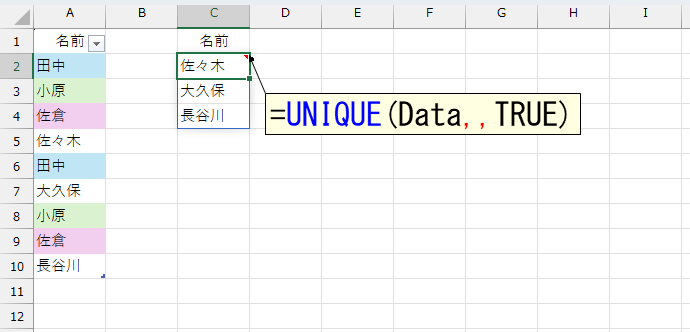
UNIQUE関数だけで、この2つのデータを取得できます。では「田中」「小原」「佐倉」など、"重複している"データを調べるには、どうしたらいいでしょう。
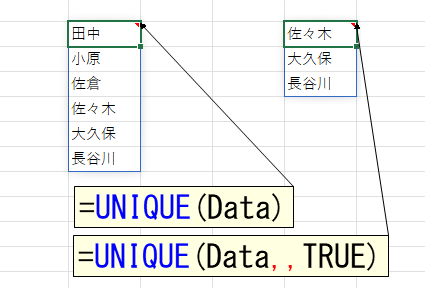



上図のように、左側リストの各データに対して「ある or ない」のような区別ができれば、あとはそれを使ってフィルタすることで、何とかなりそうですね。セル範囲の中で、何かを探すといえばMATCH関数です。
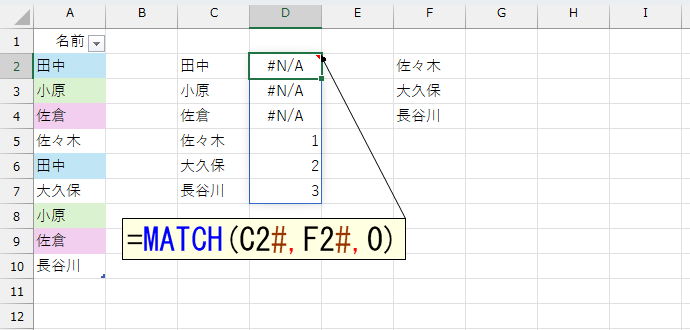
このあとでFILTER関数を使います。FILTER関数の条件はTRUEまたはFALSEです。今回は「エラーだったらTRUE、そうでなければFALSE」に変換します。
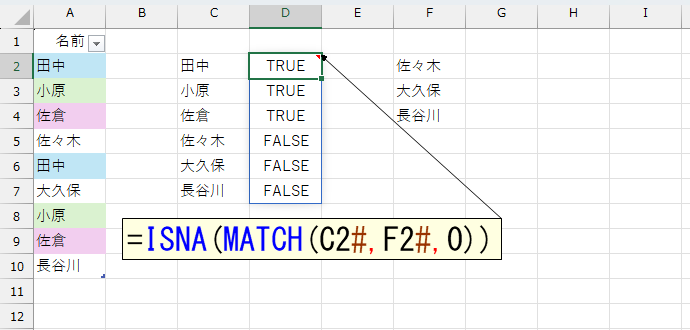
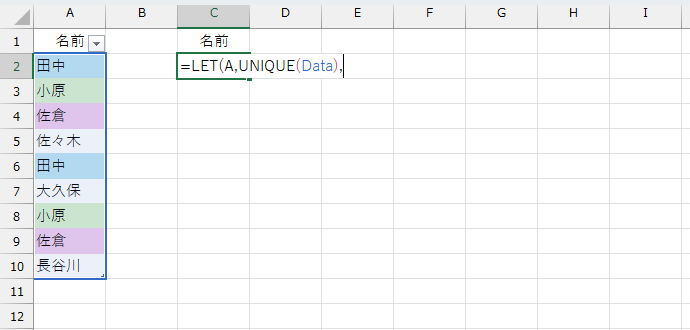
これでいけそうです。数式を作っていきましょう。おそらく数式が長くなると予想されますので、LET関数を使いましょう。まず「重複しているデータは"1つとして"」抽出したリストを変数に入れます。ここではAとしました。
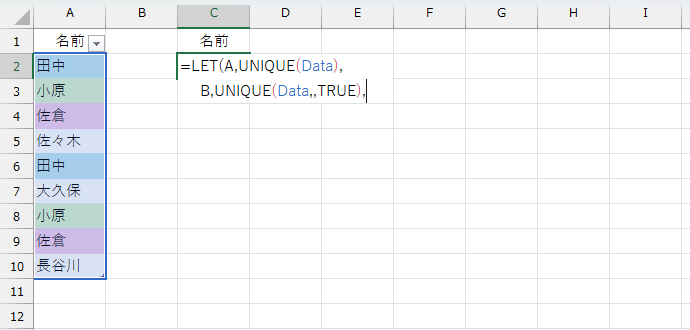
同様に「純粋に"1回しか登場しない"データ」を変数Bに入れます。
存在を確認するためにMATCH関数を使います。MATCH関数の結果を変数Cに入れます。
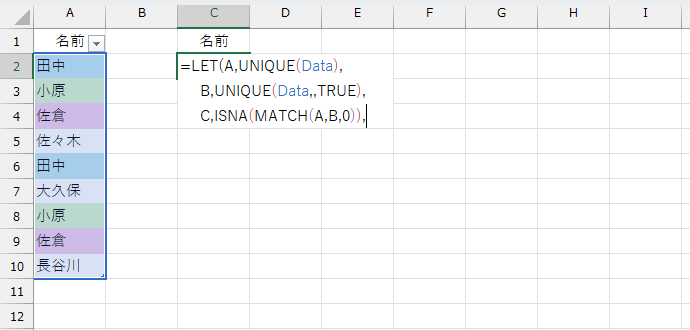
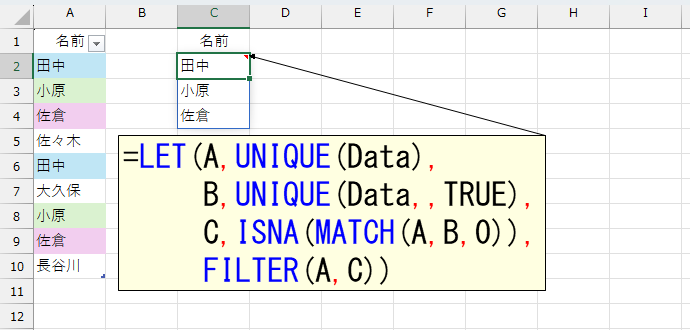
最後にFILTER関数でフィルタリングします。
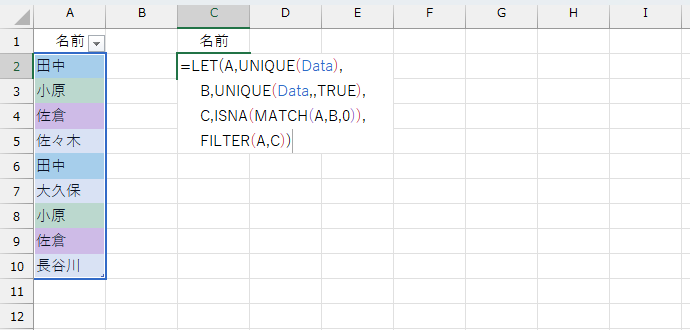
=LET(A,UNIQUE(Data),
B,UNIQUE(Data,,TRUE),
C,ISNA(MATCH(A,B,0)),
FILTER(A,C))
別のやり方
本稿を書くにあたり流れを整理していたとき、ふと他の方法も思いつきました。なので、そちらもご紹介します。どちらがいいではなく、両方思いつくのがベストです。なお、どちらが難しいかは、その人のExcelスキルによるかもです。
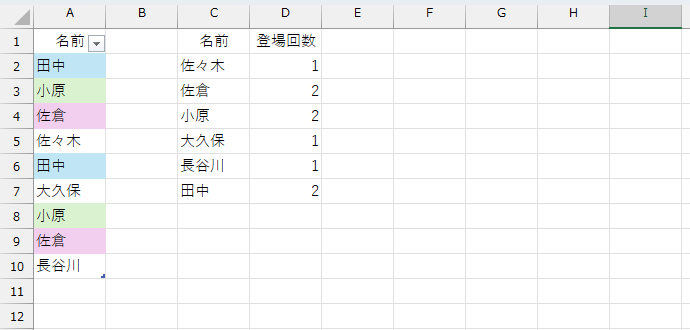
もし、上図のような"登場回数"のリストがあったらどうでしょう。[登場回数]が"1より大きい"ものが、重複している名前です。これは、FILTER関数で一発ですね。だったら、上図のようなリストを作成できれば事件解決です。カンの良い方ならお分かりでしょう。こうしたリストはGROUPBY関数で作成できます。
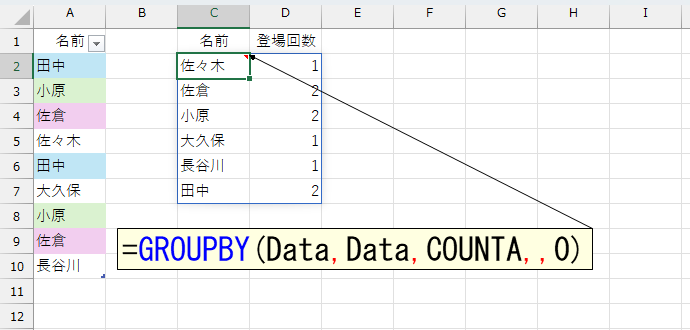
UNIQUE関数を使う方法に比べて、ここまでは簡単です。ただし、このGROUPBY関数を使うやり方では、フィルタをかけるのが"左端の1列"であり、条件に指定するのが"右端の1列"です。そう、GROUPBY関数の結果から、列を抽出しなければなりません。このへんが、人によっては難しく感じるのでは。列の抽出には、CHOOSECOLS関数やINDEX関数などが使えそうですけど、ここではTAKE関数を使いましよう。余談ですが、私はよく、CHOOSECOLS関数よりもTAKE関数を使います。理由は、関数名が短くて楽だからですw
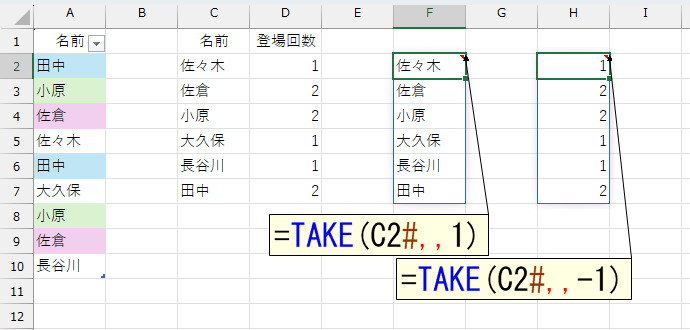
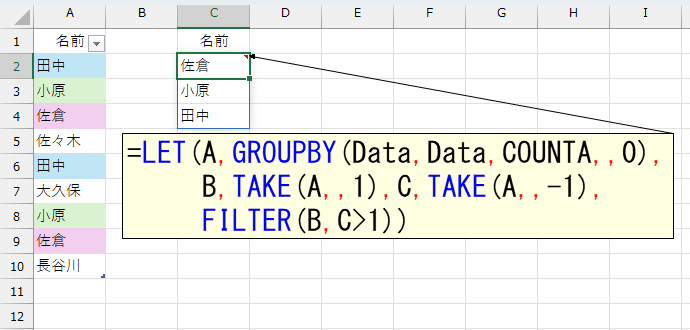
=LET(A,GROUPBY(Data,Data,COUNTA,,0),
B,TAKE(A,,1),C,TAKE(A,,-1),
FILTER(B,C>1))
本題はこっから
さてさて、本稿のタイトルを思い出してください。「すべての列が同一なデータ」です。"すべての"ってことは、もちろん"複数列"ということです。上記のように、1列だけのデータでしたら簡単です。ですが、実際の質問は次のようなケースでした。
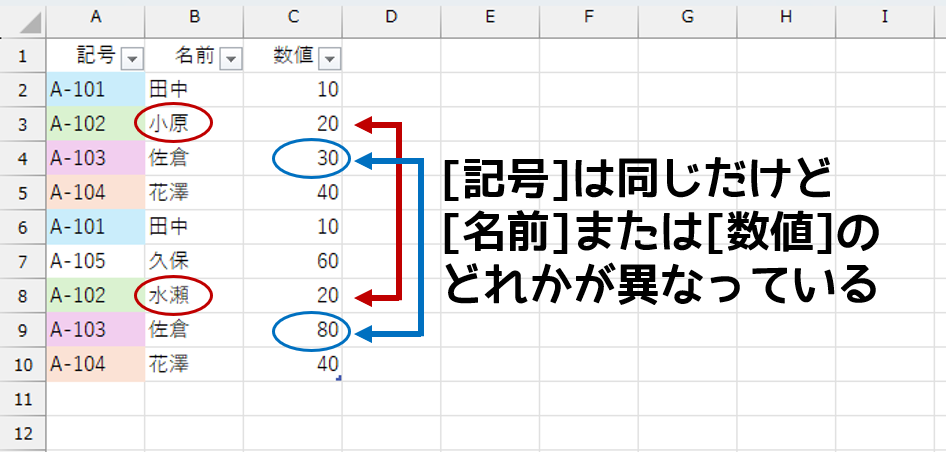
[記号]の「A-102」と「A-103」は重複しています。でも、[名前]または[数値]が異なっています。これはOKなんです。これらは[記号]が重複しているとはいえ、それぞれ有効なデータなんですと。
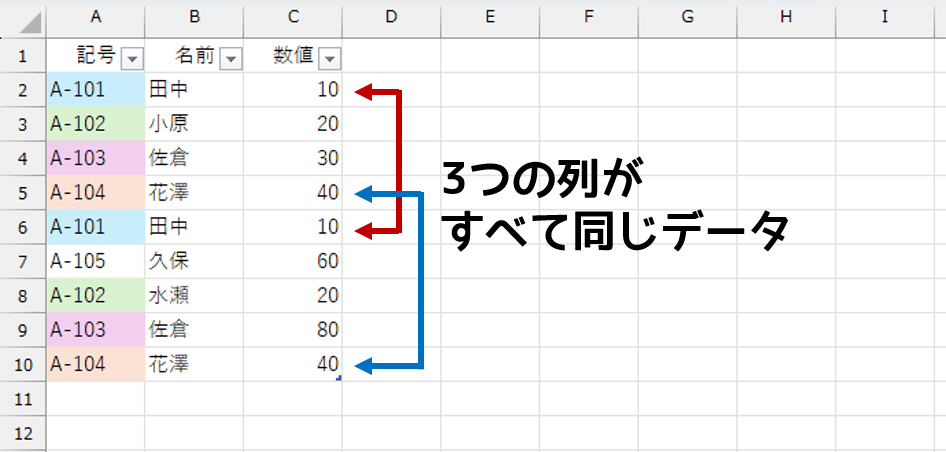
対して「A-101」や「A-104」のように、[記号][名前][数値]の3列がすべて同じというのはNGです。それらは重複して入力されたのかもしれません。そのように「すべての列が同一なデータ」だけを調べたいんですと。そういうリクエストでした。こうなると難易度が上がりますね。
実は、UNIQUE関数は複数列を指定することもできます。
複数列を指定すると、すべての列で重複していないデータだけを抽出できます。あるいは先のように、UNIQUE関数の第3引数にTRUEを指定することで「すべての列が純粋に"1回しか登場しない"データ」も調べることができます。
このへんを使えば、似たよう発想でいけるんじゃないかと考えました。でもね、これがけっこう難解なんですわ。セル単位でフィルタするなら簡単ですけど、行単位で何かしようとすると苦戦します。それに、実際のデータって、おそらくこんな小さいリストじゃないだろうし。な~んて悩んだ結果、とりあえずできましたのでご紹介しますね。とはいえ、正直ちょっと不本意です。もしかすると、もっと美しいやり方があるかもしれません。まぁ、それほど時間もかけていられませんし、今回は"パッと思いついた方法"ということで。
繰り返しますが、1列だけのリストだったら簡単なんです。だったら、複数列のリストを1列だけのリストに変換しちゃいます。このへんが、ちょっと"逃げ"ですね。たとえば2行目の「A-101」「田中」「100」を1つの値にするには、この3セルを結合してやります。ただし、ただ結合すると値どうしがくっついてしまいますので、間に何らかの記号を入れます。たとえば「A-101,田中,100」みたいに。こうした変換を行うとき、みなさんは何の関数をイメージしますか?TEXTJOIN関数を想定した方が多いのでは?もちろんTEXTJOIN関数でもできますけど、TEXTJOIN関数って、ちょっと面倒くさくないですか?引数の並びが、どうも好きになれませんw こんなときは、もっとシンプルな関数があります。それはARRAYTOTEXT関数です。
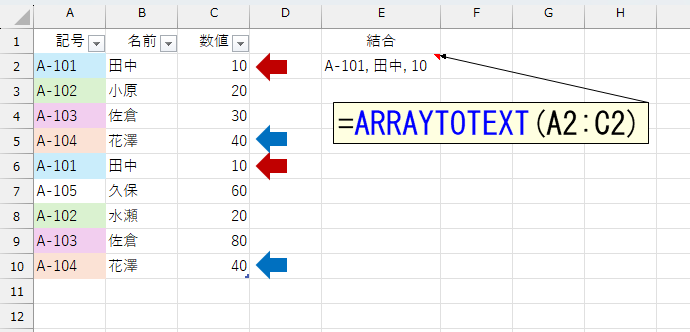
ARRAYTOTEXT関数は、割と最近になって追加された関数なので、馴染みのない方が多いのでは。それに今回は、別にどんな区切り記号でもいいのですから、わざわざTEXTJOIN関数で指定する必要もありません。元データから1行ずつ取り出して、それをARRAYTOTEXT関数で結合します。元データから1行ずつ取り出すのはBYROW関数です。もちろん、LAMBDA関数とVSTACK関数も使います。
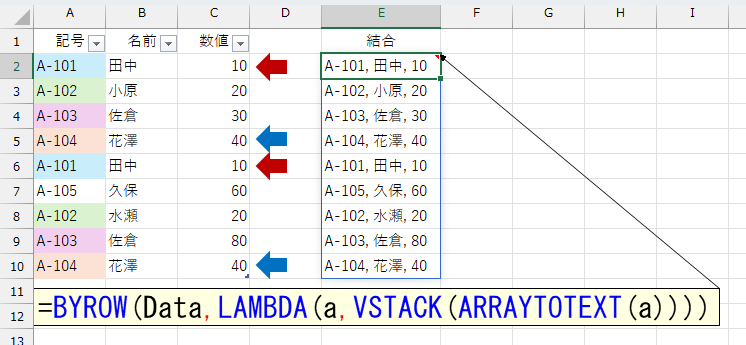
ここまでできれば、あとは「1列だけのリスト」と同じです。UNIQUE関数を使う方法とGROUPBY関数を使うやり方を解説しましたけど、ここでは(特に意味はありませんが)GROUPBY関数でやってみましょう。
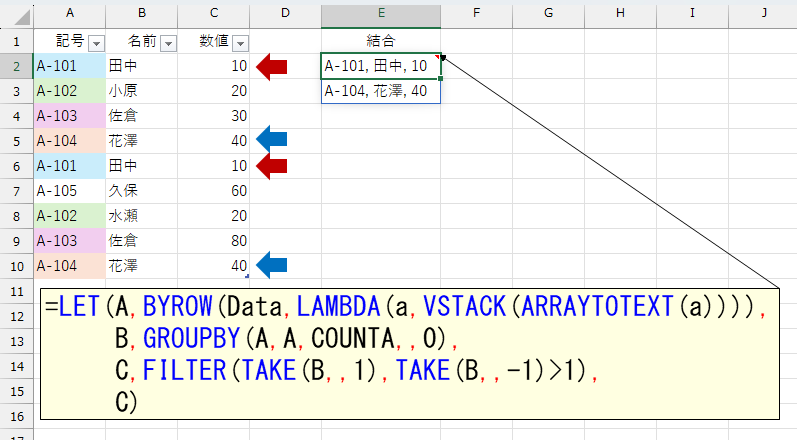
上図は途中経過です。最後に、この結果をTEXTSPLIT関数で分割します。ARRAYTOTEXT関数の区切り文字は「,」だけではなく「, 」みたいにスペースが含まれますので注意が必要です。
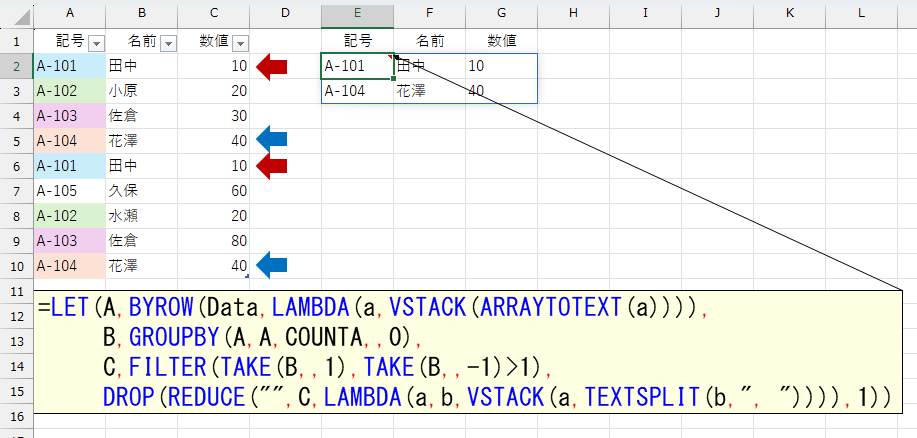
=LET(A,BYROW(Data,LAMBDA(a,VSTACK(ARRAYTOTEXT(a)))),
B,GROUPBY(A,A,COUNTA,,0),
C,FILTER(TAKE(B,,1),TAKE(B,,-1)>1),
DROP(REDUCE("",C,LAMBDA(a,b,VSTACK(a,TEXTSPLIT(b,", ")))),1))
かなり複雑になっちゃいましたね。なんか、もっとスマートは方法はないかな?そのうち、時間があるときにでも考えてみます。